guía
Anuncio

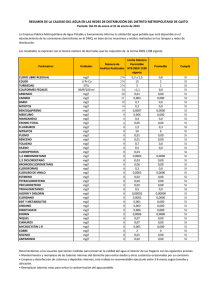
Práctica 4 vgaribay EJERCICIOS 1.- REGRESIÓN LINEAL SIMPLE 5.1 Regresión de Peso sobre Altura a) Estudio descriptivo de ambas variables Datos en Encuesta.sgd Marco elementos atípicos: b) Obtener la recta de regresión y comprobar que el vector de medias muestrales pertenece a la recta. Relate/One Factor/Simple Regression…(linear) Interpretar la tabla de coeficientes estimados y la tabla ANOVA. b1) Obtener la recta de regresión… 1 Práctica 4 vgaribay Solución: Recta de regresión (con todos los puntos) Peso kg = -115,18 + 1,06074*Altura cm 2 Práctica 4 vgaribay b2) … y comprobar que el vector de medias muestrales pertenece a la recta. Count Average Standard deviation Peso kg 269 70,7967 12,6559 Altura cm 269 175,327 8,92991 De forma aproximada en la gráfica sobre la recta de regresión con Locate: De manera más precisa mediante Forecast b3) Interpretar la tabla de coeficientes estimados y la tabla ANOVA. Coefficients Least Squares Parameter Estimate Intercept -115,18 Slope 1,06074 Analysis of Variance Source Sum of Squares Model 24046,2 Residual 18880,0 Total (Corr.) 42926,2 Standard Error 10,0981 0,0575216 Df 1 267 268 T Statistic -11,4061 18,4407 Mean Square 24046,2 70,7116 P-Value 0,0000 0,0000 F-Ratio 340,06 P-Value 0,0000 Peso Kg= -115,18 + 1,06074 Altura cm Rechazo a todos los niveles habituales la hipótesis de no efecto del regresor “Altura” (Ho: 1=0) Cambios en la Altura provocan cambios en el peso medio correspondiente. 3 Práctica 4 vgaribay c) Hallar un intervalo de confianza al 95% para la pendiente. Relate/Multiple Factors/Multiple Regression… (confidence interval) Intervalos de confianza del 95,0% para las estimaciones de los coeficientes Error Parámetro Estimación Estándar Límite Inferior CONSTANTE -115,18 10,0981 -135,062 Altura cm 1,06074 0,0575216 0,947486 Límite Superior -95,2977 1,17399 Botón derecho > Options para modificar el nivel de confianz d) Guardar los valores ajustados, los residuos y los residuos estudentizados. Realizar un análisis de los residuos. Puedo salvar en la hoja de datos valores predichos, residuos, residuos estudentizados, leverages, limites inf y sup de Intervalos de Confianza para la respuesta y para la media en cada xi observado. No tengo los DFITS, que sí puedo conseguir dentro del módulo de Regresión Múltiple 4 Práctica 4 vgaribay Test de Normalidad de los residuos Test de Normalidad de los residuos estudentizados 5 Práctica 4 vgaribay Para identificar mejor por su número los Outliers y puntos de influencia añado un contador en la base de datos, vble “caso”: Count(1;269;1) e) Analizar si hay puntos de influencia y eliminarlos si es el caso. En REGRESION SIMPLE puedo obtener Residuos y Residuos Studentizados Residuos Atípicos Predicciones Residuos Fila X 22 171,0 26 184,0 Y 84,0 103,0 Y 66,2067 79,9963 Residuos 17,7933 23,0037 Studentizados 2,13 2,78 41 75 78,0 110,0 59,8422 86,3607 18,1578 23,6393 2,18 2,87 165,0 190,0 6 Práctica 4 vgaribay 77 175,0 91,0 70,4496 20,5504 2,47 97 121 122 171,0 173,0 120,0 49,0 90,0 39,0 66,2067 68,3282 12,109 -17,2067 21,6718 26,891 -2,06 2,61 3,54 215 216 279 188,0 185,0 172,0 105,0 103,0 120,0 84,2393 81,057 67,2674 20,7607 21,943 52,7326 2,51 2,65 6,80 El StatAdvisor La tabla de residuos atípicos enlista todas las observaciones que tienen residuos Estudentizados mayores a 2, en valor absoluto. Los residuos Estudentizados miden cuántas desviaciones estándar se desvía cada valor observado de Peso kg del modelo ajustado, utilizando todos los datos excepto esa observación. En este caso, hay 11 residuos Estudentizados mayores que 2, 2 mayores que 3. Es conveniente examinar detenidamente las observaciones con residuos mayores a 3 para determinar si son valores aberrantes que debieran ser eliminados del modelo y tratados por separado. … y también los leverages hii (influencia potencial) PELIGRO cuando hii > 2 *(k+1)/n = 4/269= 0,01486989 (95%) (o 3* … 99%) Puntos Influyentes Fila X Y Predicciones Y 122 250 120,0 196,0 39,0 77,0 12,109 92,7252 Residuos Studentizados Influencia 3,54 -1,90 0,146952 0,0237148 267 198,0 108,0 94,8467 1,59 0,0277713 277 155,0 45,0 49,2349 -0,51 0,0230515 Influencia Media de un punto = 0,00743494 El StatAdvisor La tabla de puntos influyentes enlista todas las observaciones que tienen valores de influencia mayores que 3 veces la de un punto promedio de los datos. Valor de Influencia es un estadístico que mide que tan influyente es cada observación en la determinación de los coeficientes del modelo estimado. En este caso, un punto promedio de los datos tendría un valor de influencia igual a 0,00743494. Hay 4 puntos con más de 3 veces el valor de influencia promedio, uno con más de 5 veces. Deberían examinarse cuidadosamente aquellos puntos con más de 5 veces el valor de influencia promedio para determinar que tanto podría cambiar el modelo si no estuvieran presentes. En REGRESION MULTIPLE puedo obtener además los valores DFITS (influencia efectiva) (por el contrario, NO puedo hacer predicción (Forecast) directamente ni PlotXY) Residuos Atípicos Fila 22 26 41 75 77 97 121 122 215 216 279 Y 84,0 103,0 78,0 110,0 91,0 49,0 90,0 39,0 105,0 103,0 120,0 Y Predicha 66,2067 79,9963 59,8422 86,3607 70,4496 66,2067 68,3282 12,109 84,2393 81,057 67,2674 Residuo 17,7933 23,0037 18,1578 23,6393 20,5504 -17,2067 21,6718 26,891 20,7607 21,943 52,7326 Residuo Estudentizado 2,13 2,78 2,18 2,87 2,47 -2,06 2,61 3,54 2,51 2,65 6,80 7 Práctica 4 vgaribay El StatAdvisor La tabla de residuos atípicos enlista todas las observaciones que tienen residuos Estudentizados mayores a 2, en valor absoluto. Los residuos Estudentizados miden cuántas desviaciones estándar se desvía cada valor observado de Peso kg del modelo ajustado, utilizando todos los datos excepto esa observación. En este caso, hay 11 residuos Estudentizados mayores que 2, 2 mayores que 3. Es conveniente examinar detenidamente las observaciones con residuos mayores a 3 para determinar si son valores aberrantes que debieran ser eliminados del modelo y tratados por separado. Puntos Influyentes Fila 26 41 75 122 215 216 250 267 277 279 Distancia de Influencia Mahalanobis DFITS 0,00723709 0,950121 0,237352 0,00870782 1,34914 0,204698 0,0137914 2,73754 0,339255 0,146952 44,999 1,4677 0,0112323 2,03683 0,267236 0,00809552 1,18288 0,239356 0,0237148 5,48939 -0,296416 0,0277713 6,63046 0,268882 0,0230515 5,30372 -0,0781569 0,00423545 0,139407 0,443169 Influencia media de un solo punto = 0,00743494 PELIGRO si DFITS>2*RAIZ((k+1)/n) = 2*RAIZ(2/269)= 0,17245225 (95%) (o 3* … 99%) El StatAdvisor La tabla de puntos influyentes enlista todas las observaciones que tienen valores de influencia mayores que 3 veces la de un punto promedio de los datos, ó que tienen un valor inusual de DFITS. Valor de Influencia es un estadístico que mide que tan influyente es cada observación en la determinación de los coeficientes del modelo estimado. DFITS es un estadístico que mide que tanto podrían cambiar los coeficientes estimados si la observación se eliminara del conjunto de datos. En este caso, un punto promedio de los datos tendría un valor de influencia igual a 0,00743494. Hay 4 puntos con más de 3 veces el valor de influencia promedio, uno con más de 5 veces. Deberían examinarse cuidadosamente aquellos puntos con más de 5 veces el valor de influencia promedio para determinar que tanto podría cambiar el modelo si no estuvieran presentes. Hay 9 datos con valores inusualmente grandes de DFITS. e2) Elimino las observaciones siguientes: 279 DFITS=0,443169 >0,17245225 122 DFITS=1,4677 leverage hii=0,146952 > 0.015 Selecciono en el gráfico el punto a suprimir y pincho botón +/- 8 Práctica 4 vgaribay Regresión Simple - Peso kg vs. Altura cm Variable dependiente: Peso kg Variable independiente: Altura cm Lineal: Y = a + b*X Coeficientes Mínimos Cuadrados Parámetro Estimado Intercepto -131,613 Pendiente 1,15265 Análisis de Varianza Fuente Suma de Cuadrados Modelo 24295,2 Residuo 15197,9 Total (Corr.) 39493,1 Estándar Error 9,84199 0,0560026 Gl 1 265 266 Estadístico T -13,3726 20,5822 Cuadrado Medio 24295,2 57,3507 Valor-P 0,0000 0,0000 Razón-F 423,62 Valor-P 0,0000 Coeficiente de Correlación = 0,784331 R-cuadrada = 61,5175 porciento R-cuadrado (ajustado para g.l.) = 61,3723 porciento Error estándar del est. = 7,57302 Error absoluto medio = 5,86925 Estadístico Durbin-Watson = 1,55717 (P=0,0001) Autocorrelación de residuos en retraso 1 = 0,221257 Número de filas excluídas: 2 Recta de regresión (eliminados los puntos 122 y 279) Peso kg = -131,613 + 1,15265*Altura cm f) Con el modelo final, proporcionar un intervalo de confianza al 90% para la respuesta media y otro al 99% para la predicción del peso de una alumna nueva que mide 166.5 cm. En el plot XY de Regresión Simple, además de la recta ajustada, con Opciones, controlo si quiero las bandas o cotas de la confianza deseada, para Ey/ X=xo y/o para la respuesta y/X=xo En tabla Forecast, introduzco el valor x=166.5 y 90% Valores Predichos X 166,5 Predicciones Y 60,3036 90,00% Límite Inferior 47,7521 Predicción Superior 72,8551 90,00% Límite Inferior 59,1702 Confianza Superior 61,437 I.de C. del 90% para la Respuesta Media 9 Práctica 4 vgaribay Subo la confianza al 99% para el I. de C. de la respuesta Valores Predichos X 166,5 Predicciones Y 60,3036 99,00% Límite Inferior 40,5747 Predicción Superior 80,0325 99,00% Límite Inferior 58,5221 Confianza Superior 62,0851 I.de C. del 99% para la respuesta APENDICE Ajustando por separado Hombres y Mujeres: 10 Práctica 4 vgaribay 2.- REGRESIÓN LINEAL MÚLTIPLE Se ha diseñado un experimento para explicar la producción de oxígeno (O2UP), medida en miligramos de oxígeno por minuto, basándose en 5 medidas químicas: • Demanda biológica de oxígeno; BOD. • Nitrógeno total; TKN. • Sólido total; TS. • Sólidos volátiles totales; TVS. • Demanda química de oxígeno; COD. Todas estas variables están medidas en miligramos por litro. Los datos están en el fichero Oxigeno.sgd’. Plantea y valida un modelo de regresión múltiple que relacione la producción de oxígeno con las otras 5 variables. Interprétalo y utilízalo para realizar predicciones de la producción de oxígeno. Relate/Multiple Factors/Multiple Regression... Suprimo la observación 1 11 Práctica 4 vgaribay Normalidad de los residuos: 12 Práctica 4 vgaribay Saco TVS del modelo Quedan 4 variables Dependent variable: O2UP Independent variables: BOD TKN TS COD Parameter CONSTANT BOD TKN TS COD Estimate -6,82193 -0,00239808 0,00886704 0,00122322 0,000408475 Analysis of Variance Source Sum of Squares Model 69,6587 Residual 10,3224 Total (Corr.) 79,9811 Standard Error 1,13452 0,00169378 0,00415638 0,000234285 0,000262474 Df 4 14 18 T Statistic -6,01303 -1,41581 2,13335 5,22109 1,55625 Mean Square 17,4147 0,737313 P-Value 0,0000 0,1787 0,0511 0,0001 0,1420 F-Ratio 23,62 P-Value 0,0000 R-squared = 87,094 percent R-squared (adjusted for d.f.) = 83,4065 percent Standard Error of Est. = 0,858669 Mean absolute error = 0,606915 Durbin-Watson statistic = 2,81821 (P=0,9322) Lag 1 residual autocorrelation = -0,449124 Number of excluded rows: 1 The StatAdvisor The output shows the results of fitting a multiple linear regression model to describe the relationship between O2UP and 4 independent variables. The equation of the fitted model is O2UP = -6,82193 - 0,00239808*BOD + 0,00886704*TKN + 0,00122322*TS + 0,000408475*COD Unusual Residuals Predicted Row Y Y 7 1,3 2,8389 Residual -1,5389 Studentized Residual -2,28 Influential Points Row 2 4 6 7 Leverage 0,537819 0,369411 0,378724 0,198778 Mahalanobis Distance 18,8377 9,01446 9,41859 3,27316 DFITS 1,45373 1,5281 1,32156 -1,13757 Peligros: Leverage > 2* (k+1)/n=10/20= 0.5 GFITS> 2*raiz((k+1)/n)=1 13 Práctica 4 vgaribay Saco BOD del modelo Quedan 3 variables Multiple Regression - O2UP Dependent variable: O2UP Independent variables: TKN TS COD Parameter CONSTANT TKN TS COD Estimate -6,7775 0,0116145 0,00102932 0,000179135 Analysis of Variance Source Sum of Squares Model 68,1807 Residual 11,8003 Total (Corr.) 79,9811 Standard Error 1,17145 0,00379663 0,000196347 0,000213331 Df 3 15 18 T Statistic -5,78558 3,05916 5,24234 0,839704 Mean Square 22,7269 0,78669 P-Value 0,0000 0,0080 0,0001 0,4143 F-Ratio 28,89 P-Value 0,0000 R-squared = 85,2461 percent R-squared (adjusted for d.f.) = 82,2953 percent Standard Error of Est. = 0,886955 Mean absolute error = 0,682465 Durbin-Watson statistic = 2,66236 (P=0,8731) Lag 1 residual autocorrelation = -0,399632 Number of excluded rows: 1 The StatAdvisor The output shows the results of fitting a multiple linear regression model to describe the relationship between O2UP and 3 independent variables. The equation of the fitted model is O2UP = -6,7775 + 0,0116145*TKN + 0,00102932*TS + 0,000179135*COD Saco COD del modelo Quedan 2 variables Multiple Regression - O2UP Dependent variable: O2UP Independent variables: TKN TS Parameter CONSTANT TKN TS Estimate -6,41355 0,0112108 0,00115329 Analysis of Variance Source Sum of Squares Model 67,626 Residual 12,355 Total (Corr.) 79,9811 Standard Error 1,07824 0,0037312 0,00012824 Df 2 16 18 T Statistic -5,94816 3,00461 8,99321 Mean Square 33,813 0,77219 P-Value 0,0000 0,0084 0,0000 F-Ratio 43,79 P-Value 0,0000 R-squared = 84,5525 percent 14 Práctica 4 vgaribay R-squared (adjusted for d.f.) = 82,6216 percent Standard Error of Est. = 0,878744 Mean absolute error = 0,711168 Durbin-Watson statistic = 2,78633 (P=0,9326) Lag 1 residual autocorrelation = -0,452628 Number of excluded rows: 1 The StatAdvisor The output shows the results of fitting a multiple linear regression model to describe the relationship between O2UP and 2 independent variables. The equation of the fitted model is O2UP = -6,41355 + 0,0112108*TKN + 0,00115329*TS Unusual Residuals Predicted Row Y Y 4 5,2 3,58988 Residual 1,61012 Studentized Residual 2,14 Influential Points Mahalanobis Row Leverage Distance DFITS 2 0,420542 11,3933 1,57973 Average leverage of single data point = 0,157895 Multiple Regression - O2UP Dependent variable: O2UP Independent variables: TKN TS COD Parameter CONSTANT TKN TS COD Estimate -6,7775 0,0116145 0,00102932 0,000179135 Analysis of Variance Source Sum of Squares Model 68,1807 Residual 11,8003 Total (Corr.) 79,9811 Standard Error 1,17145 0,00379663 0,000196347 0,000213331 Df 3 15 18 T Statistic -5,78558 3,05916 5,24234 0,839704 Mean Square 22,7269 0,78669 P-Value 0,0000 0,0080 0,0001 0,4143 F-Ratio 28,89 P-Value 0,0000 R-squared = 85,2461 percent R-squared (adjusted for d.f.) = 82,2953 percent Standard Error of Est. = 0,886955 Mean absolute error = 0,682465 Durbin-Watson statistic = 2,66236 (P=0,8731) Lag 1 residual autocorrelation = -0,399632 Number of excluded rows: 1 The StatAdvisor The output shows the results of fitting a multiple linear regression model to describe the relationship between O2UP and 3 independent variables. The equation of the fitted model is O2UP = -6,7775 + 0,0116145*TKN + 0,00102932*TS + 0,000179135*COD 15