Práctica 3
Anuncio

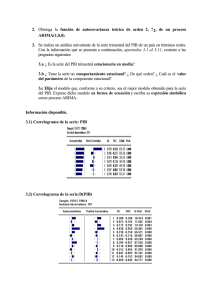
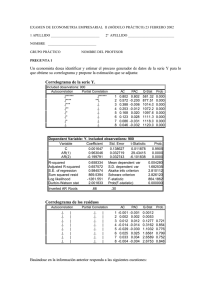
PRÁCTICAS DE LA ASIGNATURA ECONOMETRIA II. CURSO 2009/2010 Práctica 3 Planteamiento y objetivos de la práctica En la presente práctica se propone la modelización univariante por medio del enfoque de Box-Jenkins de tres series temporales con características distintas. En cada uno de los ejemplos propuestos hay distintos pasos a detallar, pero con el fin de ver los tres ejemplos en la sesión práctica, cada profesor puede realizar los que considere más importantes en cada ejemplo y dejar los pasos omitidos para que los cubran los alumnos después por su cuenta. Con la presente práctica se intenta que el alumno aprenda a construir modelos ARIMA univariantes para una serie temporal por medio del enfoque de Box-Jenkins. La aplicación de esta metodología conlleva recorrer diversas etapas hasta elaborar el posible modelo generador de los datos. De forma sintética los pasos a realizar son los siguientes: • Especificación inicial • Estimación • Chequeo o validación • Utilización del modelo 1 En la etapa de especificación inicial se deberá determinar el orden de integración de la serie temporal, es decir cual es el número y naturaleza (regular o estacional, incluyendo trimestral, mensual, etc.) de diferencias que se requerirán para convertir en estacionaria a la variable objeto de análisis, Zt (d,s). Zt = (1-B)d (1-Bs ) D 1 El modelo puede utilizarse, por ejemplo, para predecir, para describir las propiedades del fenómeno económico en cuestión en cuanto a su tendencia, estacionalidad, oscilaciones (cíclicas) estacionarias, impredecibilidad, para basar sobre él la extracción de señales como el componente estacional, etc. 2 Donde: d es el número de diferencias regulares y D es el número de diferencias de tipo estacional y habitualmente D = 0 ó 1 y habitualmente 0 ≤ d+D ≤ 2. Para ello se utiliza tanto el análisis gráfico de la serie, que nos revela determinadas características de la misma, como sus correlogramas simple y parcial y los tests de raíces unitarias. En esta práctica nos centramos en el test de raíces unitarias de Dickey y Fuller aumentado (ADF o DF simplemente). Una vez decidido el orden d y D, es decir el número de raíces unitarias que tiene la serie temporal, habrá que decidir el orden del polinomio autorregresivo (p) y el de medias móviles (q) para lo cual utilizamos como principales instrumentos el correlograma simple y el parcial de la serie. Los criterios generales que deben servir de guía para determinar el orden p del polinomio autorregresivo y el orden q del polinomio medias móviles se recogen en las estructuras de los correlogramas simple (FAC) y parcial (FAP) y que para los casos más sencillos se han visto en las clases teóricas. Un resumen de las características de la estructura del correlograma simple y del parcial se recoge en el esquema adjunto. Características teóricas de la FAC y de la FAP de los procesos estacionarios Procesos FAC FAP Decrecimiento rápido hacia AR (p) cero sin llegar a anularse MA (p) ARMA (p, q) P primeras autocorrelaciones distintas de cero y el resto ceros q primeras autocorrelaciones Decrecimiento rápido hacia significativas y el resto ceros cero sin llegar a anularse Decrecimiento rápido hacia cero sin llegar a anularse Decrecimiento rápido hacia cero sin llegar a anularse Debe quedar claro que la identificación es siempre tentativa por lo que se deben sugerir varios modelos como posibles procesos generadores de datos. Una vez que se han sugerido uno o varios modelos se procede a su estimación, 3 usualmente por máxima verosimilitud aunque en Eviews este método no está implementado. Posteriormente se debe realizar el chequeo ó validación del modelo y escoger el que parezca más adecuado para la utilización del modelo. Algunos de los criterios de validación del modelo más importantes incluyen el análisis de la autocorrelación y de valores atípicos de los residuos, la significatividad de los parámetros estimados del modelo (así como sus correlaciones), las condiciones de estacionariedad e invertibilidad y distintos criterios de ajuste (como el error estándar de la regresión, el de Akaike o el de Scharwz). En esta práctica se realiza la modelización de tres series temporales de datos reales y características distintas. El primer caso se refiere al volumen de ventas anual de una empresa en términos reales, el segundo analiza el Índice de empleo de un determinado país con frecuencia trimestral y en el último se modeliza una serie de frecuencia mensual y con estacionalidad, las ventas de cigarros puros de una empresa tabaquera. Ejemplo1. Ventas anuales de una empresa La serie que se modeliza se refiere a las ventas en términos reales de una determinada empresa dedicada a la producción de cosméticos. Su periodicidad es anual y el tamaño muestral abarca 51 observaciones que comprenden el periodo 1949-1999; dada su frecuencia anual, esta serie no tendrá componente estacional. El primer paso que debemos dar para elaborar el modelo univariante de las series es crear en Eviews el workfile con frecuencia anual y tamaño muestral indicado e importamos los datos, tal y como hemos hecho en las prácticas anteriores. La variable la denominamos ventas Una vez cargados los datos debemos verificar si la serie temporal es estacionaria y, en caso de que no lo sea, realizar las transformaciones pertinentes hasta convertirla en estacionaria. Para ello en primer lugar graficamos la serie ventas, gráfico que se muestra a continuación. 4 Las instrucciones en Eviews para obtener el gráfico de la serie son: Quik/Graph /ventas/Line Graph Evolución de las ventas 1200 1100 1000 900 800 700 600 500 50 55 60 65 70 75 80 85 90 95 VENTAS Se observa que tiene una tendencia creciente muy acentuada, lo que es un claro signo de que la serie no es estacionaria en media, además ese crecimiento muestras signos de regularidad por lo que la varianza aparentemente exhibe cierto grado de estabilidad y no es del todo preciso tomar logaritmos. En segundo lugar obtenemos los correlogramas Instrucciones en Eviews para obtener los correlogramas de ventas Quick/Series Statistics/Correlogram/ventas También de forma alternativa en el objeto serie (ventas) View/Correlogram 5 El correlograma simple de ventas (AC) confirma la sospecha anterior sobre la no estacionariedad de la variable ventas al mostrar un decrecimiento muy lento. Adicionalmente llevamos a cabo el test de raíces unitarias de DF. Instrucciones en Eviews para el test DF: Quick/Series Statistics/unit root/ventas Null Hypothesis: VENTAS has a unit root Exogenous: Constant Lag Length: 1 (Automatic based on SIC, MAXLAG=10) Augmented Dickey-Fuller test statistic Test critical values: 1% level 5% level 10% level *MacKinnon (1996) one-sided p-values. Augmented Dickey-Fuller Test Equation Dependent Variable: D(VENTAS) Method: Least Squares Date: 04/11/06 Time: 17:42 Sample (adjusted): 1951 1999 Included observations: 49 after adjustments 6 t-Statistic Prob.* -0.906450 -3.571310 -2.922449 -2.599224 0.7780 Variable Coefficient Std. Error t-Statistic Prob. VENTAS(-1) D(VENTAS(-1)) C -0.001026 0.577317 5.282546 0.001132 0.111009 1.831241 -0.906450 5.200645 2.884682 0.3694 0.0000 0.0059 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat 0.454475 0.430757 1.058424 51.53198 -70.76235 2.399094 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 10.49688 1.402848 3.010708 3.126534 19.16125 0.000001 El Valor del estadístico t (-0.906) es inferior a los valores críticos de la distribución DF por lo que no se puede rechazar la hipótesis de la existencia de una raíz unitaria y, por tanto, la serie ventas no es estacionaria. Como un primer paso para eliminar la tendencia y convertir la serie en estacionaria se prueba con el ajuste de una tendencia lineal determinista a la serie ventas. Para ello, se ajusta una tendencia determinista a la variable ventas del tipo: ventas = c +β t + εt Cuya estimación se presenta a continuación Instrucciones en Eviews para la estimación de la tendencia determinista: Quick /estimate equation Y en la ventana de la ecuación que se abre escribir: ventas c @trend+1 El resultado de la estimación es: Dependent Variable: VENTAS Method: Least Squares Date: 04/09/06 Time: 19:17 Sample: 1949 1999 Included observations: 51 Variable Coefficient Std. Error t-Statistic Prob. C @TREND+1 605.9019 10.39500 1.299179 0.043483 466.3730 239.0563 0.0000 0.0000 7 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat 0.999143 0.999126 4.570939 1023.781 -148.8514 0.109129 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 876.1719 154.5990 5.915740 5.991498 57147.92 0.000000 12 8 4 0 -4 -8 -12 -16 50 55 60 65 70 75 80 85 90 95 VENTAS Residuals Analizando esos resultados podemos observar que la estimación de los residuos presenta un estadístico Durban-Watson próximo a cero, lo que es indicativo de una fuerte autocorrelación de primer orden y de la existencia una raíz unitaria y que, por lo tanto, no cumplen las condiciones para que sean ruido blanco. El gráfico de los residuos la serie ventas también muestra esos problemas y nos indica que los residuos se han mantenido por encima y/o por debajo de la media durante un periodo demasiado largo. Por lo tanto, el ajuste con tendencia determinista no es adecuado puesto que olvida determinadas propiedades importantes de la serie Dado que el procedimiento anterior no es el adecuado, la tendencia es tipo estocástica y utilizamos a continuación el procedimiento de la diferenciación para 8 convertir a la serie en estacionaria. Tomamos la primera diferencia en la serie ventas para lo que generamos la serie de Dventas =ventas-ventas(-1), es decir, transformamos la serie de acuerdo con la siguiente expresión: Zt =(1-B)ventas La representación gráfica de la serie transformada y sus correspondientes correlogramas se muestran a continuación. Primera diferencia de la serie ventas 15 14 13 12 11 10 9 8 7 50 55 60 65 70 75 80 DVENTAS 9 85 90 95 Tanto el gráfico de la serie Dventas como su correlograma indican que la primera diferencia de la serie puede ser estacionaria puesto que oscila en torno a su nivel medio y el correlograma tiende a cero con cierta rapidez. No obstante, se completa este análisis con el test DFA de raíces unitarias que se muestra a continuación Test de D-F Aumentado de Dventas Null Hypothesis: DVENTAS has a unit root Exogenous: Constant Lag Length: 0 (Automatic based on SIC, MAXLAG=10) Augmented Dickey-Fuller test statistic Test critical values: 1% level 5% level 10% level t-Statistic Prob.* -3.777505 -3.571310 -2.922449 -2.599224 0.0057 *MacKinnon (1996) one-sided p-values. Augmented Dickey-Fuller Test Equation Dependent Variable: D(DVENTAS) Method: Least Squares Date: 04/11/06 Time: 21:55 Sample (adjusted): 1951 1999 Included observations: 49 after adjustments Variable Coefficient Std. Error t-Statistic Prob. DVENTAS(-1) C -0.381068 3.942637 0.100878 1.078866 -3.777505 3.654428 0.0004 0.0006 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat 0.232898 0.216577 1.056413 52.45244 -71.19611 2.473364 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) -0.092714 1.193536 2.987596 3.064813 14.26955 0.000445 El test DFA rechaza la hipótesis nula de una raíz unitaria en Dventas puesto que el valor del estadístico t (3,78) supera el valor de los puntos críticos de la 10 distribución DFA. Este resultado corrobora la estacionariedad de la serie Dventas que indican el gráfico y el correlograma de la serie Por lo tanto, de estos resultados la transformación que convertiría a la serie en estacionaria sería: Zt = (1-B) ventas o ventas ∼I (1) Una vez decidido el grado de integración de la serie, es decir, el número de raíces unitarias que tiene, se debe determinar cuales son los posibles procesos ARMA que generan la serie. El análisis de los correlograma de la serie Dventas nos dice que el modelo más claro que puede generar la serie es un AR(2), puesto que el correlograma simple tiende a cero con cierta rapidez y el parcial se anula después del segundo retardo. También se puede sugerir como un modelo alternativo, aunque no tan rotundamente como en el caso anterior, un MA(3) puesto que el correlograma simple se anula después del tercero o cuarto retardo. Por otro lado, de la observación del gráfico de la serie que consideramos estacionaria, D(ventas,1), se observa que su media es distinta de cero, por lo que procede en principio la inclusión de un término independiente. Los modelos sugeridos son: 1.1) ARIMA(2,1,0) : (1-φ1B- φ2B2 ) (1-B) ventas = C+at 1.2) ARIMA(0,1,3) : (1-B) ventas = C+ (1+ θ1B+ θ2B2+ θ3B3)at Un análisis más detallado de la estructura del correlograma podría sugerir algún modelo adicional pero de momento nos quedamos con los propuestos. Estimación 11 Una vez especificados varios modelos alternativos como posibles generadores de la serie se debe proceder a la estimación de los mismos. Para ello en Eviews se deben dar las siguientes instrucciones para estimar los modelos sugeridos. Modelo 1.1: Quick/Estimate Equation/ LS d(ventas,1) c ar(1) ar(2) Modelo 1.2: Quick/Estimate Equation/ LS d(ventas,1) c ma(1) ma(2) ma(3) Los resultados de la estimación de estos modelos se presentan a continuación: Estimación Modelo1.1 Dependent Variable: DVENTAS Method: Least Squares Date: 04/09/06 Time: 19:10 Sample (adjusted): 1952 1999 Included observations: 48 after adjustments Convergence achieved after 3 iterations Variable Coefficient Std. Error t-Statistic Prob. C AR(1) AR(2) 10.11214 0.368149 0.388732 0.616994 0.135783 0.127968 16.38936 2.711310 3.037719 0.0000 0.0095 0.0040 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Inverted AR Roots 0.525916 0.504846 0.979571 43.18014 -65.56936 1.991277 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) .83 10.45896 1.392085 2.857057 2.974007 24.95999 0.000000 -.47 Estimación modelo 1.2 Dependent Variable: DVENTAS Method: Least Squares Date: 04/09/06 Time: 19:02 Sample (adjusted): 1950 1999 Included observations: 50 after adjustments Convergence achieved after 13 iterations Backcast: 1946 1948 Variable Coefficient Std. Error 12 t-Statistic Prob. C MA(1) MA(2) MA(3) 10.43083 0.497157 0.564666 0.632436 0.392970 0.101433 0.097743 0.086339 26.54353 4.901323 5.777057 7.324991 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat 0.557023 0.528133 1.029564 48.76011 -70.31917 2.161780 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) Inverted MA Roots .15-.88i .15+.88i 0.0000 0.0000 0.0000 0.0000 10.57670 1.498800 2.972767 3.125729 19.28094 0.000000 -.79 Una vez estimados los modelos especificados se debe validar dichas estimaciones, es decir, se debe contrastar la adecuación del modelo a los datos, por medio de una batería de tests estadísticos y econométricos vistos en clase y que se encuentran en Eviews en el objeto ecuación. Validación o chequeo En la etapa de validación se presentan tres bloques de análisis: Un primero referente a los resultados de la estimación, un segundo centrado en el análisis de los residuos y, finalmente, un tercero dedicado a la comparación de modelos alternativos. • Análisis de la estimación.- Referente a la significatividad individual de los coeficientes por medio del estadístico t de student pone de relieve que todos los coeficientes del modelo 1 son altamente significativos y también lo son los del modelo 2. En cuanto a las condiciones de estacionariedad e invertibilidad de los modelos estimados, todas las raíces de los polinomios de retardos caen fuera de circulo de radio unidad, ver cuadros anteriores de estimaciones, debe tenerse en cuenta que Eviews muestra la inversa de las raíces, por lo que esas inversas caen todas dentro del circulo de radio unidad. 13 De la observación de los resultados de la estimación se deduce que el modelo 1.1 presenta un error estándar (0,979), ligeramente más bajo que el del modelo 1.2 (1,029) y tanto el estadístico de Akaike como el criterio de Schwarz son inferiores en el primer modelo, 2,857 y 2,974, frente a 2,973 y 3,126 En esta etapa también se suele analizar las correlaciones entre los coeficientes estimados para verificar la posible existencia de multicolinealidad en el modelo. La existencia de multicolinealidad indica una falta de precisión en las estimaciones obtenidas y una cierta inestabilidad de los coeficientes estimados. Para obtener las correlaciones entre los coeficientes se acude su matriz de correlaciones que proporciona Eviews, para ello nos situamos en la ecuación estimada y marcamos lo siguiente: View/Correlation Matrix La ejecución de esta instrucción muestra la matriz de coeficientes de la ecuación estimada. Para el modelo 1.1 se tiene: Matriz de correlaciones del modelo 1 C AR(1) AR(2) C 0.380682 -0.005342 -0.015880 AR(1) -0.005342 0.018437 -0.011620 AR(2) -0.015880 -0.011620 0.016376 Se observa que esa matriz presenta unas correlaciones muy bajas por lo que no muestra indicios de multicolinealidad. Para el modelo 1.2 se puede verificar de la misma forma que tampoco presentan problemas de multicolinealidad. Análisis de los residuos. El siguiente paso dentro del proceso de validación es el análisis de los residuos de ambos modelos. Para ello en el objeto ecuación de Eviews se ofrecen varios contrastes pero nos limitamos al contraste de que los residuos sean ruido blanco, inspeccionando el correlograma de residuos, el estadístico Q de Box14 Pierce y el gráfico de residuos. Para ello, en Eviews una vez dentro del objeto ecuación Instrucciones: View/ Residual Tests/Correlogram-Q-Statistics Los resultados para el modelo1.1 se presentan en la tabla adjunta y se puede contemplar que las autocorrelaciones de los residuos no son significativas y entran dentro de las bandas de confianza, lo que indica que no son distintas de cero. Por su parte, el estadístico Q no muestra indicios de autocorrelación global de los residuos, puesto que el valor de Q estimado para los diferentes ordenes de autocorrelación que se muestran en la tabla adjunta es siempre inferior al punto crítico de la χ2 con los correspondientes grados de libertad y niveles de significación estándar utilizados en el trabajo empírico, lo que nos lleva a rechazar ampliamente la hipótesis nula de autocorrelación global de los residuos. Correlograma de los residuos del modelo 1 Instrucciones Eviews para el gráfico de residuos: View/Actual, Fitted, residuals 15 16 14 12 10 2 8 1 6 0 -1 -2 -3 55 60 65 70 75 Residual 80 85 Actual 90 95 Fitted El gráfico de los residuos también apoya la ausencia de autocorrelación residual, puesto que la gran mayoría de los residuos entran dentro de las bandas de confianza, con excepción del correspondiente al año 1962. Por lo tanto, también muestra claramente que los residuos son ruido blanco. De la misma forma que el análisis llevado a cabo para el modelo 1.1 se puede entrar en el objeto ecuación del modelo 1.2 y verificar que sus residuos son ruido blanco. Comparación de modelos alternativos. Del análisis que se acaba de realizar en los dos apartados anteriores se deduce que el modelo 1.1 supera el conjunto de pruebas estadísticas para validar sus estimaciones. Aunque el análisis de residuos es satisfactorio para ambos modelos, el modelo 1.1 presenta una menor varianza residual y un menor Akaike y Schwarz, por lo que es preferible al 1.2. 16 Por lo tanto, el crecimiento anual de las ventas de la empresa, Δventas, que es la variable modelizada viene explicada de forma satisfactoria por un modelo sencillo ARIMA(2,1,0). 3. Ejemplo 2. El Índice de Empleo de un determinado país La serie a modelizar es el índice de empleo de un determinado país, la serie está corregida de estacionalidad y tiene frecuencia trimestral. El periodo muestral abarca 1962:1 1993:4. Una vez creado el WorKfile y establecido el periodo muestral, se cargan los datos tal y como se ha hecho en el ejemplo anterior. La serie la denominamos empleo en el Workfile El primer paso en la modelización de la serie es su representación gráfica. Para ello en Eviews, la instrucción es: Quick/ Graph/ Graph Line/empleo El resultado es el gráfico adjunto 1a en el que se puede contemplar como la serie empleo muestra una tendencia creciente en los primeros 20 años y después y muestra un marcado comportamiento cíclico en los 10 años últimos. La serie no parece mostrar cambios en la varianza ante desplazamientos del tiempo, lo que se puede comprobar tomando logaritmos en la serie y representando gráficamente esa serie, vemos que los gráficos de ambas series son similares, por lo que trabajaremos con la serie original. Para ello, en Eviews GENR Lempleo =LOG(empleo) y para su representación gráfica: Quick/ Graph/ Graph Line/ empleo Grafico 1 a Gráfico 1b 17 115 4.75 110 4.70 105 4.65 100 4.60 95 4.55 90 4.50 85 4.45 4.40 80 1965 1970 1975 1980 1985 1965 1990 1970 1975 1980 1985 1990 LEMPLEO EMPLEO También se muestra a continuación el correlograma de la serie empleo En Eviews una vez dentro del objeto serie empleo View/Correlogram El correlograma confirma un elevado grado de dependencia de las observaciones de la serie empleo y su no estacionariedad en media por el lento decrecimiento de la FAC. 18 Se realiza también el test de DFA de raíces unitarias, cuyos resultados se presentan a continuación. Para ello, en Eviews: Quick/ SERIES STATISTIC/ Unit root / empleo Test D-F aumentado de la serie empleo Null Hypothesis: EMPLEO has a unit root Exogenous: Constant Lag Length: 1 (Automatic based on SIC, MAXLAG=12) Augmented Dickey-Fuller test statistic Test critical values: 1% level 5% level 10% level t-Statistic Prob.* -2.205738 -3.482879 -2.884477 -2.579080 0.2054 *MacKinnon (1996) one-sided p-values. Augmented Dickey-Fuller Test Equation Dependent Variable: D(EMPLEO) Method: Least Squares Date: 04/19/08 Time: 21:29 Sample (adjusted): 1962Q3 1993Q4 Included observations: 126 after adjustments Variable Coefficient Std. Error t-Statistic Prob. EMPLEO(-1) D(EMPLEO(-1)) C -0.039278 0.478736 3.982081 0.017807 0.078727 1.807249 -2.205738 6.080986 2.203394 0.0293 0.0000 0.0294 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat 0.243969 0.231676 1.457341 261.2326 -224.7214 2.064222 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) 0.014150 1.662605 3.614626 3.682156 19.84590 0.000000 El test DFA no rechaza la hipótesis nula de la existencia de una raíz unitaria en empleo puesto que el valor del estadístico t (-2.205) es notablemente inferior a los valores críticos de la distribución DFA 19 Si ajustamos una tendencia temporal lineal simple de tipo determinista a la serie empleo (como hicimos en el capítulo 1 del programa de la asignatura y práctica 1 y en la modelización de la serie ventas que acabamos de realizar, y restamos de empleo la línea ajustada, podremos comprobar que ese no es un procedimiento correcto para convertir a la serie en estacionaria, ya que los residuos tenderán a estar por encima y por debajo de la media durante períodos seguidos demasiado largos (se deja al alumno que lo compruebe). Por lo tanto, es claro que esa tendencia no es determinista sino estocástica y debemos proceder con diferenciaciones para eliminar esa tendencia. Comenzamos tomando una primera diferencia regular en la serie empleo, cuyo gráfico se muestra a continuación así como su correlograma. Instrucciones en Eviews: Genr DEMPLEO =D(EMPLEO,1) Quick/Graph/Line Graph/DEMPLEO Quick/Series Statistic/Correlogram 8 6 4 2 0 -2 -4 -6 1965 1970 1975 1980 D(EMPLEO,1) 20 1985 1990 El gráfico de DEMPLEO muestra que la serie podría ser estacionaria y también en ese sentido apunta el correlograma al mostrar un decaimiento con cierta rapidez. No obstante, se realiza también el test de DFA, cuyos resultados se muestran a continuación, y corrobora también la no existencia de una raíz unitaria en la serie DEMPLEO y que, por tanto, esa transformación convierte a la serie en estacionaria. Test DFA de la serie DEMPLEO Null Hypothesis: D(EMPLEO,1) has a unit root Exogenous: Constant Lag Length: 0 (Automatic based on SIC, MAXLAG=12) Augmented Dickey-Fuller test statistic Test critical values: 1% level 5% level 10% level *MacKinnon (1996) one-sided p-values. Augmented Dickey-Fuller Test Equation Dependent Variable: D(EMPLEO,2) Method: Least Squares Date: 04/19/08 Time: 21:28 Sample (adjusted): 1962Q3 1993Q4 Included observations: 126 after adjustments 21 t-Statistic Prob.* -6.751657 -3.482879 -2.884477 -2.579080 0.0000 Variable Coefficient Std. Error t-Statistic Prob. D(EMPLEO(-1),1) C -0.537417 0.006063 0.079598 0.131846 -6.751657 0.045988 0.0000 0.9634 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat 0.268803 0.262906 1.479881 271.5657 -227.1654 2.029454 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) -0.003332 1.723714 3.637545 3.682566 45.58488 0.000000 Por lo tanto la serie EMPLEO tiene una raíz unitaria y la primera diferencia convierte a dicha serie en estacionaria, eliminado su tendencia. La serie es del tipo: Zt =(1-B)EMPLEO o EMPLEO ∼I(1) Es decir, es integrada de orden 1 Determinado el grado de diferenciación ó de raíces unitarias, pasamos a especificar el orden de los polinomios AR y MA. Del análisis de los correlogramas de la serie DEMPLEO se deduce que en la FAC existen 2 ó tres coeficientes que son distintos de cero y después todos son cero, mientras que en la FAP solo existe un coeficiente significativo (que no es cero) el primero, y después tienden rápidamente a cero (o “muy” rápidamente en este caso, ya que los coeficientes segundo y siguientes están todos dentro de las bandas de no significación). Esto sugiere que la serie (DEMPLEO) podría haber sido generada por modelos con estructura MA hasta orden 2 o estructura AR(1). Los modelos que vamos a considerar en esta práctica son ARIMA (1,1,0), ARIMA(1;1,2) y ARIMA(2,1,1). Por otro lado, de la observación del gráfico de la serie DEMPLEO se deduce que la media de la serie aparentemente es cero por lo que debe no debe incluirse el término constante en los modelos especificados Los modelos tentativos serian por tanto: 2.1. ARIMA(1,1,0) o (1- φ1 B)(1-B)EMPLEO = at 22 2.2. ARIMA(1,1,2) ) o (1- φ1 B )(1-B)EMPLEO= (1+ θ1B+θ2B2)at 2.3. ARIMA(2,1,1) ) o (1- φ1 B- φ2 B2) (1-B)EMPLEO= (1+ θ1B) at Estimación La estimación de los modelos anteriores en Eviews se hace por medio de las siguientes instrucciones: Quick/ Estimate Equation/ LS EMPLEO ar(1) Quick/ Estimate Equation/ LS EMPLEO ar(1) ma(1) ma(2) Quick/ Estimate Equation/ LS EMPLEO ar(1) ar(2) ma(1) Los resultados de la estimación de estos modelos se presentan a continuación: Estimacion modelo 2.1 Dependent Variable: D(EMPLEO,1) Method: Least Squares Date: 04/21/08 Time: 00:48 Sample (adjusted): 1962Q3 1993Q4 Included observations: 126 after adjustments Convergence achieved after 2 iterations Variable Coefficient Std. Error t-Statistic Prob. AR(1) 0.462622 0.079275 5.835666 0.0000 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Inverted AR Roots 0.214051 0.214051 1.473962 271.5704 -227.1664 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion Durbin-Watson stat .46 Estimacion modelo 2.2 Dependent Variable: D(EMPLEO,1) Method: Least Squares Date: 04/21/08 Time: 01:37 Sample (adjusted): 1962Q3 1993Q4 23 0.014150 1.662605 3.621689 3.644200 2.029500 Included observations: 126 after adjustments Convergence achieved after 8 iterations Backcast: 1961Q3 1961Q4 Variable Coefficient Std. Error t-Statistic Prob. AR(1) MA(1) MA(2) 0.515070 -0.070881 0.008407 0.312357 0.324334 0.170031 1.648981 -0.218544 0.049446 0.1017 0.8274 0.9606 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood 0.215272 0.202513 1.484742 271.1483 -227.0684 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion Durbin-Watson stat Inverted AR Roots Inverted MA Roots .52 .04+.08i .04-.08i 0.014150 1.662605 3.651880 3.719411 1.992157 Estimacion modelo 2.3 Dependent Variable: D(EMPLEO,1) Method: Least Squares Date: 04/21/08 Time: 01:12 Sample (adjusted): 1962Q4 1993Q4 Included observations: 125 after adjustments Convergence achieved after 19 iterations Backcast: 1961Q4 Variable Coefficient Std. Error t-Statistic Prob. AR(1) AR(2) MA(1) -0.459695 0.426099 0.956981 0.094065 0.082802 0.046168 -4.886990 5.145983 20.72805 0.0000 0.0000 0.0000 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Inverted AR Roots Inverted MA Roots 0.239708 0.227244 1.462870 261.0787 -223.3991 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion Durbin-Watson stat .46 -.96 -.92 Validación 24 0.002497 1.664120 3.622385 3.690265 2.031913 En cuanto al modelo 2.1, todos los coeficientes son individualmente significativos según el contraste de la t de student y el ajuste es globalmente aceptable. También son altamente significativos los coeficientes del modelo 2.3. Sin embargo en el modelo 2.2 los coeficientes de los de los parámetros MA no son significativos por lo que el modelo es rechazable. Todos los modelos cumplen las condiciones de estacionariedad y de invertibilidad puesto que tanto las raíces de los polinomios autorregresivos como los de media móvil caen fuera del círculo de radio unidad, aunque en el modelo 2.3 haya una raíz cercana a la unidad en el polinomio autorregresivo y otra en el polinomio de medias móviles. A su vez, las matrices de correlaciones de los coeficientes de estos modelos no muestran signos de multicolinealidad Desde el punto de vista del error estándar de los modelos estimados el 2.1 es el que presenta un valor menor (1,4739) seguido del 2.3, aunque muy cerca (1,4628). Desde el punto de vista del criterio de Akaike, tanto el modelo 2.1 como el 2.3 presentan el mismo valor (3,622) El análisis de los residuos de los dos modelos seleccionados a través de sus correspondientes correlogramas, el estadístico Q y sus gráficos de residuos, que se presentan a continuación, nos indica que ambos cumplen las condiciones para ser considerados como ruido blanco. No obstante, el modelo 2.3 puede ser mejor desde el punto de vista del error estándar de la ecuación. Ambos modelos presentan residuos atípicos en la observación 87:1 y en la 92:1 y la raíz del polinomio media móvil roza la unidad, lo que puede estar indicando sobrediferenciación. Se deja al alumno que pruebe con la serie original EMPLEO, sin diferenciación, y corrija la serie de atípicos y pruebe con especificaciones alternativas. Correlograma de los residuos del modelo 2.1 25 Grafico de residuos del modelo 2.1 8 4 0 8 -4 4 -8 0 -4 1965 1970 1975 1980 Residual Actual Correlograma de los residuos del modelo 2.3 26 1985 1990 Fitted Grafico de residuos del modelo 2.3 8 4 0 8 -4 4 -8 0 -4 1965 1970 1975 1980 Residual Actual 1985 1990 Fitted 4. Ejemplo 3. Ventas de cigarros puros de una empresa tabaquera La serie a modelizar es el volumen de ventas mensual de puros de una empresa tabaquera para el periodo muestral 1989:01 1996:12. El objetivo que se 27 persigue con este ejercicio es que el alumno aprenda a construir un modelo univariante de una serie de frecuencia mensual que tiene una marcada tendencia y estacionalidad. Una vez creado el fichero de trabajo en Eviews para esa frecuencia y periodo muestral, de la misma forma como se ha realizado en los dos ejercicios anteriores, se realiza la representación gráfica de la serie objeto de análisis. La serie se denomina puros Instrucciones: Quick/Graph/ puros/Line graph Ventas de puros de una empresa tabaquera 800 700 600 500 400 300 200 1989 1990 1991 1992 1993 1994 1995 1996 PUROS Este gráfico es indicativo de una serie en la que el nivel disminuye con el tiempo y muestra, por tanto, una tendencia decreciente. La media no se mantiene constante y disminuye con el tiempo y la serie muy probablemente no será estacionaria en media, por lo que necesitará una diferencia regular. También se observa un marcado patrón estacional con picos en octubre y valores bajos en 28 diciembre. La varianza es visualmente un tanto mayor al principio de la muestra (año 1989) que al final, años 1995 y 1996, pero en el resto de los años parece muy uniforme. Tomamos logaritmos en la serie puros y realizamos su representación gráfica. Para ello en Eviews: GENR Lpuros= log(puros) Quick/Graph/ Lpuros/Line graph Evolución logaritmica de las ventas de puros 6.6 6.4 6.2 6.0 5.8 5.6 5.4 1989 1990 1991 1992 1993 1994 1995 1996 LPUROS Este gráfico del logaritmo de la variable carga (Lpuros ) es muy similar al anterior y la varianza parece estable, por lo que en adelante decidimos trabajar con la transformación logarítmica o sin ella es indiferente, por lo que decidimos trabajar con la métrica original. 29 Como hemos visto en los dos ejemplos anteriores el correlograma es un instrumento útil para verificar la estacionariedad de la serie. A continuación se presentan los correlogramas. Instrucciones: Una vez en el objeto serie puros, View/ Correlogram El correlograma de la serie puros decae lentamente, tanto en la parte regular (1,2,3,etc) como en la estacional (12,24,36,etc), por lo que confirma la no estacionariedad apuntada anteriormente. Pasamos, en primer lugar, a corregir la no estacionariedad en la parte regular tomando una diferencia de orden 1 y representamos el gráfico de esa serie transformada y su correspondiente correlograma. Instrucciones Eviews: Genr dpuros=D(puros,1) Quick/Graph/dpuros/Line graph Quick/series statistic/correlogram/dpuros 30 150 100 50 0 -50 -100 -150 -200 -250 1990 1991 1992 1993 1994 1995 1996 DPUROS Según la gráfica de la primera diferencia regular, d(puros,1), la transformación parece que ha eliminado la tendencia regular pero persiste una cierta la tendencia estacional. El análisis del correlograma indica que, si bien se ha corregido la no estacionariedad de la parte regular, persiste la no estacionariedad en el componente 31 estacional, al ser significativos en el correlograma simple los retardos 12, 24 y también podría serlo el de 36, por lo que se debe tomar una diferencia de tipo estacional junto con la regular. Instrucciones: Genr dd12puros=d(puros,1,12) Quick/Graph/Line Graph/dd12puros Quick/series statistic/correlogram/dd12puros 150 100 50 0 -50 -100 -150 1990 1991 1992 1993 1994 1995 1996 DD12PUROS El gráfico de dd12puros muestra una clara estacionariedad en media y el correlograma de esta variable que se muestra a continuación parece que no ofrece dudas sobre la estacionariedad. 32 No obstante, se elabora el test de DFA para la serie dd12puros para verificar si esta transformación es estacionaria Test DFA de la serie dd12puros Null Hypothesis: DD12PUROS has a unit root Exogenous: Constant Lag Length: 1 (Automatic based on SIC, MAXLAG=11) Augmented Dickey-Fuller test statistic Test critical values: 1% level 5% level 10% level *MacKinnon (1996) one-sided p-values. Augmented Dickey-Fuller Test Equation Dependent Variable: D(DD12PUROS) Method: Least Squares Date: 04/13/08 Time: 14:33 Sample (adjusted): 1990M04 1996M12 Included observations: 81 after adjustments 33 t-Statistic Prob.* -12.63026 -3.513344 -2.897678 -2.586103 0.0001 Variable Coefficient Std. Error t-Statistic Prob. DD12PUROS(-1) D(DD12PUROS(-1)) C -2.275417 0.447603 -0.630273 0.180156 0.101841 4.413679 -12.63026 4.395103 -0.142800 0.0000 0.0000 0.8868 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat 0.828732 0.824341 39.71255 123012.8 -411.6206 2.110029 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion F-statistic Prob(F-statistic) -0.086420 94.75286 10.23755 10.32623 188.7137 0.000000 Los resultados del test DFA son concluyentes sobre la estacionariedad de la serie dd12lcarga, el estadístico t (-12.630) supera ampliamente los valores críticos de la distribución ADF, lo que confirma la estacionariedad de esta transformación ya adelantada por el análisis gráfico y el del correlograma. A la vista de los resultados anteriores, la transformación que se sugiere es: Zt =(1-B) (1-B12)puros Para finalizar la etapa de especificación inicial debemos determinar cuales son los modelos estacionales multiplicativos ARMA (p,q) Χ ARMA(P,Q)S que pueden generar la serie. Del análisis del correlograma de la serie dd12puros se deduce que el proceso generador de datos puede tener un componente media móvil regular de orden 1 MA(1), puesto que en el correlograma simple después del primer coeficiente significativo el resto son ceros, y otro estacional de orden MA(1)12 , puesto que después del coeficiente de orden 12 significativo el resto son ceros, es decir un ARMA (0,1)(0,1)12. 3.1. ARIMA(0,1,1)×(0,1,1)12 o (1-B)(1-B12)puros= (1+ θ1B)(1+θ12B12)at Estimación del modelo 3.1 34 Dependent Variable: DD12PUROS Method: Least Squares Date: 04/13/08 Time: 18:09 Sample (adjusted): 1990M02 1996M12 Included observations: 83 after adjustments Convergence achieved after 14 iterations Backcast: 1987M12 1988M12 Variable Coefficient Std. Error t-Statistic Prob. MA(1) SMA(12) -0.677779 -0.867044 0.066918 0.034549 -10.12847 -25.09612 0.0000 0.0000 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Inverted MA Roots 0.662434 0.658267 30.88643 77271.69 -401.4760 .99 .49-.86i -.49-.86i -.99 Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion Durbin-Watson stat .86-.49i .49+.86i -.49+.86i -0.481928 52.83531 9.722312 9.780597 2.546859 .86+.49i .00+.99i -.86+.49i .68 -.00-.99i -.86-.49i Grafico residuos del modelo 3.1 80 40 0 -40 -80 1990 1991 1992 1993 1994 1995 DD12PUROS Residuals 35 1996 Correlograma residuos del modelo 3.1 3.2. ARIMA(2,1,0)×(0,1,1)12 ,, (1- φ1B-φ2B2) (1-B)(1-B12) puros= (1+θ12B12)at Dependent Variable: D(PUROS,1,12) Method: Least Squares Date: 04/10/06 Time: 02:01 Sample (adjusted): 1990M04 1996M12 Included observations: 81 after adjustments Convergence achieved after 7 iterations Backcast: 1988M01 1988M12 Variable Coefficient Std. Error t-Statistic Prob. -0.952059 -0.562088 -0.903840 0.096127 0.095416 0.022752 -9.904132 -5.890927 -39.72502 0.0000 0.0000 0.0000 31 AR(1) AR(2) MA(12) R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Inverted AR Roots Inverted MA Roots 0.732067 0.725197 28.01044 61197.62 -383.3443 -.48-.58i .99 .50+.86i Mean dependent var S.D. dependent var Akaike info criterion Schwarz criterion Durbin-Watson stat -.48+.58i .86-.50i .00+.99i 36 .86+.50i -.00-.99i -0.148148 53.43293 9.539365 9.628049 2.068255 .50-.86i -.50+.86i -.50-.86i -.86+.50i -.86-.50i -.99 Validación El modelo 3.1 presenta todos su coeficientes significativos, según el t ratio, la matriz de coeficientes que se puede consultar en la ventana de la ecuación no proporciona coeficientes de correlación elevados por lo que no presentan signos de multicolinealidad. Analizando los correlogramas de los residuos se observa que todos los coeficientes de autocorrelación no son distintos de cero ya que entran dentro de las bandas de confianza. El gráfico de residuos también indica que los residuos son ruido blanco. El modelo, en principio, parece válido pero presenta alguna raíz de la media móvil próxima a la unidad lo que puede indicar sobrediferenciación. No obstante, la identificación del grado de diferenciación a través del análisis gráfico, los correlogramas de la serie y el test DFA de raíces unitarias se decantaban por una raíz de tipo regular y otra estacional. El modelo 3.2 también tiene todos los coeficientes significativos, los residuos que se pueden consultar en la ventana de la ecuación son ruido blanco a través de la observación del gráfico de los residuos y de su correlograma. Este modelo tiene también una raíz de la media móvil próxima a la unidad, sin embargo, tiene un Akaike inferior al 3.1 y también un error estándar de la ecuación menor por lo que será preferido al 3.1. La mejora del modelo puede venir por corregir algunos residuos atípicos que pueden distorsionar el análisis y la especificación. 37