File
Anuncio

UNIVERSIDAD NACIONAL DE TRUJILLO
ESCUELA PROFESIONAL DE ECONOMÍA
ECONOMETRÍA II
MODELO DE ECUACIONES SIMULTÁNEAS
EJERCICIO 20.14
Sigüenza Aguilar Victoria
Profesores responsables del curso:
Jorge Zegarra, Wilhem Guardia, Julio Reyes
1
EJERCICIO 20.14
Considérese el siguiente modelo macroeconómico simple para la economía
estadounidense, digamos durante el período 1965-2006.
Función Consumo Privado:
Ct = α0 + α1Yt + α2Ct-1 + u1t
α1>0 ; 0< α2<1
Función Inversión Privada Bruta:
It = β0 + β1Yt + β2Rt + β3It-1 + u2t
β1>0 ; β2<0 ; 0< β3<1
Demanda del Dinero en Función:
Rt = λ0 + λ1Yt + λ2Mt-1 + λ3Pt + λ4Rt-1 + u3t
λ1>0 ; λ2<0 ; λ3>0 ; 0<λ4<1
Identidad de Ingreso:
Yt = Ct + It + Gt
Donde: C= Consumo Privado Real, I= Inversión Privada Bruta Real, G=Gasto
Gubernamental Real, Y = PBI Real, M = Oferta de Dinero a Precios actuales, R= Tasa
de Interés a Largo Plazo (%), P = Índice de Precios al Consumidor. Las variables
endógenas son: C, I, R, y Y. Las variables predeterminadas son: Ct-1, It-1, Mt-1, Pt, Rt-1, y
Gt más el término de intersección. Las u son los términos de error.
a) Utilizando la condición de orden de la identificación, determínese cuál de las 4
ecuaciones es exactamente identificada o sobreidentificada.
b) ¿Qué método(s) se utiliza(n) para calcular las ecuaciones identificadas?
c) Obténgase datos apropiados para fuentes privadas y/o gubernamentales,
estímese el modelo y coméntese los resultados.
2
DESARROLLO
a) Utilizando la condición de orden de la identificación, determínese cuál de
las 4 ecuaciones es exactamente identificada o sobreidentificada.
Variables
endógenas
incluida g
Variables
Variable
predeterminada predeterminada
incluida k
incluida K-k
Identificación
K-k; g-1
5>1
Ecuación 1
2
2
5
Sobre
Identificado
5>2
Ecuación 2
3
2
5
Sobre
Identificado
3>1
Ecuación 3
2
4
3
Sobre
Identificado
G = 4 (C, I, R, Y)
K = 7 (Ct-1, It-1, Mt-1, Pt, Rt-1, Gt y la constante)
b) ¿Qué método(s) se utiliza(n) para calcular las ecuaciones identificadas?
Para una ecuación exactamente identificada se usa el Método de Mínimos
Cuadrados Indirectos (MCI); pero cuando la ecuación está sobreidentificada se usa
el Método de Mínimos Cuadrados en Dos Etapas (MC2E).
Para el ejercicio que estamos tratando, las ecuaciones del sistema están sobre
identificadas por ello es recomendable emplear el Método de Mínimos Cuadrados
en Dos Etapas (MC2E).
c) Obténgase datos apropiados para fuentes privadas y/o gubernamentales,
estímese el modelo y coméntese los resultados.
El modelo a estimar, está en función al período 1980-2006; y se ha desarrollado
usando el programa Eviews.
3
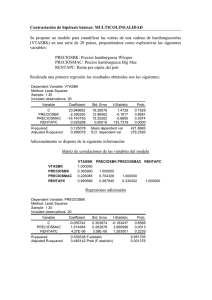
System: SISTEMA1
Estimation Method: Two-Stage Least Squares
Date: 09/28/08 Time: 21:04
Sample: 1981 2006
Included observations: 26
Total system (balanced) observations 78
C(1)
C(2)
C(3)
C(4)
C(5)
C(6)
C(7)
C(8)
C(9)
C(10)
C(11)
C(12)
Coefficient
Std. Error
t-Statistic
Prob.
-176.5336
0.259824
0.674461
-608.7682
0.152547
16.76322
0.416010
4.369016
0.002898
-0.000945
-0.149844
0.590448
61.13613
0.069171
0.095483
348.5780
0.067765
13.24595
0.247910
4.315468
0.001780
0.001200
0.081726
0.164834
-2.887550
3.756269
7.063678
-1.746433
2.251122
1.265536
1.678066
1.012408
1.627966
-0.786943
-1.833503
3.582087
0.0052
0.0004
0.0000
0.0854
0.0277
0.2101
0.0981
0.3150
0.1083
0.4341
0.0712
0.0006
Determinant residual covariance
7252516.
Equation: CP=C(1)+C(2)*Y+C(3)*CP(-1)
Instruments: C CP(-1) I(-1) M(-1) P R(-1) G
Observations: 26
R-squared
0.999061 Mean dependent var
Adjusted R-squared
0.998979 S.D. dependent var
S.E. of regression
44.86774 Sum squared resid
Durbin-Watson stat
0.879200
Equation: I=C(4)+C(5)*Y+C(6)*R+C(7)*I(-1)
Instruments: C CP(-1) I(-1) M(-1) P R(-1) G
Observations: 26
R-squared
0.976190 Mean dependent var
Adjusted R-squared
0.972943 S.D. dependent var
S.E. of regression
68.22973 Sum squared resid
Durbin-Watson stat
0.961018
Equation: R=C(8)+C(9)*Y+C(10)*M(-1)+C(11)*P+C(12)*R(-1)
Instruments: C CP(-1) I(-1) M(-1) P R(-1) G
Observations: 26
R-squared
0.822420 Mean dependent var
Adjusted R-squared
0.788595 S.D. dependent var
S.E. of regression
1.577878 Sum squared resid
Durbin-Watson stat
1.234408
4
5464.831
1404.198
46301.61
1187.362
414.7946
102416.5
6.162308
3.431753
52.28365
Sin embargo, haber resuelto el modelo usando un sistema presenta la desventaja de
no poder comprobar la autocorrelación y mucho menos corregirla; por ello es
conveniente estimar el modelo ecuación por ecuación, aunque esto también
representa un poco más de tiempo de trabajo.
La primera ecuación estimada es: Ct = α0 + α1Yt + α2Ct-1 + u1t
α1>0 ; 0< α2<1
Dependent Variable: CP
Method: Two-Stage Least Squares
Date: 10/02/08 Time: 12:47
Sample (adjusted): 1981 2006
Included observations: 26 after adjustments
Instrument list: CP(-1) I(-1) M(-1) P R(-1) G C
Variable
Coefficient
Std. Error
t-Statistic
Prob.
C
Y
CP(-1)
-176.5336
0.259824
0.674461
61.13613
0.069171
0.095483
-2.887550
3.756269
7.063678
0.0083
0.0010
0.0000
R-squared
Adjusted R-squared
S.E. of regression
F-statistic
Prob(F-statistic)
0.999061
0.998979
44.86774
12227.29
0.000000
Mean dependent var
S.D. dependent var
Sum squared resid
Durbin-Watson stat
5464.831
1404.198
46301.61
0.879200
La estimación indica que aparentemente todo está bien, los parámetros cumplen las
restricciones en cuanto a sus signos y existe un elevado R2; sin embargo para
asegurarnos de que los valores estimados sean MELI, será necesario averiguar si
existe autocorrelación entre los errores.
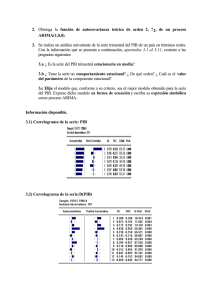
Para ello empezaremos usando el Correlograma de Residuos (View – Residual Test
- Correlogram Q – statics); el cual de una forma gráfica nos mostrará la existencia
de autocorrelación.
5
Date: 10/02/08 Time: 13:05
Sample: 1981 2006
Included observations: 26
Autocorrelation
. |****
. |* .
. | .
. | .
. | .
. *| .
.**| .
.**| .
. | .
. | .
. | .
. | .
|
|
|
|
|
|
|
|
|
|
|
|
Partial Correlation
. |****
. *| .
. *| .
. |* .
. *| .
. *| .
. *| .
. | .
. |* .
. *| .
. *| .
. |* .
|
1
2
3
4
5
6
7
8
9
10
11
12
|
|
|
|
|
|
|
|
|
|
|
AC
PAC
Q-Stat
Prob
0.521
0.185
-0.025
-0.015
-0.054
-0.154
-0.285
-0.234
-0.042
0.009
-0.049
0.012
0.521
-0.118
-0.100
0.088
-0.092
-0.150
-0.175
0.012
0.121
-0.093
-0.091
0.137
7.9019
8.9441
8.9646
8.9720
9.0740
9.9364
13.058
15.272
15.349
15.352
15.468
15.476
0.005
0.011
0.030
0.062
0.106
0.127
0.071
0.054
0.082
0.120
0.162
0.216
Si las (*) se salen de los (.) entonces estamos frente a una problema de
autocorrelación. Para una forma más acertada usaremos el test de Correlación serial
de Breusch – Godfrey (View – Residual Test – Serial Correlation LM Test).
Para este test, especificaremos el número de retardos (lags), a incluir en el contraste,
igual a 1; y luego aparecerá la tabla que presentaremos a continuación.
Breusch-Godfrey Serial Correlation LM Test:
Obs*R-squared
7.419512
Probability
0.006452
Test Equation:
Dependent Variable: RESID
Method: Two-Stage Least Squares
Date: 10/02/08 Time: 13:09
Presample missing value lagged residuals set to zero.
Variable
Coefficient
Std. Error
t-Statistic
Prob.
C
Y
CP(-1)
RESID(-1)
-0.007054
0.012375
-0.018548
0.537017
0.024386
0.035800
0.053835
0.183109
-0.289276
0.345675
-0.344541
2.932773
0.7751
0.7329
0.7337
0.0077
R-squared
Adjusted R-squared
S.E. of regression
Sum squared resid
Log likelihood
Durbin-Watson stat
0.285366
0.187916
38.78186
33088.71
-129.8275
1.810738
Mean dependent var
S.D. dependent var
Akaike info criterion
Schwarz criterion
F-statistic
Prob(F-statistic)
6
1.06E-12
43.03562
10.29442
10.48797
2.928328
0.056241
Dado: (α = 5%)
H0 : No hay autocorrelación
Tenemos que rechazar la hipótesis nula, debido a que p es inferior al 5%. Como la
autocorrelación ha sido detectada se incluirá en la especificación de la ecuación una
nueva variable explicativa definida como AR(1) y que supondrá la inclusión de la
propia variable estimada, desplazada un período, como explicativa en nuestra
ecuación.
Como resultado de la corrección obtendremos la nueva estimación:
Dependent Variable: CP
Method: Two-Stage Least Squares
Date: 10/02/08 Time: 13:20
Sample (adjusted): 1982 2006
Included observations: 25 after adjustments
Convergence achieved after 14 iterations
Instrument list: CP(-1) I(-1) M(-1) P R(-1) G C
Lagged dependent
variable & regressors
added to instrument list
Variable
Coefficient
Std. Error
t-Statistic
Prob.
C
Y
CP(-1)
AR(1)
-263.7236
0.441013
0.419891
0.766056
157.0940
0.094651
0.127062
0.144650
-1.678763
4.659373
3.304609
5.295931
0.1080
0.0001
0.0034
0.0000
R-squared
Adjusted R-squared
S.E. of regression
F-statistic
Prob(F-statistic)
Inverted AR Roots
0.999445
0.999366
34.45489
12609.07
0.000000
Mean dependent var
S.D. dependent var
Sum squared resid
Durbin-Watson stat
.77
7
5546.536
1368.623
24929.93
1.513866
La cual someteremos a las pruebas realizadas para detectar la autocorrelación.
Date: 10/02/08 Time: 13:22
Sample: 1982 2006
Included observations: 25
Q-statistic
probabilities
adjusted for 1
ARMA term(s)
Autocorrelation
. |* .
. |* .
. | .
. | .
. |* .
. | .
. | .
. *| .
. | .
. |* .
. | .
. | .
|
|
|
|
|
|
|
|
|
|
|
|
Partial Correlation
. |* .
. |* .
. | .
. | .
. |* .
. | .
. *| .
. *| .
. | .
. |* .
. | .
. *| .
|
|
|
|
|
|
|
|
|
|
|
|
1
2
3
4
5
6
7
8
9
10
11
12
AC
PAC
Q-Stat
Prob
0.175
0.144
0.020
-0.011
0.067
0.043
-0.045
-0.138
-0.015
0.081
0.003
-0.044
0.175
0.117
-0.024
-0.029
0.078
0.029
-0.080
-0.137
0.052
0.122
-0.047
-0.084
0.8579
1.4696
1.4816
1.4857
1.6385
1.7054
1.7826
2.5421
2.5515
2.8474
2.8479
2.9501
0.225
0.477
0.686
0.802
0.888
0.939
0.924
0.959
0.970
0.985
0.991
Breusch-Godfrey Serial Correlation LM Test:
Obs*R-squared
1.419732
Probability
0.233448
Test Equation:
Dependent Variable: RESID
Method: Two-Stage Least Squares
Date: 10/02/08 Time: 13:23
Presample missing value lagged residuals set to zero.
Variable
Coefficient
Std. Error
t-Statistic
Prob.
C
Y
CP(-1)
AR(1)
RESID(-1)
11.70823
-0.021927
0.029258
-0.129683
0.299407
140.8591
0.064902
0.088352
0.185620
0.283029
0.083120
-0.337850
0.331156
-0.698645
1.057867
0.9346
0.7390
0.7440
0.4928
0.3027
R-squared
Adjusted R-squared
S.E. of regression
Sum squared resid
Log likelihood
Durbin-Watson stat
0.056789
-0.131853
34.28861
23514.18
-121.0545
2.069214
Mean dependent var
S.D. dependent var
Akaike info criterion
Schwarz criterion
F-statistic
Prob(F-statistic)
8
9.00E-09
32.22960
10.08436
10.32814
0.301042
0.873783
Como podemos apreciar, esta vez la ecuación está bien especificada porque no
presenta problemas de autocorrelación.
Haremos el mismo procedimiento para el resto de las ecuaciones.
La segunda ecuación estimada es: It = β0 + β1Yt + β2Rt + β3It-1 + u2t
β1>0 ; β2<0 ; 0< β3<1
Dependent Variable: I
Method: Two-Stage Least Squares
Date: 10/02/08 Time: 12:48
Sample (adjusted): 1981 2006
Included observations: 26 after adjustments
Instrument list: CP(-1) I(-1) M(-1) P R(-1) G C
Variable
Coefficient
Std. Error
t-Statistic
Prob.
C
Y
R
I(-1)
-608.7682
0.152547
16.76322
0.416010
348.5780
0.067765
13.24595
0.247910
-1.746433
2.251122
1.265536
1.678066
0.0947
0.0347
0.2189
0.1075
R-squared
Adjusted R-squared
S.E. of regression
F-statistic
Prob(F-statistic)
0.976190
0.972943
68.22973
298.6912
0.000000
Mean dependent var
S.D. dependent var
Sum squared resid
Durbin-Watson stat
1187.362
414.7946
102416.5
0.961018
La estimación indica que no todo está bien, debido a que el coeficiente de la variable
Rt debe ser menor que cero y la estimación realizada arroja un coeficiente mayor a
cero; por lo tanto haremos las pruebas respectivas para detectar posibles problemas
de autocorrelación, con respecto al resto de los parámetros éstos si cumplen las
restricciones en cuanto a sus signos y existe un elevado R2.
Para ello empezaremos usando el Correlograma de Residuos (View – Residual Test
- Correlogram Q – statics); el cual de una forma gráfica nos mostrará la existencia
de autocorrelación.
9
Date: 10/02/08 Time: 14:05
Sample: 1981 2006
Included observations: 26
Autocorrelation
. |****
. | .
. *| .
.**| .
.**| .
.**| .
***| .
. *| .
. |* .
. |* .
. | .
. | .
|
|
|
|
|
|
|
|
|
|
|
|
Partial Correlation
. |****
***| .
. | .
. *| .
. | .
.**| .
. *| .
. |* .
. *| .
. *| .
. *| .
. | .
|
|
1
2
3
4
5
6
7
8
9
10
11
12
|
|
|
|
|
|
|
|
|
|
AC
PAC
Q-Stat
Prob
0.501
-0.019
-0.186
-0.226
-0.197
-0.266
-0.324
-0.095
0.124
0.102
-0.031
-0.032
0.501
-0.360
0.011
-0.170
-0.053
-0.293
-0.183
0.091
-0.063
-0.155
-0.186
0.006
7.3093
7.3197
8.4128
10.103
11.444
14.028
18.040
18.404
19.060
19.529
19.575
19.628
0.007
0.026
0.038
0.039
0.043
0.029
0.012
0.018
0.025
0.034
0.052
0.074
Nuevamente estamos frente a una problema de autocorrelación. Para una forma más
acertada usaremos el test de Correlación serial de Breusch – Godfrey (View –
Residual Test – Serial Correlation LM Test).
10
Para este test, especificaremos el número de retardos (lags), a incluir en el contraste,
igual a 1; y luego aparecerá la tabla que presentaremos a continuación.
Breusch-Godfrey Serial Correlation LM Test:
Obs*R-squared
9.020146
Probability
0.002670
Test Equation:
Dependent Variable: RESID
Method: Two-Stage Least Squares
Date: 10/02/08 Time: 14:06
Presample missing value lagged residuals set to zero.
Variable
Coefficient
Std. Error
t-Statistic
Prob.
C
Y
R
I(-1)
RESID(-1)
-0.407773
-0.024219
3.204670
0.154692
0.311861
0.496417
0.019378
4.019184
0.120875
0.241972
-0.821434
-1.249816
0.797343
1.279765
1.288828
0.4206
0.2251
0.4342
0.2146
0.2115
R-squared
Adjusted R-squared
S.E. of regression
Sum squared resid
Log likelihood
Durbin-Watson stat
0.346929
0.222534
56.43592
66885.28
-138.9767
1.356673
Mean dependent var
S.D. dependent var
Akaike info criterion
Schwarz criterion
F-statistic
Prob(F-statistic)
1.04E-13
64.00516
11.07513
11.31707
2.788939
0.052949
Dado: (α = 5%)
H0 : No hay autocorrelación
Tenemos que rechazar la hipótesis nula, debido a que p es inferior al 5%. Como la
autocorrelación ha sido detectada se incluirá en la especificación de la ecuación una
nueva variable explicativa definida como AR(1) y que supondrá la inclusión de la
propia variable estimada, desplazada un período, como explicativa en nuestra
ecuación.
La tercera ecuación estimada es: Rt = λ0 + λ1Yt + λ2Mt-1 + λ3Pt + λ4Rt-1 + u3t
λ1>0 ; λ2<0 ; λ3>0 ; 0<λ4<1
11
Dependent Variable: R
Method: Two-Stage Least Squares
Date: 10/02/08 Time: 12:50
Sample (adjusted): 1981 2006
Included observations: 26 after adjustments
Instrument list: CP(-1) I(-1) M(-1) P R(-1) G C
Variable
Coefficient
Std. Error
t-Statistic
Prob.
C
Y
M(-1)
P
R(-1)
4.369016
0.002898
-0.000945
-0.149844
0.590448
4.315468
0.001780
0.001200
0.081726
0.164834
1.012408
1.627966
-0.786943
-1.833503
3.582087
0.3229
0.1184
0.4401
0.0809
0.0018
R-squared
Adjusted R-squared
S.E. of regression
F-statistic
Prob(F-statistic)
0.822420
0.788595
1.577878
23.81152
0.000000
Mean dependent var
S.D. dependent var
Sum squared resid
Durbin-Watson stat
12
6.162308
3.431753
52.28365
1.234408
UNIVERSIDAD NACIONAL DE TRUJILLO
ESCUELA PROFESIONAL DE ECONOMÍA
ECONOMETRÍA II
MODELO DE ECUACIONES SIMULTÁNEAS
EJERCICIO 20.2-20.3
Aquino Llatas,indira
Cordova Chavarry, Juan Carlos
Fernandes Rivera,Meliza
Haro Vega,Maribel
Arteaga Horna,Amadeo
Profesores responsables del curso:
Jorge Zegarra, Wilhem Guardia, Julio Reyes
13
EJERCICIO 20.2 CONSIDERE EL SIGUIENTE MODELO:
FUNCION CONSUMO:
Ct =β0+β1P+β2(W+w´)t+β3Pt-1+U1t
FUNCION DE INVERSION:
It=β4+β5Pt+β6Pt-1+β7Kt-1+U2t
DEMANDA DE TRABAJO:
Wt =β8+β9(y+T-w´)t+β10(Y+T-w´)t-1+β11t+U3t
IDENTIDAD:
Yt+Tt=Ct+It+Gt
IDENTIDAD:
Yt=W’t+Wt+Pt
IDENTIDAD:
Kt=Kt-1+It
Donde:
C=gasto de consumo
I=gasto de inversión
G=gasto de gobierno
P=Utilidades
W= nomina del sector privado
W´=nomina del gobierno
K=existencias del capital
T=impuestos
Y=ingresos después de impuestos
T=tiempo
U1, U2, U3=perturbaciones estocásticas.
En el ejemplo 18.6 se analizó, de manera breve, el modelo pionero de Klein.
Inicialmente, el modelo fue estimado por el periodo 1920-1941.La información está
dada en la tabla 20.5
14
Tabla 20.5
obs
C*
P
W
I
Kt-1
X
W´
G
T
1920
1921
1922
1923
1924
1925
1926
1927
1928
1929
1930
1931
1932
1933
1934
1935
1936
1937
1938
1939
1940
1941
39.8
41.9
45
49.2
50.6
52.6
55.1
56.2
57.3
57.8
55
50.9
45.6
46.5
48.7
51.3
57.7
58.7
57.5
61.6
65
69.7
12.7
12.4
16.9
18.4
19.4
20.1
19.6
19.8
21.1
21.7
15.6
11.4
7
11.2
12.3
14
17.6
17.3
15.3
19
21.1
23.5
28.8
25.5
29.3
34.1
33.9
35.4
37.4
37.9
39.2
41.3
37.9
34.5
29
28.5
30.6
33.2
36.8
41
38.2
41.6
45
53.3
2.7
-0.2
1.9
5.2
3
5.1
5.6
4.2
3
5.1
1
-3.4
-6.2
-5.1
-3
-1.3
2.1
2
-1.9
1.3
3.3
4.9
180.1
182.8
182.6
184.5
189.7
192.7
197.8
203.4
207.6
210.6
215.7
216.7
213.3
207.1
202
199
197.7
199.8
201.8
199.9
201.2
204.5
44.9
45.6
50.1
57.2
57.1
61
64
64.4
64.5
67
61.2
53.4
44.3
45.1
49.7
54.4
62.7
65
60.9
69.5
75.7
88.4
2.2
2.7
2.9
2.9
3.1
3.2
3.3
3.6
3.7
4
4.2
4.8
5.3
5.6
6
6.1
7.4
6.7
7.7
7.8
8
8.5
2.4
3.9
3.2
2.8
3.5
3.3
3.3
4
4.2
4.1
5.2
5.9
4.9
3.7
4
4.4
2.9
4.3
5.3
6.6
7.4
13.8
3.4
7.7
3.9
4.7
3.8
5.5
7
6.7
4.2
4
7.7
7.5
8.3
5.4
6.8
7.2
8.3
6.7
7.4
8.9
9.6
11.6
Nuestra ecuación plantea que hay problemas de simultaneidad por que las variables
w,p,y Y se presentan a su vez como variables endógenas y exógenas en el modelo. pero
para saber con exactitud si en las ecuaciones planteadas si existen problemas de
simultaneidad elaboramos el cuadro de condición de orden de identificación como
expresa el cuadro siguiente.
15
Determine si están identificadas las funciones dadas.
Nº
Ecuación 1
Ecuación 2
Ecuación 3
Variable
endógena
incluida g
Variable
predeterminad
a incluida k
Variable predeterminada
excluida K-k
3
3
7-3=4
2
3
7-3=4
2
4
7-4=3
G=6(C,I,W,P,Y,
K)
Identificación
K-k=4>g-1=2
sobreidentificad
a
K-k=4>g-1=1
sobreidentificad
a
K-k=3>g-1=1
sobreidentificad
a
Método
MC2T
MC2T
MC2T
K=7(Pt-1 , Kt-1, T,W´,t,G,Const)
El modelo de orden de identificación nos expresa que existe simultaneidad, en vista que
las tres ecuaciones expresan problemas de identificación sobre identificada. Para la cual
usaremos el método de MC2T. Este método está diseñado en especial para ecuaciones
de modelos sobre identificadas.
E aquí de cómo un modelo desarrollado a través de MCO, nos permite darnos cuenta
de cómo estas ecuaciones presentan problemas de correlación a través del coeficiente
Durbin Watson. Cosa que las ecuaciones que contienen simultaneidad son aquellas
variables regresoras (endógenas) están correlacionadas con los errores.
16
System: UNTITLED
Estimation Method: Least Squares
Date: 10/02/08 Time: 23:52
Sample: 1921 1941
Included observations: 21
Total system (balanced) observations 63
C(1)
C(2)
C(3)
C(4)
C(5)
C(6)
C(7)
C(8)
C(9)
C(10)
C(11)
C(12)
Coefficient
Std. Error
t-Statistic
Prob.
16.23660
0.192934
0.796219
0.089885
10.12579
0.479636
0.333039
-0.111795
-0.065899
0.439477
0.146090
0.130245
1.302698
0.091210
0.039944
0.090648
5.465547
0.097115
0.100859
0.026728
1.145786
0.032408
0.037423
0.031910
12.46382
2.115273
19.93342
0.991582
1.852658
4.938864
3.302015
-4.182749
-0.057514
13.56093
3.903734
4.081604
0.0000
0.0393
0.0000
0.3261
0.0697
0.0000
0.0018
0.0001
0.9544
0.0000
0.0003
0.0002
Determinant residual covariance
0.196732
Equation: CP=C(1)+C(2)*P+C(3)*Z1+C(4)*P(-1)
Observations: 21
R-squared
0.981008 Mean dependent var
Adjusted R-squared
0.977657 S.D. dependent var
S.E. of regression
1.025540 Sum squared resid
Durbin-Watson stat
1.367474
Equation: I=C(5)+C(6)*P+C(7)*P(-1)+C(8)*K1
Observations: 21
R-squared
0.931348 Mean dependent var
Adjusted R-squared
0.919233 S.D. dependent var
S.E. of regression
1.009447 Sum squared resid
Durbin-Watson stat
1.810184
Equation: W=C(9)+C(10)*X+C(11)*X(-1)+C(12)*TIEMPO
Observations: 21
R-squared
0.987414 Mean dependent var
Adjusted R-squared
0.985193 S.D. dependent var
S.E. of regression
0.767147 Sum squared resid
Durbin-Watson stat
1.958434
53.99524
6.860866
17.87945
1.266667
3.551948
17.32270
36.36190
6.304401
10.00475
Como vemos la ecuación del consumo el Durbin Watson es cercano a 1 por lo que a simple
vista existe correlación positiva.
A continuación mostramos el modelo de MC2T
Modelo estimado para este sistema:
17
System: ECU1
Estimation Method: Two-Stage Least Squares
Date: 10/02/08 Time: 18:11
Sample: 1921 1941
Included observations: 21
Total system (balanced) observations 63
C(1)
C(2)
C(3)
C(4)
C(5)
C(6)
C(7)
C(8)
C(9)
C(10)
C(11)
C(12)
Coefficient
Std. Error
t-Statistic
Prob.
16.58500
0.015893
0.809125
0.218519
20.17597
0.153539
0.613095
-0.157324
-0.315071
0.422769
0.167614
0.130622
1.471313
0.131484
0.044839
0.119489
8.350591
0.191814
0.180240
0.039995
1.179826
0.042503
0.047443
0.032708
11.27225
0.120873
18.04495
1.828772
2.416113
0.800460
3.401546
-3.933604
-0.267048
9.946738
3.532990
3.993562
0.0000
0.9043
0.0000
0.0733
0.0193
0.4272
0.0013
0.0003
0.7905
0.0000
0.0009
0.0002
Determinant residual covariance
0.276685
Equation: CP=C(1)+C(2)*P+C(3)*Z1+C(4)*P(-1)
Instruments: P(-1) K1 T W1 TIEMPO G C
Observations: 21
R-squared
0.976614 Mean dependent var
Adjusted R-squared
0.972487 S.D. dependent var
S.E. of regression
1.138014 Sum squared resid
Durbin-Watson stat
1.484317
Equation: I=C(5)+C(6)*P+C(7)*P(-1)+C(8)*K1
Instruments: P(-1) K1 T W1 TIEMPO G C
Observations: 21
R-squared
0.885815 Mean dependent var
Adjusted R-squared
0.865665 S.D. dependent var
S.E. of regression
1.301852 Sum squared resid
Durbin-Watson stat
2.085554
Equation: W=C(9)+C(10)*X+C(11)*X(-1)+C(12)*TIEMPO
Instruments: P(-1) K1 T W1 TIEMPO G C
Observations: 21
R-squared
0.987165 Mean dependent var
Adjusted R-squared
0.984899 S.D. dependent var
S.E. of regression
0.774712 Sum squared resid
Durbin-Watson stat
2.076255
18
53.99524
6.860866
22.01630
1.266667
3.551948
28.81191
36.36190
6.304401
10.20303
2
Se observa que el modelo se ajusta bastante bien por lo que el R es alto en las tres funciones:
Consumo inversión y demanda de trabajo cuyos estadísticos t son significativos, al igual que
algunas probabilidades menores que el 10% de significancia.
Para la función de consumo se dice que el 97.66% de las variables predeterminadas de esta
función en el modelo explican el comportamiento del consumo.
Para la función de inversión se dice que el 88.58% de las variables predeterminadas en esta
función en el modelo explican el comportamiento de la inversión.
De igual manera las variables exógenas explican el comportamiento de la demanda de trabajo.
2
Cuyo R -ajustado es alto y las t también.
A continuación se muestra la ecuación formulada para cada variable:
CP=16.59+0.016P+0.81(w+w´)+0.22Pt-1
Dándonos a entender que tanto p, (w+w´,pt-1) tienen relación positiva o directa con el consumo
por ejemplo: a media que el consumo aumenta una unidad adicional el p (utilidades) aumentan
en un 0.016 billones de dólares.
I=20.18+0.15P+0.61Pt-1 —0.16Kt-1
Dándonos a entender que tanto (p,pt-1 ) tienen relación positiva y directa con la inversión
mientras que el kt-1 tiene una relación negativa con la inversión.
W=-0.32+0.42(y+t-w´)t+0.17(y+t-w´)t-1 +C(12)*TIEMPO
Así de igual manera (y+t-w´)t (y+t-w´)t-1 y el tiempo tienen relación positiva y directa con la
función de demanda de trabajo.
19
EJERCICIOS DE PREGUNTAS Nº 20.3
Considere el siguiente modelo keynesiano modificado de determinación del ingreso:
Ct=B10 +B11 Yt +Ut
It = B20 +B21Yt +B22 Yt-1 +u2t
Y= Ct + It + Gt
Donde:
C= gasto de consumo
I= Gasto de inversion
Y= Ingreso
G= Gasto del gobierno
a) Obténgase las ecuaciones de la forma reducida y determine cuales de las ecuaciones
anteriores están identificadas (en forma exacta o sobre identificadas).
b) ¿Cuál método puede utilizarse para estimar los parámetros de la ecuación sobre
identificada y de la ecuación exactamente identificada? Justifique la respuesta.
Para desarrollar el siguiente ejercicio se deberá primero pasar de su forma estructural a su
forma reducida paso que lo realizamos a continuación.
FORMA RESUMIDA DE LA ECUACIÓN
Y = B10 +B11 Yt +Ut + B20 +B21Yt +B22 Yt-1 +u2t +Gt
(1-B11-B21)Y=B10 +B20 +B22Yt-1 +G +ut +u2t
Y=
+
Y=TT1 + TT2 +V1
+
Ecuación reducida
A continuación desarrollamos las ecuaciones a través del cuadro de ecuación de
orden de identificación:
Nº
Ecuación 1
Ecuación 2
G=3(C,I,Y)
Variable
endógena
incluida g
Variable
predeterminad
a incluida k
Variable predeterminada
excluida K-k
Identificación
2
1
3-1=2
2
2
3-2=1
K-k=2>g-1=1
sobre identificada
K-k=1>g-1=1
Exactamente
identificada
K=3(Yt-1 ,G, Const)
Luego formulamos la operación en el programa computarizado en este caso
utilizaremos
El programa Eviews5 formulación de MCI y obtenemos:
20
Método
MC2T
MCI
UNIVERSIDAD NACIONAL DE TRUJILLO
ESCUELA PROFESIONAL DE ECONOMÍA
ECONOMETRÍA II
MODELO DE ECUACIONES SIMULTÁNEAS
EJERCICIO 20.3
CRUZ VEGA YOBER DANGELO
GIL RUIZ ANA ERI
VARGAS ALFARO CHRISTIAN
Profesores responsables del curso:
Jorge Zegarra, Wilhem Guardia, Julio Reyes
21
20.3 CONSIDERESE EL SIGUIENTE MODELO KEYNESIANO MODIFICADO
DE DETERMINACION DEL INGRESO:
CPt = β10 + β11Yt+ µ1t
It = β20 + β21Yt + β22Yt-1 + µ2t
Yt = CPt + It + Gt
Donde:
C = gasto de consumo privado
I = Gasto de inversion
Y = ingreso (PBI)
G = gasto del gobierno
Gt y Yt-1 = se suponen predeterminadas
a) Obténgase las ecuaciones de la forma reducida y determínense cuales de las
ecuaciones anteriores están identificadas
Ecuaciones de la forma reducida:
CONSUMO PRIVADO:
CPt = β10 + β11Yt+ µ1t
CPt = β10 + β11 (CPt + It + Gt) + µ1t
CPt = β10 + β11CPt + β11 It + β11 Gt + µ1t
CPt - β11CPt = β10 + β11 It + β11 Gt + µ1t
CPt (1- β11) = β10 + β11 It + β11 Gt + µ1t
CPt =
+
It +
Gt +
CPt = π1+π2 It + π3 Gt + ν1t
Donde:
π1 =
;
π2 =
;
INVERSION:
It = β20 + β21Yt + β22Yt-1 + µ2t
It = β20 + β21 (CPt + It + Gt)+ β22Yt-1 + µ2t
22
π3 =
It = β20 + β21 CPt + β21 It + β21 Gt+ β22Yt-1 + µ2t
It - β21 It = β20 + β21 CPt + β21 Gt + β22Yt-1 + µ2t
It (1 - β21 ) = β20 + β21 CPt + β21 Gt + β22Yt-1 + µ2t
It=
+
CPt +
Gt+
Yt-1 +
It = π4+π5 CPt + π6 Gt +π7Yt-1 + ν2t
Donde:
π4 =
;
π5 =
π6 =
;
;
π7 =
Determine si están identificadas las ecuaciones anteriores:
Variables
endógenas
incluidas,
g
Variable
Variables
predeterminad
predeterminadas
a
incluída, k
excluída, K-k
Identificación
MÉTODO
K-k=2>g-1=1
Ecuación 1
Ecuación 2
G=3(CP, I, Y )
2
2
1
2
2
sobreidentificada
K-k=1=g-1=1
1
exactamente
identifacada
K=3 (G, Y(-1) y la Constante)
MC2T
MC2T , MCI
b) ¿Cuál método puede utilizarse para estimar los parámetros de la ecuación sobre y
exactamente identificada? Justifique la respuesta
Se utiliza el método de mínimos cuadrados en 2 etapas (MC2E), ya que al determinar
la identidad de las ecuaciones obtenemos como resultado que la “Ecuación 1 es
SOBREIDENTIFICADA” y la “Ecuación 2 es EXACTAMENTE IDENTIFICADA”; por lo que
para estimar las ecuaciones simultaneas debemos usar (MC2T); ya que no se puede
usar (MCI) porque solo la Ecuación 2 es exactamente identificada.
ESTIMANDO ECUACIONES SIMULTÁNEAS (MC2T)
Para estimar el modelo utilizando MC2T elegir anticlik/System/OK, luego
digitar las ecuaciones en la parte superior una por una, continuando con las
variables predeterminadas (exógenas) incluyendo la constante. Estimate, después
elegimos Method/Two-Stage Least Square…
23
Pasos que se van a mostrar a continuación uno por uno para mejor comprensión
en la realización de la estimación mediante el método (MC2T).
PASO1:
PASO2:
PASO3:
24
Como se puede observar en el modelo estimado hay problemas de autocorrelación; es
decir el Durbin-Watson no es muy cercano a 2 en la ecuación de consumo y es más
grave aun en el caso de la ecuación de inversión donde el Durbin-Watson es cercano a
0 “relación positiva”. Así como también no todos los estadísticos “t” son significativos
como {c(4) y c(5)}; por lo que sería conveniente estimar el modelo ecuación por
ecuación para poder realizar los cambios necesarios y obtener mejores resultados; es
decir más ajustados.
25
ESTIMANDO ECUACION POR ECUACION (MC2T)
Ecuación 1 CONSUMO:
PASO1:
PASO2:
26
PASO3:
Como podemos ver el modelo se ajusta muy bien, estamos ante un R-cuadrado alto
(0.956) y los estadísticos t y F son muy significativos tanto al (1, 5 y 10%). El problema
que se presenta en el modelo es de autocorrelación (Durbin- Watson stat ya que no es
precisamente cercano a 2), para lo cual agregaremos un rezago; es decir AR(1).
27
Ecuación 2 INVERSION:
PASO1:
PASO2:
28
PASO3:
Como podemos ver el modelo se ajusta, estamos ante un R-cuadrado de (0.813) y los
estadísticos “t” no son significativos al (1, 5 y 10%). Por el contrario el estadístico “F” si
se muestra muy significativo. Otro problema que se presenta en el modelo es de
autocorrelación (Durbin- Watson stat ya que es cercano a 0 RELACION POSITIVA), para
tratar de corregir los errores que se presentan en el modelo agregaremos un rezago;
es decir AR(1).
29
EJEMPLO APLICATIVO (datos trimestrales 1980-1 2008-2)
La siguiente tabla contiene información correspondiente al periodo 1980:01- 2008:02 relativa a
las variables macroeconómicas: Gasto Público (G), Consumo Privado Nacional (C),
Importaciones (M), PBI(Y), Recaudación tributaria (T), Exportaciones (X) e inversión Privada
Nacional (I) a precios constantes de 1994.
Supongamos que las variables macroeconómicas anteriores pueden relacionarse según el
siguiente sistema de ecuaciones simultáneas
Realizar la identificación de los parámetros del sistema a través de las condiciones de orden y
estimar la forma estructural del modelo utilizando los métodos de los mínimos cuadrados en
dos etapas (MC2E) y en tres etapas.
Estimar también el modelo ecuación por ecuación.
30
31
32
PASO 1:
Hemos determinado si las ecuaciones dadas están:
Sobreidentificadas, identificadas perfectas o no identificadas, en el siguiente cuadro:
G=5 (CP,I,T,M,Y)
K=6
(CP(-1),Y(-1),M(-1),X, G, c)
Ecuaciones
Endógenas
Incluidas
g
Exógenas
incluidas
k
Exógenas
excluidas
K-k
Identificación
Ecuac. 1
3
2
6-2=4
K-k(<,>,=)g-1
4>2 (sobreiden)
Ecuac. 2
1
2
6-2=4
4>0 (sobreiden)
Ecuac. 3
2
1
6-1=5
5>1 (sobreiden)
Ecuac. 4
2
3
6-3=3
3>1 (sobreiden)
PASO 2:
Luego determinamos el sistema de 2 etapas:
-Asumiendo que tenemos la información en el eviews, damos clic derecho en la ventana de
worfile
new object system, introducimos en la ventana del system las ecuaciones sobre
identificas e identificadas:
Después damos clic en Estímate donde:
33
En la opción Method
Two-Stage least squares (MC2E)
34
35
PASO 3:
Luego determinamos el sistema de 3 etapas:
-Asumiendo que tenemos la información en el eviews, damos clic derecho en la ventana de
worfile
new object system, introducimos en la ventana del system las ecuaciones sobre
identificas e identificadas:
Después damos clic en estímate donde:
En la opción Method
three-Stage least squares (MC3E)
36
37
PASO 4:
Ahora estimamos ecuación por ecuación:
1. Ecuación 1 “CONSUMO”: Con los datos trimestrales que teníamos de la economía
peruana 1980q1-2008q2
Elegimos “Y” y “ CP” para estimar la ecuación 1 ,damos clic derecho: open
38
as Equation
Luego en instrument list introducimos las variables exógenas (cp(-1) y(-1) m(-1) g x c )
EXPLICACIÒN En la siguiente estimación de ecuación podemos ver que los “t” son todos
significativos tanto al (1, 5 y 10%); con un R cuadrado de 0.956 lo que nos muestra que las
variables explicativas logran explicar de una manera eficiente la variable dependiente; asi como
también tenemos un durbin-Watson cercano a 2 por lo el error de auto correlación es bajo ya
que se aproxima a 2. La medida de confiablidad o precisión de los estimadores medido por sus
39
errores estándar es muy bajo lo cual muestra que son confiables “error estándar para
(CP=1.5)”
2. Ecuación 2 “INVERSIÓN”: Con los datos trimestrales que teníamos de la economía
peruana 1980q1 - 2008q2
Elegimos “Y” y “I” para estimar la ecuación 2 ,damos clic derecho: open
40
as Equation
Aquí se presenta problemas con el Durbin-watson stat es muy bajo 0.826 (relación
2
positiva) así como el R no es muy alto 0.786 para lo cual decidimos agregar una
variable exógena que pueda explicar Y(-1)
-Donde vemos que el Durbin-watson aun presenta problemas por lo que agregamos un
rezago.
41
EXPLICACIÒN En la siguiente estimación de ecuación podemos ver que los “t” son todos
significativos tanto al (1, 5 y 10%) excepto la constante; con un R cuadrado de 0.929 lo que
nos muestra que las variables explicativas logran explicar de una manera eficiente la variable
dependiente; así como también tenemos un durbin-Watson cercano a 2 por lo el error de auto
correlación es bajo ya que se aproxima a 2. La medida de confiablidad o precisión de los
estimadores medido por sus errores estándar es muy bajo lo cual muestra que son confiables
“error estándar para (I=0.144, Y(-1)=0.04, AR(1)=0.073)”
3. Ecuación 3 “IMPUESTOS”: Con los datos trimestrales que teníamos de la economía
peruana 1980q1-2008q2
42
Donde se presenta problemas con el Durbin-watson stat que es muy bajo 0.538
2
(relación positiva) así como el R no es muy alto 0.755 para lo cual decidimos agregar
un rezago
43
EXPLICACIÒN En la siguiente estimación de ecuación podemos ver que los “t” son todos
significativos tanto al (1, 5 y 10%) excepto la constante que solo es significativa a (5 y 10 %);
con un R cuadrado de 0.869 lo que nos muestra que las variables explicativas logran explicar
de una manera eficiente la variable dependiente; así como también tenemos un durbinWatson cercano a 2 por lo el error de auto correlación es bajo ya que se aproxima a 2. La
medida de confiablidad o precisión de los estimadores medido por sus errores estándar es muy
bajo lo cual muestra que son confiables “error estándar para (T=0.601; AR(1)=0.06)”
4. Ecuación 4 “IMPORTACIÓNES”: Con los datos trimestrales que teníamos de la
economía peruana 1980q1-2008q2
Se presentan problemas con el durbin-Watson 0.802 que es muy bajo y muestra
(RELACION POSITIVA) para lo cual agregamos variables exógenas “m(-1) y y(-1)”
44
EXPLICACIÒN En la siguiente estimación de ecuación podemos ver que los “t” son todos
significativos tanto al (1, 5 y 10%); con un R cuadrado de 0.835 lo que nos muestra que las
variables explicativas logran explicar de una manera eficiente la variable dependiente; así como
también tenemos un durbin-Watson cercano a 2 por lo el error de auto correlación es bajo ya
que se aproxima a 2. La medida de confiablidad o precisión de los estimadores medido por sus
errores estándar es muy bajo lo cual muestra que son confiables “error estándar para
(M=1.352; M(-1)=1.334; Y(-1)=0.11)”
45
UNIVERSIDAD NACIONAL DE TRUJILLO
ESCUELA PROFESIONAL DE ECONOMÍA
ECONOMETRÍA II
MODELO DE ECUACIONES SIMULTÁNEAS
EJERCICIO 20.14
ALVAREZ LEYTON MARLON
CAMONES ARANA VICTOR
CASTILLO VASQUEZ ELVIS
COSTILLA ALVA LITO
CHÁVEZ MARTÍNEZ HENRY
IBAÑEZ ALVARADO CRISTIAN
ESCUDERO QUIÑONES JUNIOR
VALERIANO SAMORA SARA
Profesores responsables del curso:
Jorge Zegarra, Wilhem Guardia, Julio Reyes
46
20.14. Ejercicio de Clase: Considérese el siguiente modelo
macroeconómico simple para la economía estadounidense, digamos
durante el período 1980-2007.
Función de consumo privado:
Ct = α0 + α1Yt + α2Ct−1 + u1t
α1 > 0, 0 < α2 < 1
Función inversión privada bruta:
t = β0 + β1Yt + β2Rt + β3 It−1 + u2t
β1 > 0, β2 < 0, 0 < β3 < 1
Demanda del dinero en función
Rt = λ0 + λ1Yt + λ2Mt−1 + λ3 Pt + λ4Rt−1 + u3t
λ1 > 0, λ2 < 0, λ3 > 0, 0 < λ4 < 1
Identidad de ingreso:
Yt = Ct + It + Gt
Donde C = verdadero consumo privado; = la verdadera inversión gruesa privada, la G
= verdaderos gastos públicos, Y = el verdadero PBI, M = M2 el dinero suministro en
precios corrientes, R = la tasa de interés a largo plazo (el %), y P = el Índice de precios
al consumidor. Las variables endógenas son C, yo, la R, y Y. Las variables
predeterminadas son: Ct-1, It-1, Mt-1, Punto, Rt-1, y Gt más el término interceptar. La
u es los términos (las condiciones) de error.
Obs.
1980
1981
1982
1983
1984
1985
1986
1987
1988
1989
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
2001
2002
2003
2004
2005
2006
2007
M
1.6
1.756,00
1.91
2.126,00
2.31
2.496,00
2.732,00
2.831,00
2.994,00
3.158,00
3.278,00
3.378,00
3.432,00
3.483,00
3.499,00
3.642,00
3.821,00
4.035,00
4.382,00
4.639,00
4.922,00
5.434,00
5.779,00
6.071,00
6.422,00
6.692,00
7.036,00
7.447,00
Y
R
2.79
3.128
3.255
3.537
3.933
4.22
4.463
4.74
5.104
5.484
5.803
5.996
6.338
6.657
7.072
7.398
7.817
8.304
8.747
9.268
9.817
10.128
10.47
10.961
11.686
12.422
13.178
13.808
P
12
14
11
9
10
7
6
6
7
8
8
5
3
3
4
6
5
5
5
5
6
3
2
1
1
3
5
4
47
82
91
97
100
104
108
110
114
118
124
131
136
140
145
148
152
157
161
163
167
172
177
180
184
189
195
202
207
I
G
CO
484
541
531
570
670
715
741
754
803
845
847
800
852
934
1.035
1.111
1.213
1.328
1.473
1.607
1735.5
1614.3
1582.1
1664.1
1888.6
2086.1
2220.4
2130.4
570
631
684
736
801
878
942
998
1037
1100
1181
1236
1271
1293
1328
1372
1422
1488
1541
1634
1721.6
1825.6
1961.1
2092.5
2216.8
2355.3
2508.1
2674.8
2.796
3.131
3.259
3.535
3.933
4.213
4.453
4.743
5.108
5.489
5.803
5.986
6.319
6.642
7.054
7.401
7.813
8.318
8.79
9.299
9817
10128
10469.6
10960.8
11685.9
12421.9
13178.4
13807.5
DESARROLLO
Pregunta a).La utilización de la condición de orden de la identificación, determínese
cuál de las cuatro ecuaciones es exactamente identificados o sobreidentificada.
G=4 (Ct , It, Rt, Yt)
K=7 (Ct−1, It−1, Mt−1, Pt, Gt, Rt−1, constante)
Nº
ECUACION
VARIABLES
ENDOGENAS
INCLUIDAS,
G
VARIABLE
PREDETERMINADAS
EXCLUIDA, K
VARIABLE
PREDETERMINADA
EXCLUIDA, K-K
IDENTIFICACIÓN
MÉTODO
Ecuación 1
2
2
7-2=5
K-k=5>g-1=1
sobreidentificada
MC2E
Ecuación 2
3
2
7-2=5
K-k=5>g-1=2
sobreidentificada
MC2E
Ecuación 3
2
4
7-4=3
K-k=3>g-1=1
sobreidentificada
MC2E
Pregunta b) ¿Qué método(s) se utiliza(n) para calcular las ecuaciones identificadas?
Siguiendo los criterios de identificación se puede observar que las tres ecuaciones están
sobre identificadas, por tanto se utiliza el método de mínimos cuadrados en 2 etapas
(MC2E).
48
Pregunta c) Obténgase datos apropiados para fuentes privadas y/o gubernamentales,
estímese el modelo y coméntese los resultados.
System: SYS01
Estimation Method: Two-Stage Least Squares
Date: 09/30/08 Time: 18:28
Sample: 1981 2007
Included observations: 27
Total system (balanced) observations 81
C(1)
C(2)
C(3)
C(4)
C(5)
C(6)
C(7)
C(8)
C(9)
C(10)
C(11)
C(12)
Coefficient
Std. Error
t-Statistic
Prob.
-2184.060
443.1025
0.777841
-546.2581
78.13566
39.58474
0.757912
7.972803
1.596955
-2.330683
-0.061772
0.617496
1239.597
195.0610
0.122472
567.5696
43.67582
49.35482
0.133720
18.45082
3.390883
2.825776
0.220277
0.320323
-1.761912
2.271609
6.351187
-0.962451
1.788991
0.802044
5.667919
0.432111
0.470956
-0.824794
-0.280430
1.927731
0.0825
0.0262
0.0000
0.3392
0.0780
0.4253
0.0000
0.6670
0.6392
0.4123
0.7800
0.0580
Determinant residual covariance
1.54E+11
Equation: CO=C(1)+C(2)*Y+C(3)*CO(-1)
Instruments: CO(-1) I(-1) M(-1) R(-1) G C
Observations: 27
R-squared
0.902781 Mean dependent var
Adjusted R-squared
0.894679 S.D. dependent var
S.E. of regression
1762.010 Sum squared resid
Durbin-Watson stat
1.980989
Equation: I=C(4)+C(5)*Y+C(6)*R+C(7)*I(-1)
Instruments: CO(-1) I(-1) M(-1) R(-1) G C
Observations: 27
R-squared
0.760634 Mean dependent var
Adjusted R-squared
0.729412 S.D. dependent var
S.E. of regression
371.7532 Sum squared resid
Durbin-Watson stat
1.945866
Equation: R=C(8)+C(9)*Y+C(10)*M(-1)+C(11)*P+C(12)*R(-1)
Instruments: CO(-1) I(-1) M(-1) R(-1) G C
Observations: 27
R-squared
0.807483 Mean dependent var
Adjusted R-squared
0.772480 S.D. dependent var
S.E. of regression
1.437976 Sum squared resid
Durbin-Watson stat
1.602805
49
3428.903
5429.387
74512331
908.6025
714.6623
3178611.
5.629630
3.014684
45.49106
La ecuación de consumo privado, inversión privada bruta, y demanda de dinero
ajustan en: primero el 90.28 por ciento de la variación de la endógena es
explicado por el modelo (las variables exógenas), el segundo modelo el 76.06%
de la variación de la endógena es explicado por
el modelo (las variables
exógenas), mientras que el tercer modelo el 80.75% de la demanda de dinero es
explicado por el modelo(variables exógenas). Sin embargo, se debe tener
cuidado al interpretar los resultados, pues el tercer modelo muestra
autocorrelación positiva (Estadístico Durbin-Watson 1.603) y posiblemente
haya, también, problemas de simultaneidad.
Dependent Variable: CO
Method: Two-Stage Least Squares
Date: 10/02/08 Time: 15:28
Sample (adjusted): 1981 2007
Included observations: 27 after adjustments
CO=C(1)+C(2)*Y+C(3)*CO(-1)
Instrument list: CO(-1) I(-1) M(-1) R(-1) G C
C(1)
C(2)
C(3)
R-squared
Adjusted R-squared
S.E. of regression
Durbin-Watson stat
Coefficient
Std. Error
t-Statistic
Prob.
-2184.060
443.1025
0.777841
1239.597
195.0610
0.122472
-1.761912
2.271609
6.351187
0.0908
0.0324
0.0000
0.902781
0.894679
1762.010
1.980989
Mean dependent var
S.D. dependent var
Sum squared resid
50
3428.903
5429.387
74512331
Dependent Variable: I
Method: Two-Stage Least Squares
Date: 10/02/08 Time: 15:31
Sample (adjusted): 1981 2007
Included observations: 27 after adjustments
I=C(1)+C(2)*Y+C(3)*R+C(4)*I(-1)
Instrument list: CO(-1) I(-1) M(-1) R(-1) G C
C(1)
C(2)
C(3)
C(4)
R-squared
Adjusted R-squared
S.E. of regression
Durbin-Watson stat
Coefficient
Std. Error
t-Statistic
Prob.
-546.2581
78.13566
39.58474
0.757912
567.5696
43.67582
49.35482
0.133720
-0.962451
1.788991
0.802044
5.667919
0.3458
0.0868
0.4307
0.0000
0.760634
0.729412
371.7532
1.945866
Mean dependent var
S.D. dependent var
Sum squared resid
908.6025
714.6623
3178611.
Dependent Variable: R
Method: Two-Stage Least Squares
Date: 09/30/08 Time: 22:36
Sample (adjusted): 1981 2007
Included observations: 27 after adjustments
R=C(8)+C(9)*Y+C(10)*M(-1)+C(11)*P+C(12)*R(-1)
Instrument list: CO(-1) I(-1) R G C
C(8)
C(9)
C(10)
C(11)
C(12)
R-squared
Adjusted R-squared
S.E. of regression
Durbin-Watson stat
Coefficient
Std. Error
t-Statistic
Prob.
-186.7729
-24.78825
16.99774
1.899300
5.848174
678.6717
97.23364
71.72446
7.056567
16.97765
-0.275204
-0.254935
0.236987
0.269154
0.344463
0.7857
0.8011
0.8149
0.7903
0.7338
-8.428306
10.142543
10.06315
1.376468
Mean dependent var
5.629630
S.D. dependent var
Sum squared resid
3.014684
2227.874
51
UNIVERSIDAD NACIONAL DE TRUJILLO
ESCUELA PROFESIONAL DE ECONOMÍA
ECONOMETRÍA II
MODELO DE ECUACIONES SIMULTÁNEAS
EJERCICIO 20.10
Aguilar Polo Elias
Alvarado Santisteban Ana
Castillo Cruz Kennet
Diestra Acosta Rocio
Echevarria Flores Romina
Espejo Rivera Ivar
Soto Urquiaga Patricia
Profesores responsables del curso:
Jorge Zegarra, Wilhem Guardia, Julio Reyes
52
Consideremos el siguiente modelo:
ECUACION 1: Rt= B0 + B1Mt + B2Yt +ut
ECUACION 2: Yt= α0 + α1Rt + α2It +u2t
Donde:
M = Oferta Monetaria; R = Tasa de Interés; Y = Producto Bruto Interno; I = la
inversión; µ=termino de error
Considerando I (inversión domestica) y M exógenamente, determínese la
identificación del sistema. Utilizando la información de la tabla 20.2, estímese
la(os) parámetro (s) de la(s) ecuación(es) identificada(s).
Observaciones
1970
1971
1972
1973
1974
1975
1976
1977
1978
1979
1980
1981
1982
1983
1984
1985
1986
1987
1988
1989
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
Y
3578
3697.7
3998.4
4123.4
4099
4084.4
4311.7
4511.8
4760.6
4912.1
4900.9
5021
4913.3
5132.3
5505.2
5717.1
5912.4
6113.3
6368.4
6591.9
6707.9
6676.4
6880
7062.6
7347.7
7343.8
7813.2
8159.5
8515.7
8875.8
R
6.562
4.511
4.466
7.178
7.926
6.122
5.266
5.51
7.572
10.017
11.374
13.776
11.084
8.75
9.8
7.66
6.03
6.05
6.92
8.04
7.47
5.49
3.57
3.14
4.66
5.59
5.09
5.18
4.85
4.76
M
626.4
710.1
802.1
855.2
901.9
1015.9
1151.7
1269.9
1365.5
1473.1
1599.1
1754.6
1909.5
2126
2309.7
2495.4
2732.1
2831.1
2994.3
3158.4
3277.6
3376.8
3430.7
3484.4
3499
3641.9
3813.3
4028.9
4380.6
4643.7
I
436.2
485.8
543
606.5
561.7
462.2
555.5
639.4
713
735.4
655.3
715.6
615.2
673.7
871.5
863.4
857.7
879.3
902.8
936.5
907.3
829.5
899.8
977.9
1107
1140.6
1242.7
1393.3
1566.8
1669.7
*Donde todas las variables están expresadas en miles de millones de dólares.
53
APLICANDO TEST DE IDENTIFICACIÓN
Variables
Endógenas
Incluidas, g
Variables
Variables
Predeterminadas Predeterminadas Identificación
Excluidas, k
Incluidas, K-k
Método
Ecuación 1
2
2
3-2=1
K-k=g-1=1,
Exactamente
Identificada
MC2E
Ecuación 2
2
2
3-2=1
K-k=g-1=1,
Exactamente
Identificada
MC2E
G= 2 (Rt, Yt)
K=3 (Mt, It, Cte.)
Para la Ecuación 1:
Usando el método de mínimos cuadrados en dos etapas (MC2E), estimamos la
ecuación estructural.
Estimación de la Ecuación mediante Eviews
54
Tabla de Resultados
Dependent Variable: R
Method: Two-Stage Least Squares
Date: 10/02/08 Time: 17:40
Sample: 1970 1999
Included observations: 30
Instrument list: M I C
Variable
Coefficient
Std. Error
t-Statistic
Prob.
C
M
Y
10.10831
2.06E-05
-0.000578
7.210252
0.003122
0.002514
1.401935
0.006611
-0.229817
0.1723
0.9948
0.8200
R-squared
Adjusted R-squared
S.E. of regression
F-statistic
Prob(F-statistic)
0.129872
0.065418
2.390423
1.819236
0.181470
Mean dependent var
S.D. dependent var
Sum squared resid
Durbin-Watson stat
6.813800
2.472670
154.2813
0.453155
Estimación de la Ecuación:
R = 10.10830756 + 2.063889407e-005*M - 0.0005777285585*Y
Donde, a partir de esta estimación, obtenemos los valores de los parámetros B0, B1, B2:
B0= 10.10830756
B1= 2.063889407e-005
B2= - 0.0005777285585
Los resultados nos indican que los coeficientes no son estadísticamente significativos al 1%, 5%,
10%. Vemos que el R2 no es alto por lo que podríamos decir que el modelo no ajusta bien, y que
el Durbin Watson es cercano a cero, el cual nos indica que hay problemas de auto correlación
positiva. Es por eso que agregamos las variables AR(1) Y AR(2), y continuación veremos los
resultados:
55
CORRIGIENDO ECUACION 1
TABLA DE RESULTADOS
56
2
Observamos un cambio significativo en los valores de R y el estadístico Durbin Watson,
quedando mejor ajustado el modelo y probablemente sin problemas de autocorrelación.
Para la ecuación 2:
Usando el método de mínimos cuadrados en dos etapas (MC2E), estimamos la
ecuación estructural.
Estimación de la Ecuación 2 mediante Eviews
57
Tabla de Resultados
Dependent Variable: Y
Method: Two-Stage Least Squares
Date: 10/02/08 Time: 17:51
Sample: 1970 1999
Included observations: 30
Instrument list: M I C
Variable
Coefficient
Std. Error
t-Statistic
Prob.
C
R
I
18128.17
-1803.460
-0.061202
31234.86
3449.451
9.372850
0.580383
-0.522825
-0.006530
0.5665
0.6054
0.9948
R-squared
Adjusted R-squared
S.E. of regression
F-statistic
Prob(F-statistic)
-6.563759
-7.124038
4312.221
1.774839
0.188721
Mean dependent var
S.D. dependent var
Sum squared resid
Durbin-Watson stat
5787.850
1512.917
5.02E+08
0.452893
Estimacion de la ecuación:
Y = 18128.17094 - 1803.459552*R - 0.06120221399*I
Donde, a partir de esta estimación, obtenemos los valores de los parámetros α0, α
1, α 2:
α0= 18128.17094
α1= - 1803.459552
α2= - 0.06120221399
En esta ecuación también observamos que los coeficientes no son
estadísticamente significativos al 1%, 5%, 10%. Vemos que el R2 no es alto por
lo que podríamos decir que el modelo no ajusta bien, y que el Durbin Watson es
cercano a cero, el cual nos indica que hay problemas de auto correlación
positiva. Es por eso que agregamos las variables AR(1) Y AR(2), y continuación
veremos los resultados:
58
CORRIGIENDO ECUACION 2
TABLA DE RESULTADOS
Dependent Variable: Y1
Method: Two-Stage Least Squares
Date: 10/03/08 Time: 10:17
Sample (adjusted): 1972 1999
Included observations: 28 after adjustments
Convergence achieved after 89 iterations
Instrument list: M I C
Lagged dependent
variable & regressors
added to instrument list
Variable
Coefficient
Std. Error
t-Statistic
Prob.
C
R
I
AR(1)
AR(2)
29533.19
-18.09661
1.663127
0.989001
0.006395
114755.9
16.41810
0.264060
0.239064
0.246133
0.257356
-1.102235
6.298288
4.136978
0.025981
0.7992
0.2818
0.0000
0.0004
0.9795
R-squared
Adjusted R-squared
S.E. of regression
F-statistic
Prob(F-statistic)
0.997342
0.996880
80.77528
2157.844
0.000000
Mean dependent var
S.D. dependent var
Sum squared resid
Durbin-Watson stat
59
5941.421
1446.145
150066.9
1.778038
2
Observamos un cambio significativo en los valores de R , quedando bien ajustado el modelo,
y el estadístico Durbin Watson, el cual nos indica que probablemente no haya problemas de
autocorrelación.
60