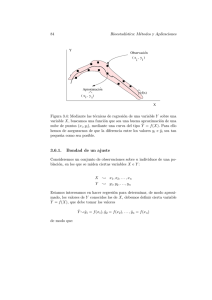
Tema 3
Anuncio

Estadı́stica para las Ciencias del Trabajo M. Vargas Jiménez 2012/02/11 Índice general 3. Regresión lineal múltiple y con variables cualitativas. Regresión logı́stica 3.1. Regresión y correlación lineal . . . . . . . . . . . . . . . . . . 3.1.1. Nociones teóricas . . . . . . . . . . . . . . . . . . . . . 3.1.2. Estimación del modelo . . . . . . . . . . . . . . . . . . 3.1.3. Descomposición de la variación... . . . . . . . . . . . . 3.1.4. Ajuste de la recta . . . . . . . . . . . . . . . . . . . . . 3.1.5. Inferencia . . . . . . . . . . . . . . . . . . . . . . . . . 3.1.6. Contrastes de hipótesis . . . . . . . . . . . . . . . . . . 3.1.7. Predicción . . . . . . . . . . . . . . . . . . . . . . . . . 3.2. Regresión múltiple . . . . . . . . . . . . . . . . . . . . . . . . 3.2.1. Estimación del modelo . . . . . . . . . . . . . . . . . . 3.2.2. Descomposición de la variación... . . . . . . . . . . . . 3.2.3. Inferencia . . . . . . . . . . . . . . . . . . . . . . . . . 3.2.4. Contraste de hipótesis . . . . . . . . . . . . . . . . . . 3.3. Regresión con variables cualitativas . . . . . . . . . . . . . . . 3.3.1. Interacción . . . . . . . . . . . . . . . . . . . . . . . . 3.4. Análisis de regresión lineal con ... . . . . . . . . . . . . . . . . 3.4.1. Representación gráfica de los... . . . . . . . . . . . . . 3.5. Análisis de regresión lineal ... . . . . . . . . . . . . . . . . . . 3.6. Análisis de regresión lineal... . . . . . . . . . . . . . . . . . . . 3.6.1. Representación gráfica de... . . . . . . . . . . . . . . . 3.7. Regresión logı́stica . . . . . . . . . . . . . . . . . . . . . . . . 3.7.1. Nociones teóricas . . . . . . . . . . . . . . . . . . . . . 3.7.2. Contrastes de hipótesis . . . . . . . . . . . . . . . . . . 3.7.3. Implementación con R de un análisis de regresión logı́stica . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.7.4. Ejemplo de regresión logı́stica con R . . . . . . . . . . 3.7.5. Ejemplo con varias formas de respuesta . . . . . . . . . 3 5 5 5 6 6 8 8 9 10 10 11 11 12 12 14 15 16 19 21 25 36 40 41 47 49 51 55 4 ÍNDICE GENERAL Capı́tulo 3 Regresión lineal múltiple y con variables cualitativas. Regresión logı́stica 3.1. Regresión y correlación lineal 3.1.1. Nociones teóricas Queremos explicar el comportamiento de una variable que juega el papel de dependiente a partir del conocimiento de una o más variables independientes. En regresión el objetivo es encontrar una función que exprese la forma en que una o más variables (denominadas independientes) afectan a otra variable (considerada dependiente o respuesta). La correlación tiene como objetivo medir la covariación entre dos variables, señalando el grado o la fuerza con que se relacionan. El modelo de regresión lineal simple presenta la forma: Y = β0 + β1 × X + donde a y b son constantes que se estiman a partir de los datos y definen la relación entre las variables X e Y. es el término de error o perturbación aleatoria. Se considera que representa un conjunto grande de efectos de factores, cada uno de los cuales tiene poca importancia por sı́ solo, ası́ como errores de medida y, en general, efectos no controlables. 5 6CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS. La relación entre X e Y es estocástica, o sea, para cada valor de X existe una distribución de probabilidad de Y. Asunciones del modelo Para cada observación i − esima, se verifica que la variable aleatoria i tiene media cero y varianza constante: E(i ) = 0 V (i ) = σ 2 Dadas i , j , con i 6= j, están incorreladas Cov(i , j ) = 0 j están normalmente distribuidas. 3.1.2. Estimación del modelo Los datos muestrales (xi , yi ) permitirán la obtención de las estimaciones b0 , b1 de los parámetros β0 , β1 desconocidos, haciendo mı́nima la suma de los residuos al cuadrado: S= X 2i = (yi − β0 − β1 × xi )2 X El resultado del análisis será la recta de regresión estimada, que notaremos: ybi = b0 + b1 × xi Los residuos observados vienen dados por las diferencias entre los valores observados y sus correspondientes estimaciones o valores ajustados ei = yi − ybi = yi − b0 − b1 × xi Representan las cantidades que la regresión no pudo explicar. Un análisis detallado de su comportamiento será de gran utilidad para juzgar el ajuste. 3.1.3. Descomposición de la variación de Y. El coeficiente de determinación. 3.1. REGRESIÓN Y CORRELACIÓN LINEAL 7 Se puede descomponer la variación que refleja Y en la muestra en dos componentes. Pero antes es preciso aclarar que, en este contexto, por variación total de Y se entiende el total de cambios registrados en sus valores, producidos tanto por los distintos cambios que sufre X en el rango muestral, como por los inherentes a la perturbación aleatoria. Es conceptualmente distinto de lo que se entiende por varianza de Y (σ 2 ), que refleja la dispersión de la distribución concreta de Y, para un valor especı́fico xi de X. Puede comprobarse que la variación total de Y se descompone en una componente denominada variación explicada por la regresión, que refleja las variaciones que sufre Y, debidas a los cambios registrados en X, y otra componente, denominada variación no explicada o residual, debida a la perturbación aleatoria. (yi − Y )2 = X X (yi − ybi )2 + X e2i = SCT = SCE + SCN E SCT = suma de cuadrados total SCE = suma de cuadrados explicada SCNE = suma de cuadrados no explicada Esta descomposición tiene interés, entre otras cosas, porque permite definir un estadı́stico descriptivo (relativo a la muestra) que mide la bondad del ajuste: el coeficiente de determinación R2 R2 = SCN E SCE =1− SCT SCT que representa la proporción de variación explicada por la regresión. 0 ≤ R2 ≤ 1 Un valor de R2 cercano a 0 indica la baja capacidad explicativa de la recta. La traducción gráfica mostrarı́a los puntos del diagrama de dispersión alejados de la recta. El coeficiente de correlación lineal de Pearson viene dado por la expresión rXY = Cov(X, Y ) σX × σY Mide el grado de asociación lineal entre las variables. 8CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS. 3.1.4. Ajuste de la recta El criterio de mı́nimos cuadrados permite plantear un sistema de ecuaciones lineales, sencillo, cuya solución viene dada por los coeficientes b0 y b1 . Los coeficientes b0 y b1 de la recta se obtienen mediante b1 = Cov(X, Y ) 2 σX b0 = Y − b1 × X donde la covarianza se obtiene mediante P Cov(X, Y ) = xi × y i −X ×Y N y la varianza de una variable X es 2 σX 3.1.5. = P 2 x i N −X 2 Inferencia Partiendo de unos supuestos dados, el método de mı́nimos cuadrados (MCO) permite estimar los parámetros, pero la siguiente cuestión que nos planteamos es la valoración de dichas estimaciones. El modelo estimado puede merecer un cierto nivel de confianza de ser el verdadero. Nos interesa conocer el nivel de confianza que tenemos en que el efecto de la variable independiente sea realmente verdadero o, por el contrario, se deba al azar. Planteamos el problema de si su valor es o no, significativamente distinto de cero, es decir, si la variabilidad de Y puede ser atribuida a X. Está claro que muestras distintas pueden producir estimaciones diferentes de b0 y b1 , pero nos planteamos la cuestión de si una estimación, b, estará o no cerca del verdadero parámetro, β. Con absoluta certeza no se puede responder a esta cuestión, ya que β es desconocido, pero sı́ podremos expresar la confianza que merece nuestra respuesta, expresándola en términos probabilı́sticos. Una estimación de σ 2 viene dada por s2 , definida como: 2 s = P 2 e i N −2 = SCN E N −2 3.1. REGRESIÓN Y CORRELACIÓN LINEAL 9 Donde N es el tamaño de la muestra. SCNE es la suma de cuadrados no explicada obtenida en la tabla de descomposición de la variación y MCNE se denomina media de cuadrados no explicada. Nos indica la magnitud de la variabilidad existente en los términos de error. A la raı́z cuadrada de su valor se denomina error tı́pico de la estimación. El error estándar, e.e.(b), es una medida de la cantidad de variabilidad que habrı́a en diferentes coeficientes, b´s, estimados de muestras extraı́das de la misma población. En esencia mide la capacidad de cambiar, ante cambios en las observaciones de la muestra. 3.1.6. Contrastes de hipótesis Un método para hacer conjeturas acerca de los valores que tendrán los verdaderos parámetros β, basándose en el conocimiento de la muestra, es el contraste de hipótesis. La hipótesis de mayor interés en la regresión, es la consideración de si el efecto de X es o no significativo. Es decir, si se puede o no, asumir que la pendiente de la recta es nula: β1 = 0 La hipótesis nula planteada se nota con H0 : β1 = 0 Equivale a admitir que no existe relación lineal entre X e Y. Los cambios en X no producen cambios en Y de forma lineal. Frente a la alternativa H1 : β1 = 0 (Se pueden considerar también alternativas como β1 > 0 , o β1 < 0) Si H0 es cierta, se comprueba que el estadı́stico t definido como t= b1 7−→ t de Student e.e.(b1 ) El cociente entre el parámetro estimado y su error estándar, sigue un modelo t de Student. Esta distribución depende de los grados de libertad g.l.= tamaño de la muestra − nº de coeficientes estimados. Basándose en el conocimiento del comportamiento probabilı́stico del estadı́stico t, se tomará la siguiente decisión: La mayorı́a de los paquetes estadı́sticos suelen calcular el valor concreto de t en la muestra (denominado t − value o t − valor) 10CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS t − valor = b e.e.(b) y su correspondiente p-valor, que representa el nivel más bajo al cual puede ser rechazada una hipótesis nula. p − valor = P (|t| > t − valor) DECISIÓN: si el p-valor es menor que el nivel α elegido, se rechaza la hipótesis nula. En caso contrario, no puede rechazarse. 3.1.7. Predicción El ajuste de un modelo puede no resultar útil para predecir, aún cuando los coeficientes de regresión sean significativos. Un valor de R bajo indica que sólo una parte pequeña de la variabilidad de Y puede ser explicada por la variable independiente. Esto sugiere que otras causas, aleatorias o no, influyen en Y. En este caso es arriesgado predecir valores para la variable dependiente. De igual modo, si los coeficientes estimados presentan una significatividad dudosa, las predicciones carecen de confianza. El valor medio predicho para un X = x0 es el valor ajustado en el modelo, y0 , obtenido al sustituir x0 en la ecuación: y0 = b0 + b1 × x0 3.2. Regresión múltiple En regresión múltiple se pretende explicar el comportamiento de una variable dependiente (Y) en función de dos o más variables independientes (X’s). El objetivo es descubrir qué variables independientes están relacionadas con la variable Y, y describir esta relación, midiendo los efectos que producen sobre la variable dependiente. El análisis de regresión múltiple permite calcular un modelo que relaciona la variable dependiente y las variables independientes en la forma: Y = β0 + β1 X1 + β2 X2 + ... + βk Xk + Los parámetros β0 , β1 , β2 , ..., βk se estiman por el procedimiento de mı́nimos cuadrados. Cada parámetro βi que acompaña a la variable independiente,Xi , expresa el incremento medio que se produce en la variable dependiente, Y, 3.2. REGRESIÓN MÚLTIPLE 11 por cada unidad en que se incrementa Xi , supuestas constantes las otras variables. 3.2.1. Estimación del modelo Haciendo mı́nima la suma de los residuos al cuadrado: S= X 2i = (yi − β0 − β1 xi1 − β2 xi2 − ... − βk xik )2 X Los valores ajustados para cada individuo i-ésimo se obtienen por la ecuación estimada, resultante de la solución de un sistema de k+1 ecuaciones lineales derivadas del criterio de ajuste mı́nimo cuadrático de la ecuación lineal de regresión: Yb = b0 + b1 X1 + b2 X2 + ... + bk Xk Los residuos observados vienen dados por las diferencias entre los valores observados y sus correspondientes estimaciones o valores ajustados: ei = yi − ybi Representan las cantidades que la regresión no pudo explicar. 3.2.2. Descomposición de la variación de Y. Tabla de Análisis de la varianza. Tal como vimos en regresión simple, se puede descomponer la variación que refleja Y en la muestra, en dos componentes: variación explicada por la regresión, que refleja las variaciones que sufre Y, debidas a los cambios registrados en X, y la variación no explicada o residual debida a la perturbación aleatoria. (yi − Y )2 = X X (yi − ybi )2 + X e2i = SCT = SCE + SCN E SCT = suma de cuadrados total SCE = suma de cuadrados explicada SCNE = suma de cuadrados no explicada La media de cuadrados no explicada viene dada por M CN E = SCN E n−k−1 12CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS La media de cuadrados explicada se obtiene por el cociente SCE k El coeficiente R2 , de correlación múltiple muestral al cuadrado, es un ı́ndice del ajuste total M CE = SCE SCN E =1− SCT SCT representa la proporción de variación de la variable dependiente que puede ser explicada por la combinación lineal de las variables independientes, o modelo de regresión propuesto. R2 = 0 ≤ R2 ≤ 1 En regresión múltiple tiene interés conocer un coeficiente derivado del R2 , denominado coeficiente de determinación ajustado. El R-cuadrado ajustado, corrige el R-cuadrado estándar basándose en el número de coeficientes del modelo. Este estadı́stico es útil para comparar modelos de regresión con diferentes números de variables independientes. Sabemos que, tanto si la variable tiene o no capacidad explicativa, el R-cuadrado estándar siempre se incrementará al incluir una nueva variable independiente en el modelo. El R-cuadrado ajustado penaliza la inclusión de nuevas variables, de tal modo, que si éstas no son suficientemente explicativas, el coeficiente puede incluso disminuir al añadirlas. R2 − ajustado = 1 − 3.2.3. M CN E SCN E n − 1 =1− SCT n − k − 1 M CT Inferencia El objetivo fundamental en regresión es el de conocer el nivel de confianza que tenemos en que el efecto de la variable independiente sea realmente verdadero o, por el contrario, se deba al azar. Se plantea el problema de si su valor es o no, significativamente distinto de cero. El error estándar de estimación es la raı́z cuadrada del error cuadrático medio, desviación estándar estimada de los residuos (mide la variabilidad no explicada en la variable respuesta). Su valor proporciona una interpretación de la magnitud de la dispersión de los términos de error. 3.2.4. Contraste de hipótesis 3.2. REGRESIÓN MÚLTIPLE 13 Un método para hacer conjeturas acerca de los valores que tendrán los verdaderos parámetros β, basándose en el conocimiento de la muestra, es el contraste de hipótesis. Destacamos los tests de hipótesis más usados en regresión: Test individual para conocer la significatividad de la variable Xj La hipótesis nula H0 : βj = 0 Equivale a admitir que, en principio 1 , no existe relación entre Xj e Y . Los cambios en Xj no producen cambios en Y. Frente a la alternativa H1 : βj 6= 0 Si H0 es cierta, se comprueba que el estadı́stico t definido como t= bj e.e.(bj ) el cociente entre el parámetro estimado y su error estándar, sigue un modelo t de Student. Esta distribución depende de los grados de libertad: g.l. = tamaño de la muestra - nº de coeficientes estimados. El conocimiento del modelo nos permite calcular p − valor = P (|t| > t − valor) DECISIÓN: si el p − valor es menor que el nivel α elegido, se rechaza la hipótesis. En caso contrario, no puede rechazarse. Incumplimiento de las asunciones del modelo En el modelo de regresión lineal se han hecho asunciones sobre los errores, tales como: los errores son independientes varianza constante siguen una normal 1 Debe tenerse en cuenta que la significatividad de una variable depende del contexto en que se efectúe el contraste. Por ejemplo, una variable puede ser significativa si aparece sola en el modelo y dejar de serlo cuando se incluye con otras. 14CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS La inspección de los gráficos de los residuos ayuda a valorar el resultado del ajuste. Para que las conclusiones derivadas del ajuste se tomen con cierta confianza debe comprobarse el cumplimiento de dichas asunciones. 3.3. Regresión con variables cualitativas Las variables cualitativas pueden también, al igual que las cuantitativas, explicar el comportamiento de una variable dependiente en el modelo de regresión. Pero antes es preciso cuantificarlas, definiendo nuevas variables ficticias capaces de reflejar en el modelo los efectos de sus distintas modalidades. Se llama variable ficticia a la creada para detectar la presencia/ausencia de un atributo o modalidad de la variable cualitativa. El método usual es asignar a las variables ficticias los valores 1 y 0 según presente o no el individuo una determinada modalidad. Dada una variable cualitativa con k modalidades, es suficiente tomar k-1 variables ficticias (de valores 1 y 0) para presentar todas las posibilidades de presencia ausencia de las distintas modalidades. Es decir, asignar una variable ficticia a cada modalidad de la variable cualitativa salvo a una, que se deja como referencia. Por ejemplo, para una variable cualitativa con 3 modalidades A, B, C, se toma una modalidad como referencia o base, por ejemplo, la primera categorı́a A. Se pueden definir dos variables ficticias (una para cada modalidad de la variable cualitativa B y C, dejando la modalidad A, sin ficticia), FB y FC, del siguiente modo: FB = 1 si el individuo presenta B; en otro caso valdrá 0. FC = 1 si el individuo presenta C; en otro caso valdrá 0. De este modo, cada elemento que presente la modalidad A tendrá en FB y FC los valores 0 y 0, respectivamente (FB=0 y FC=0). Un individuo que presenta la modalidad B, tendrá en las ficticias los valores: FB=1 y FC=0 y, por último, un individuo que presenta la modalidad C tendrá en las ficticias los valores: FB=0 y FC=1. Este tipo de codificación se denomina de referencia a primera categorı́a (A). Permite medir los efectos producidos en la variable dependiente cuando se pasa de la categorı́a referencia, A, a otra cualquiera (B o C) 3.3. REGRESIÓN CON VARIABLES CUALITATIVAS X A B C 15 FB FC 0 0 1 0 0 1 Para definir los efectos de la variable cualitativa X sobre Y, se define el modelo que presenta los siguientes términos: Y = β0 + β1 F B + β2 F C + Con las variables ficticias (FB y FC) definidas según la tabla anterior, la constante β0 representa el valor promedio o esperado en Y cuando FA = FB = 0 (equivalente a modalidad de X=A). β1 representa el cambio medio que se produce en Y cuando se pasa de A a B. β2 representa el cambio medio que se produce en Y cuando se pasa de A a C. La modalidad A es la referencia. 3.3.1. Interacción Un término que incluya el producto de dos o más variables independientes se denomina término de interacción. Por ejemplo, βX1 X2 indica que el efecto de una de las variables independientes depende del nivel de la otra. Pueden interaccionar dos o más variables, lo que da lugar a distintos órdenes de interacción. Puede deberse a una mezcla de variables continuas variables cualitativas variables continuas y cualitativas 16CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS 3.4. Análisis de regresión lineal con R: un ejemplo de regresión simple Las tasas de paro en 2005 y 2011 de 12 colectivos de personas del conjunto nacional, son las siguientes: X2005 X2011 12.73 35.30 18.08 32.12 5.15 15.93 10.55 18.50 4.68 13.19 8.25 15.23 12.98 37.96 18.75 36.98 8.26 30.36 12.51 28.04 8.36 35.35 11.28 24.45 Modelo teórico propuesto X2011 = β0 + β1 × X2005 + Función R que realiza el ajuste La función R que permite realizar un ajuste lineal es lm() Se determinará la recta de regresión simple que expresa la tasa de paro en 2011 respecto a la del 2005. Los argumentos de lm() son la fórmula que expresa la variable dependiente e independiente (obligatorio) y el data.frame que contiene los datos (optativo). lm(f ormula = X2011~X2005, data = Regs1) > Rs1=lm(X2011~X2005,data=Regs1) > summary(Rs1) 3.4. ANÁLISIS DE REGRESIÓN LINEAL CON ... 17 Call: lm(formula = X2011 ~ X2005, data = Regs1) Residuals: Min 1Q Median -7.860 -4.848 -1.925 3Q Max 6.192 12.110 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 11.3318 5.5984 2.024 0.0705 . X2005 1.4244 0.4762 2.991 0.0135 * --Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 6.996 on 10 degrees of freedom Multiple R-squared: 0.4722, Adjusted R-squared: 0.4195 F-statistic: 8.948 on 1 and 10 DF, p-value: 0.01354 El resultado se puede resumir mediante la función summary() Ecuación del modelo ajustada Es muy importante todo el contenido de este resultado. Por un lado aparece la tabla de coeficientes estimados, lo que va a permitir escribir la ecuación ajustada del modelo. La pendiente estimada es b1 = 1,424 La ordenada en el origen o intercept es b0 = 11,332 Y la ecuación ajustada: X2011 = 11,332 + 1,424 × X2005 Test de hipótesis de nulidad de la pendiente al nivel α = 0,01 Uno de los objetivos más importantes de un ajuste de regresión es comprobar si la variable (o variables independientes) sirven para explicar la variable dependiente. La respuesta cientı́fica a este interrogante se realiza mediante un contraste de hipótesis de nulidad del coeficiente que acompaña a la variable independiente en el modelo. La tabla de coeficientes es importante porque, además de permitir construir la ecuación ajustada, permite contrastar la hipótesis de nulidad de la pendiente: 18CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS H0 : β1 = 0 frente a la alternativa H1 : β1 6= 0 Observe que al nivel de significación α = 0,01 no puede rechazarse H0 , por lo que entendemos que, cambios en la variable X2005 no parece que provoquen cambios significativos en la variable X2011. Dirı́amos que (para este nivel de significación α elegido) la variable X2005 no explica la variable X2011. p − valor = 0,0135 > α = 0,01 DECISION: A este nivel de significación de 0.01, NO puede rechazarse que β1 = 0 Cuando las pendientes son significativamente distintas de cero, decimos que las variables sirven para explicar. Si la variable independiente es cuantitativa el coeficiente, β1 , se interpreta como el incremento esperado en la variable dependiente cuando se aumenta una unidad la variable independiente. Bondad de ajuste del modelo El coeficiente de correlación R2 permite valorar la bondad del modelo ajustado y, por tanto, su capacidad para hacer predicciones. Valores altos indican buen ajuste. Representa la proporción de variación de la variable dependiente que es explicada por el modelo. El valor R2 = 0,4722 no está cercano a 1. Por lo que se entiende que la recta no se ajusta bien a los datos. Error estándar de la estimación Y por último, el error estándar residual, presenta un valor igual a, 6.99, este valor en sı́ mismo no es muy explı́tico en lo que se refiere a interpretación. Sin embargo, es muy útil para comparar modelos propuestos para los mismos datos. (Lo veremos en el próximo ejemplo (pag. 24), cuando se proponga un modelo más completo). Este estadı́stico es un indicador de la variabilidad que deja sin explicar el modelo (error o dispersión aleatoria o no explicada). Un modelo que presente un valor bajo será preferible a otro con valor alto. 3.4. ANÁLISIS DE REGRESIÓN LINEAL CON ... 3.4.1. 19 Representación gráfica de los datos y la recta El gráfico muestra la nube de puntos, donde se ha incluido la recta de regresión: null device 1 40 Tasa de Paro en 2011 sobre 2005 ● ● ● ● ● 30 ● ● 20 Tasa Paro 2011 ● ● ● ● 10 ● 0 TP2011 = 11.33 + 1.42 TP2005 0 5 10 15 20 25 Tasa Paro 2005 Funciones R usadas en el gráfico > > > + + > > #Regs1 es el data.frame con los datos Rs=lm(X2011~X2005,data=Regs1) plot(Regs1$X2005,Regs1$X2011,col="red",ylab="Tasa Paro 2011", xlab="Tasa Paro 2005",main="Tasa de Paro en 2011 sobre 2005", col.main="red",xlim=c(0,25), ylim=c(0,40)) abline(coef = coef(Rs),col="blue",lty=2,lwd=3) text(10,5,"TP2011 = 11.33 + 1.42 TP2005",col="blue",cex=1) 20CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS Tabla de Variación Explicada (ANOVA) La función R anova() permite ver la variación total, la explicada y no explicada por el modelo. La tabla siguiente muestra los resultados anova(Rs) #Rs es el objeto que contiene los resultados del análisis Analysis of Variance Table Response: X2011 Df Sum Sq Mean Sq F value Pr(>F) X2005 1 437.98 437.98 8.9481 0.01354 * Residuals 10 489.46 48.95 --Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 La tabla presenta la variación explicada y no explicada o residual ası́ como las medias (obtenidas dividiendo por los g.l.) El test F permite constrastar la significatividad de los explicado por el modelo. Recta de regresión de X2005 sobre X2011 De modo similar puede obtenerse la recta de regresión de la tasa en 2005 sobre la de 2011. El gráfico siguiente muestra la representación simultánea de las dos rectas. Observe que se cortan en el punto medio de cada variable. windows 2 3.5. ANÁLISIS DE REGRESIÓN LINEAL ... 21 40 Rectas de Regresión ● ● ● ● ● 30 ● ● 20 Tasa Paro 2011 ● ● ● ● 10 ● TP2005 = 2.03 + 0.33 TP2011 0 TP2011 = 11.33 + 1.42 TP2005 0 5 10 15 20 25 30 Tasa Paro 2005 3.5. Análisis de regresión lineal con R: regresión simple con variable cualitativa Las tasas de paro en 2005 y 2011 de 12 colectivos de personas de España, clasificados por Nacionalidad, son las siguientes: 22CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS Nacionalidad X2005 X2011 Español 12.73 35.30 Español 18.08 32.12 Español 5.15 15.93 Español 10.55 18.50 Español 4.68 13.19 Español 8.25 15.23 Extranjero 12.98 37.96 Extranjero 18.75 36.98 Extranjero 8.26 30.36 Extranjero 12.51 28.04 Extranjero 8.36 35.35 Extranjero 11.28 24.45 Modelo teórico propuesto Variable dependiente = X2011 Variable independiente cualitativa = Nacionalidad (2 categorı́as) Variable ficticia asociada: FNaciExtranjero (segunda modalidad de variable Nacionalidad) Base=Español Modelo propuesto: X2011 = β0 + β1 × F N aciExtranj + Ajuste con R Se determinará la ecuación lineal de regresión que expresa la tasa de paro en 2011 respecto a la Nacionalidad del grupo. El paquete R detecta automáticamente una variable cualitativa declarada como factor y genera internamente la ficticia (o ficticias, si hay más de 2 modalidades) necesarias para el ajuste. Por defecto R toma como categorı́a base la primera modalidad. 3.5. ANÁLISIS DE REGRESIÓN LINEAL ... 23 Los argumentos de lm() son la fórmula que expresa la variable dependiente e independientes (obligatorio) y el data.frame que contiene los datos (optativo). No es necesario expresar explı́citamente que la variable es cualitativa. Basta tenerla declarada como factor. lm(f ormula = X2011~N acionalidad, data = Regs2) > Re2=lm(X2011~Nacionalidad,data=Regs2) > summary(Re2) Call: lm(formula = X2011 ~ Nacionalidad, data = Regs2) Residuals: Min 1Q Median -8.522 -5.957 -2.521 3Q Max 5.035 13.588 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 21.712 3.157 6.877 4.31e-05 *** NacionalidadExtranjero 10.478 4.465 2.347 0.0409 * --Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 7.733 on 10 degrees of freedom Multiple R-squared: 0.3552, Adjusted R-squared: 0.2907 F-statistic: 5.508 on 1 and 10 DF, p-value: 0.04086 Ecuación del modelo ajustado La tabla de coeficientes estimados muestra sus valores estimados con los que podemos escribir la ecuación del modelo ajustado. La ordenada en el origen o intercept es b0 = 21,712 La pendiente estimada de la variable ficticia F Extranjero = N acionalExtranj es b1 = 10,478 Y la ecuación ajustada es: X2011 = 21,712 + 10,478 N acionalExtranj Test de hipótesis de nulidad de la pendiente al nivel α = 0,05 24CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS Vemos si la variable propuesta sirve para explicar la variable dependiente. Para ello se realiza un contraste de hipótesis de nulidad del coeficiente que acompaña a la variable independiente ficticia (asociada a Nacionalidad). La tabla de coeficientes permitir construir la ecuación ajustada y contrastar la hipótesis de nulidad de las pendientes: H0 : β1 = 0 frente a la alternativa H1 : β1 6= 0 Observe que al nivel de significación α = 0,05 se rechaza H0 , por lo que entendemos que, cambios en la variable Nacionalidad provocan cambios significativos en la variable X2011. Dirı́amos que (para este nivel de significación elegido) la variable Nacionalidad explica la variable X2011. p − valor = 0,0409 < α = 0,05 DECISION: A este nivel de significación de 0.05, se rechaza que β1 = 0 Se concluye que la variable Nacionalidad sirve para explicar. En concreto, esperamos un incremento en la tasa de paro del 2011 de aproximadamente 10.5 unidades cuando pasamos del grupo de nacionalidad española al grupo de nacionalidad extranjera. Bondad de ajuste del modelo El coeficiente de correlación R2 representa la proporción de variación de la variable dependiente que es explicada por el modelo. El valor del R2 = 0,355 no está cercano a 1. Por lo que se entiende que el modelo no se ajusta bien a los datos. Error estándar de la estimación El error estándar residual, presenta un valor igual a 7.733 anterior tenı́a un valor igual a 6.99 y su coeficiente R-cuadrado Si tuviésemos que elegir entre el modelo simple anterior y éste, en estos criterios: error estandar y coeficente R2 , elegirı́amos el que presenta menor error estándar residual y mejor ajuste. (El modelo era mayor). basándonos primero, ya 3.6. ANÁLISIS DE REGRESIÓN LINEAL... 3.6. 25 Análisis de regresión lineal con R: un ejemplo de regresión múltiple Las tasas de paro en 2005 y 2011 de 32 colectivos de personas de España, clasificados por edad y sexo, son las siguientes: Sexo Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Edad TP2005 TP2011 <30 12.05 41.70 <30 19.48 45.75 >30 4.90 29.96 >30 8.44 33.06 <30 22.37 49.23 <30 27.32 43.19 >30 12.26 25.57 >30 18.72 30.62 <30 11.93 47.19 <30 29.02 43.23 >30 8.24 25.14 >30 20.30 31.57 <30 13.51 45.85 <30 27.13 44.17 >30 7.12 24.11 >30 15.66 26.45 <30 17.47 41.54 <30 27.77 41.72 >30 10.02 25.95 >30 17.18 27.31 <30 19.00 37.07 <30 30.41 43.46 >30 7.37 19.55 >30 22.26 30.80 <30 14.52 46.44 <30 21.37 43.22 >30 6.87 25.76 >30 12.80 28.21 <30 16.54 43.11 <30 25.20 38.98 >30 7.21 20.44 >30 18.16 25.93 Representación gráfica de los datos 26CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS El gráfico siguente puede orientar sobre la estructura que tienen los datos windows 2 50 Tasas de Paro hombre mujer ● ● ● ● 45 ● ● ● ● ● ● ● ● ● 40 ● ● 35 30 20 25 Tasa de Paro en 2011 ● 15 ● 5 10 15 20 25 30 <30 >30 35 Tasa Paro en 2005 Relación entre Tasa de paro en 2005 y Respuesta (Tasa de paro en 2011): Si no distinguimos por sexo ni edad, la relación entre Tasa de paro en 2011 y 2005 muestra una trayectoria, reflejada por la nube de puntos, aproximadamente de una recta con pendiente positiva. Relación entre Sexo y Respuesta (Tasa de paro en 2011): Los datos aparecen mezclados sin una trayectoria o agrupamiento claro en relación al eje Y del gráfico. Relación entre Edad y Respuesta (Tasa de paro en 2011): Si distinguimos entre los puntos correspondientes a edad <30 y >30, parece que existe relación. Aparecen 2 grupos distanciados verticalmente (eje de Tasas de Paro en 2011). Se aprecia visualmente un cambio importante en los valores de las tasas del 2011 al pasar del grupo joven al grupo mayor. 3.6. ANÁLISIS DE REGRESIÓN LINEAL... 27 Relación entre tasa de paro en 2005 y Respuesta (distinguiendo por edad) Si distinguimos entre los puntos correspondientes a edad <30 y >30, no parece que exista relación entre las Tasas de Paro en 2005 y 2011. Podemos dibujar dos rectas con pendientes próximas a cero. Relación entre tasa de paro en 2005 y Respuesta (distinguiendo por sexo) Dividiendo la nube de puntos por Sexo, parece que la relación entre las Tasas de Paro es similar a la global (independientemente del sexo la relación entre Tasas es similar). Si ajustamos por pasos modelos simples podemos confirmar lo comentado sobre el gráfico. Por ejemplo, el modelo que solo incluye a Tasa en 2005 como independiente presenta esta tabla de coeficientes: > summary(lm(TP2011~TP2005,data=Regm)) Call: lm(formula = TP2011 ~ TP2005, data = Regm) Residuals: Min 1Q -10.391 -6.171 Median -1.836 3Q 4.822 Max 15.489 Coefficients: Estimate Std. Error t value (Intercept) 22.8541 3.2923 6.942 TP2005 0.7415 0.1816 4.084 --Signif. codes: 0 '***' 0.001 '**' 0.01 Pr(>|t|) 1.04e-07 *** 0.000303 *** '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 7.393 on 30 degrees of freedom Multiple R-squared: 0.3574, Adjusted R-squared: 0.3359 F-statistic: 16.68 on 1 and 30 DF, p-value: 0.0003026 Donde se aprecia que la variable independiente TP2005 es signficativa, con pendiente 0,74. Si consideramos como independiente solo a la variable Sexo, obtenemos el resultado siguiente > summary(lm(TP2011~Sexo,data=Regm)) Call: lm(formula = TP2011 ~ Sexo, data = Regm) 28CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS Residuals: Min 1Q -14.7381 -8.5756 Median -0.1312 3Q 7.3697 Max 14.9419 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 34.288 2.294 14.95 1.92e-15 *** SexoMujer 1.816 3.244 0.56 0.58 --Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 9.175 on 30 degrees of freedom Multiple R-squared: 0.01034, Adjusted R-squared: -0.02265 F-statistic: 0.3135 on 1 and 30 DF, p-value: 0.5797 Donde se observa que la variable Sexo no es significativa. Con p − valor = 0,58. Por último, introducimos la variable Edad, que es la que muestra en el gráfico mayor relación con la variable tasa de paro en 2011. > summary(lm(TP2011~Edad,data=Regm)) Call: lm(formula = TP2011 ~ Edad, data = Regm) Residuals: Min 1Q Median -7.3519 -1.7641 -0.2856 3Q 2.5069 Max 6.1581 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 43.4906 0.8543 50.91 < 2e-16 *** Edad>30 -16.5887 1.2082 -13.73 1.8e-14 *** --Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.417 on 30 degrees of freedom Multiple R-squared: 0.8627, Adjusted R-squared: 0.8581 F-statistic: 188.5 on 1 and 30 DF, p-value: 1.797e-14 3.6. ANÁLISIS DE REGRESIÓN LINEAL... 29 Donde se aprecia que la variable independiente Edad es signficativa, con pendiente −16,6. Con p − valor = 0,000, altamente significativo. Con esta variable ha descendido claramente el error estándar y ha aumentado de forma importante el coeficiente de correlación R2 = 0,86 Propuestas de Modelos de regresión Múltiple Si añadimos la variable Sexo, al modelo que incluye la Tasa en 2005 obtenemos el modelo de regresión múltiple que presenta esta tabla de coeficientes: > summary(lm(TP2011~TP2005+Sexo,data=Regm)) Call: lm(formula = TP2011 ~ TP2005 + Sexo, data = Regm) Residuals: Min 1Q Median -9.490 -4.707 -1.710 3Q Max 3.627 12.938 Coefficients: Estimate Std. Error t value (Intercept) 20.6150 3.0535 6.751 TP2005 1.1431 0.2144 5.332 SexoMujer -8.8890 3.0866 -2.880 --Signif. codes: 0 '***' 0.001 '**' 0.01 Pr(>|t|) 2.08e-07 *** 1.01e-05 *** 0.0074 ** '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 6.631 on 29 degrees of freedom Multiple R-squared: 0.5003, Adjusted R-squared: 0.4658 F-statistic: 14.52 on 2 and 29 DF, p-value: 4.281e-05 Esto es coherente con el gráfico mostrado anteriormente y corrobora el hecho de que el contexto en que aparece las variables independientes afecta a los resultados. Una variable,que en principio no se muestra significativa, puede llegar a serlo cuando aparece junto a otra u otras (tal como ha ocurrido con la variable sexo). Del mismo modo, una variable que es significativa, podrı́a dejar de serlo al cambiar el conjunto de variables independientes en que se inserta. Este modelo mejora con respecto al modelo simple que incluye solo la variable TP2005. Y cláramente mejora al compararlo con el modelo que sólo incluye la variable sexo. Modelo teórico propuesto Variable dependiente = TP2011 (Tasa de paro en 2011) 30CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS Variables independientes Variable independiente continua = TP2005 (Tasa de paro en 2005) Variable independiente cualitativa = Edad (2 categorı́as o grupos de edad) Variable ficticia asociada: F>30 (segunda categorı́a de edad) Base (primera categorı́a de edad: menor de 30 años ) Variable independiente cualitativa = Sexo (2 categorı́as) Variable ficticia asociada: FMujer (segunda modalidad de variable Sexo) Base=”Hombre” Modelo propuesto: T P 2011 = β0 + β1 × T P 2005 + β2 × F M ujer + β3 × F > 30 + Ajuste con R La función R que permite realizar un ajuste lineal es lm() Se determinará la ecuación lineal de regresión múltiple que expresa la tasa de paro en 2011 respecto a la del 2005 y las variables Sexo y Edad del grupo. La fórmula para R es: lm(f ormula = T P 2011~T P 2005 + Sexo + Edad, data = Regm) > Rs2=lm(TP2011~TP2005+Sexo+Edad,data=Regm) > summary(Rs2) Call: lm(formula = TP2011 ~ TP2005 + Sexo + Edad, data = Regm) Residuals: Min 1Q Median 3Q Max 3.6. ANÁLISIS DE REGRESIÓN LINEAL... -6.482 -1.586 -0.327 2.940 31 7.441 Coefficients: Estimate Std. Error t value (Intercept) 44.6939 3.0463 14.671 TP2005 -0.1298 0.1763 -0.737 SexoMujer 3.0323 2.0357 1.490 Edad>30 -17.7053 1.9278 -9.184 --Signif. codes: 0 '***' 0.001 '**' 0.01 Pr(>|t|) 1.13e-14 *** 0.467 0.148 6.08e-10 *** '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.369 on 28 degrees of freedom Multiple R-squared: 0.8755, Adjusted R-squared: 0.8621 F-statistic: 65.61 on 3 and 28 DF, p-value: 8.796e-13 El resultado se puede resumir mediante la función summary() Ecuación del modelo ajustada La tabla de coeficientes estimados, lo que va a permitir escribir la ecuación ajustada del modelo. La ordenada en el origen o intercept es b0 = 44,694 La pendiente estimada de la tasa de paro X2005 es b1 = −0,13 La pendiente estimada de la ficticia FMujer= SexoMujer es b2 = 3,032 La pendiente estimada de la ficticia F>30=Edad>30 es b3 = −17,705 Y la ecuación ajustada es: X2011 = 44,694 + −0,13 × T P 2005 + 3.032 ×SexoM ujer + −17,705 × Edad > 30 Test de hipótesis de nulidad de las pendientes al nivel 0.05 Vemos si las variables propuestas sirven para explicar la variable dependiente. Para ello se realiza un contraste de hipótesis de nulidad del coeficiente que acompaña a cada una de las variables independientes en cuestión en el modelo. La tabla de coeficientes muestra los coeficientes estimados de la ecuación ajustada y los correspondientes estadı́sticos t con sus p-valores asociados para contrastar la hipótesis de nulidad de las pendientes: H0 : β1 = 0 32CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS frente a la alternativa H1 : β1 6= 0 Observe que al nivel de significación = 0,05 no se rechaza H0 , por lo que entendemos que, cambios en la variable TP2005 no provocan cambios significativos en la variable TP2011. Dirı́amos que (para este nivel de significación elegido) la variable TP2005 no explica la variable TP2011. p − valor = 0,467 >= 0,05 DECISION: A este nivel de significación de 0.05, no se rechaza que β1 = 0 Por tanto se tendrá que eliminar del modelo. Cuando las pendientes son significativamente distintas de cero, decimos que las variables sirven para explicar. Si la variable independiente es cuantitativa, el coeficiente se interpreta como el incremento esperado en la variable dependiente cuando se aumenta una unidad la variable independiente. En concreto, por cada unidad de incremento en la tasa de paro en 2005 (si la variable fuese significativa) esperamos encontrar un descenso de aproximadamente 0.12 unidades en la del año 2011. En este caso concreto no tiene sentido interpretarla puesto que no es significativa. La inclusióh de la variable altamente significativa Edad, es capaz de explicar parte de la variabilidad que en el modelo más simple (solo TP2005 y SexoMujer) era explicada por TP2005 y SexoMujer. Contraste para la variable Sexo H0 : β2 = 0 frente a la alternativa H1 : β2 6= 0 Observe que al nivel de significación = 0,05 no se rechaza H0 , por lo que entendemos que, cambios en la variable SexoMujer (y por tanto en la variable Sexo) no provoca cambios significativos en la variable TP2011. Dirı́amos que (para este nivel de significación elegido) la variable Sexo no explica la variable TP2011. p − valor = 0,148 >= 0,05 3.6. ANÁLISIS DE REGRESIÓN LINEAL... 33 DECISION: A este nivel de significación de 0.05, no se rechaza que β2 = 0 Se concluye que la variable Sexo no sirve para explicar. Contraste para la variable Edad H0 : β3 = 0 frente a la alternativa H1 : β3 6= 0 Observe que al nivel de significación = 0,05 se rechaza H0 , por lo que entendemos que, cambios en la variable ficticia de Grupo de Edad>30 (y por tanto en la variable Edad) provocan cambios significativos en la variable TP2011. El coeficiente es aproxiamadamente igual a -17.7, por lo que se espera un descenso de 17.7 unidades en la respuesta (Tasa de Paro en 2011) al pasar de un joven (con menos de 30 años) a uno mayor (con 30 ó más años). p − valor = 0,000 <= 0,05 DECISION: A este nivel de significación de 0.05, se rechaza que β3 = 0 Se concluye que la variable Edad sirve para explicar y es además altamente significativa. Debemos eliminar del modelo aquellas variables que no explican, paso a paso, de una en una, comenzando por la que tenga el mayor p-valor (es decir, la menos significativa). Hay que tener en cuenta que el contexto en que aparece la variable independiente modifica o puede modificar su importancia en el conjunto. El modelo anterior, con 3 varibles explicativas, presenta en principio, 2 variables no significativas. Si se elimina del modelo la variable independiente TP2005, el modelo ajustado es Call: lm(formula = TP2011 ~ Sexo + Edad, data = Regm) Residuals: Min 1Q Median 3Q Max 34CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS -6.4437 -1.2466 -0.4619 2.8550 6.6475 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 42.582 1.023 41.610 < 2e-16 *** SexoMujer 1.816 1.182 1.537 0.135 Edad>30 -16.589 1.182 -14.038 1.83e-14 *** --Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.342 on 29 degrees of freedom Multiple R-squared: 0.873, Adjusted R-squared: 0.8643 F-statistic: 99.72 on 2 and 29 DF, p-value: 1.006e-13 Lo que nos llevarı́a a elegir el modelo más simple, con sólo la variable Edad. Call: lm(formula = TP2011 ~ Edad, data = Regm) Residuals: Min 1Q Median -7.3519 -1.7641 -0.2856 3Q 2.5069 Max 6.1581 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 43.4906 0.8543 50.91 < 2e-16 *** Edad>30 -16.5887 1.2082 -13.73 1.8e-14 *** --Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.417 on 30 degrees of freedom Multiple R-squared: 0.8627, Adjusted R-squared: 0.8581 F-statistic: 188.5 on 1 and 30 DF, p-value: 1.797e-14 El coeficiente que acompaña a la ficticia Edad>30 vale aprosimadamente -16.6, es significativo al nivel 0.05 (de hecho su p-valor está próximo a 0) Se concluye que la variable Edad sirve para explicar. Se espera un descenso de 16.6 unidades en la tasa de Paro en cuando se pasa del grupo joven al grupo mayor. Otra Representación gráfica de los datos: windows 2 3.6. ANÁLISIS DE REGRESIÓN LINEAL... 35 45 40 35 30 25 20 20 25 30 35 40 45 50 Año 2011 50 Año 2011 <30 >30 Hombre Mujer Año 2005 Año 2005 25 20 15 10 5 5 10 15 20 25 30 Sexo 30 Edad Hombre Mujer <30 Sexo >30 Edad Modelo con interacción Podemos ver si el efecto de la variable TP2005 parece que difiere según sea el grupo de hombres o de mujeres, añadiendo términos de interacción al modelo. > Rs3=lm(TP2011~TP2005+Sexo+Edad+Sexo*TP2005,data=Regm) > summary(Rs3) Call: lm(formula = TP2011 ~ TP2005 + Sexo + Edad + Sexo * TP2005, data = Regm) Residuals: Min 1Q Median -7.016 -1.442 0.072 3Q 2.232 Max 5.474 Coefficients: (Intercept) TP2005 Estimate Std. Error t value Pr(>|t|) 40.6730 3.4990 11.624 5.12e-12 *** 0.1796 0.2259 0.795 0.4335 36CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS SexoMujer 9.4376 Edad>30 -17.0668 TP2005:SexoMujer -0.4363 --Signif. codes: 0 '***' 0.001 3.6908 1.8545 0.2143 2.557 0.0165 * -9.203 8.18e-10 *** -2.036 0.0517 . '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.194 on 27 degrees of freedom Multiple R-squared: 0.892, Adjusted R-squared: 0.876 F-statistic: 55.77 on 4 and 27 DF, p-value: 1.16e-12 Este modelo está más próximo a la estructura que muestran los datos, inspeccionada gráficamente. Mejora la bondad de ajuste (R2 ajustado = 0,876) y el error estándar residual disminuye ligeramente (3.2). Los p-valores asociados a los coeficientes estimados, que no son significativos, están, no obstante, cercanos al lı́mite del nivel de significación (0.0517). Nota: El principio jerárquico establece que si se admite en el modelo un término de interacción, automáticamente quedan incluidos los efectos principales (al margen de los valores p-valores asociados a ellos). Bondad de ajuste del modelo Representa la proporción de variación de la variable dependiente que es explicada por el modelo. El valor del R2 = 0,892 está cercano a 1. Por lo que se entiende que la ecuación estimada del modelo se ajusta bien a los datos. 3.6.1. Representación gráfica de los datos y la ecuación ajustada El gráfico muestra la nube de puntos, donde se ha incluido la recta de regresión ajustada para cada grupo de Edad y Sexo: windows 2 3.6. ANÁLISIS DE REGRESIÓN LINEAL... 37 ● Valores observados y ajustados ● ● ● 45 hombre mujer ● ● ● ● ●● ● ● ● ● ●● ● ● ● ● ● ● ● ● ● ● ● ● 40 ● ● 35 TP2011 ● ● ● ● 30 ● ● ● ● ● ● ● ● ● ● 25 ● 5 ● 10 15 20 25 <30 >30 30 TP2005 Con los datos de la tabla 3.1 ajuste el modelo que mejor se adapte a los datos, para explicar la Tasa de paro en 2011. Se han ajustado los modelos siguientes: lm1=lm(X2011~., data=Regm) lm2=lm(X2011~.+nacional*X2005, data=Regm) lm3=lm(X2011~.+nacional*X2005+Edad*X2005, data=Regm) lm4=lm(X2011~.+nacional*X2005+Edad*X2005+nacional*Edad, data=Regm) Edad <30 >30 <30 >30 nacional X2005 X2011 Edad.1 Español 20.41 43.78 <30 Español 11.23 24.67 >30 Extranjero 16.07 42.44 <30 Extranjero 9.98 37.40 >30 nacional.1 X2005.1 X2011.1 Español 20.41 43.78 Español 11.23 24.67 Extranjero 16.07 42.44 Extranjero 9.98 37.40 38CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español 9.49 3.93 14.36 8.95 18.91 7.65 10.22 14.86 11.77 4.51 14.30 7.77 19.67 8.90 24.26 9.79 14.90 6.28 8.58 14.40 16.01 6.26 18.65 8.73 13.94 6.73 11.23 13.42 10.28 4.62 19.39 9.92 14.33 6.64 12.97 9.86 21.96 13.46 27.41 15.75 17.29 25.75 10.55 49.12 31.54 32.88 12.96 30.69 33.67 30.11 14.52 40.40 25.62 45.28 24.05 35.96 31.78 29.40 10.30 35.00 29.91 29.71 12.14 36.19 28.53 34.16 16.91 40.69 29.70 27.71 12.56 36.86 31.05 36.39 17.08 43.80 33.71 38.32 19.18 36.01 35.59 28.49 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español 9.49 3.93 14.36 8.95 18.91 7.65 10.22 14.86 11.77 4.51 14.30 7.77 19.67 8.90 24.26 9.79 14.90 6.28 8.58 14.40 16.01 6.26 18.65 8.73 13.94 6.73 11.23 13.42 10.28 4.62 19.39 9.92 14.33 6.64 12.97 9.86 21.96 13.46 27.41 15.75 17.29 25.75 10.55 49.12 31.54 32.88 12.96 30.69 33.67 30.11 14.52 40.40 25.62 45.28 24.05 35.96 31.78 29.40 10.30 35.00 29.91 29.71 12.14 36.19 28.53 34.16 16.91 40.69 29.70 27.71 12.56 36.86 31.05 36.39 17.08 43.80 33.71 38.32 19.18 36.01 35.59 28.49 3.6. ANÁLISIS DE REGRESIÓN LINEAL... >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 <30 >30 Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Español Español Extranjero Extranjero Cuadro 7.34 13.09 >30 19.79 38.86 <30 16.33 31.63 >30 11.71 27.33 <30 4.74 11.17 >30 12.81 28.01 <30 8.67 20.92 >30 13.20 35.30 <30 5.11 17.96 >30 12.76 42.41 <30 11.50 33.45 >30 10.86 20.01 <30 3.35 7.74 >30 11.24 35.81 <30 8.30 21.87 >30 14.10 23.62 <30 5.35 8.59 >30 12.47 30.29 <30 14.23 19.94 >30 10.40 27.49 <30 3.32 9.08 >30 18.22 44.95 <30 9.60 31.92 >30 35.88 48.14 <30 12.75 18.53 >30 25.32 32.96 <30 38.49 47.85 >30 28.77 40.49 <30 8.83 16.04 >30 53.22 12.01 <30 5.59 41.77 >30 3.1: Tasas de paro según 39 Español 7.34 Extranjero 19.79 Extranjero 16.33 Español 11.71 Español 4.74 Extranjero 12.81 Extranjero 8.67 Español 13.20 Español 5.11 Extranjero 12.76 Extranjero 11.50 Español 10.86 Español 3.35 Extranjero 11.24 Extranjero 8.30 Español 14.10 Español 5.35 Extranjero 12.47 Extranjero 14.23 Español 10.40 Español 3.32 Extranjero 18.22 Extranjero 9.60 Español 35.88 Español 12.75 Extranjero 25.32 Extranjero 38.49 Español 28.77 Español 8.83 Extranjero 53.22 Extranjero 5.59 nacionalidad y sexo [1] .EdadnacionalX2005X2011” La tabla anora de de los 4 ajustes propuestos es la siguiente: 13.09 38.86 31.63 27.33 11.17 28.01 20.92 35.30 17.96 42.41 33.45 20.01 7.74 35.81 21.87 23.62 8.59 30.29 19.94 27.49 9.08 44.95 31.92 48.14 18.53 32.96 47.85 40.49 16.04 12.01 41.77 40CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS 1 2 3 4 Res.Df 72 71 70 69 RSS Df Sum of Sq F Pr(>F) 4162.64 2532.30 1 1630.34 58.02 0.0000 1948.48 1 583.81 20.78 0.0000 1938.81 1 9.67 0.34 0.5593 > anova(lm1,lm2,lm3,lm4) Analysis of Variance Table Model 1: X2011 ~ Edad + nacional + X2005 Model 2: X2011 ~ Edad + nacional + X2005 + nacional * X2005 Model 3: X2011 ~ Edad + nacional + X2005 + nacional * X2005 + Edad * X2005 Model 4: X2011 ~ Edad + nacional + X2005 + nacional * X2005 + Edad * X2005 + nacional * Edad Res.Df RSS Df Sum of Sq F Pr(>F) 1 72 4162.6 2 71 2532.3 1 1630.34 58.0220 1.001e-10 *** 3 70 1948.5 1 583.81 20.7772 2.170e-05 *** 4 69 1938.8 1 9.67 0.3442 0.5593 --NA El resultado del ajuste del modelo lm3 es el siguiente: (Intercept) Edad>30 nacionalExtranjero X2005 nacionalExtranjero:X2005 Edad>30:X2005 3.7. Estimate Std. Error t value Pr(>|t|) 20.6419 2.5748 8.02 0.0000 -17.3151 2.6406 -6.56 0.0000 23.4504 2.4609 9.53 0.0000 0.7561 0.1544 4.90 0.0000 -1.1944 0.1624 -7.36 0.0000 0.8374 0.1829 4.58 0.0000 Regresión logı́stica 3.7. REGRESIÓN LOGÍSTICA 3.7.1. 41 Nociones teóricas S Extendemos el análisis de regresión lineal para tener en cuenta nuevos modelos, denominados modelos lineales generalizados 2 (GLM), que permiten relajar las exigencias de normalidad de la respuesta y de la relación lineal. El modelo de regresión, ya estudiado, presenta ciertas caracterı́sticas y exigencias teóricas referentes tanto a la naturaleza de la información que trata (variables), como a las asunciones teóricas necesarias para validar conclusiones. Nos encontramos con situaciones en que los objetivos del análisis son similares, pero el incumplimiento de los requisitos necesarios para su aplicación no nos permite usarlo. La regresión logı́stica nos permite analizar modelos con variable dependiente dicotómica. Se propuso como una técnica alternativa para salvar los inconvenientes que presenta el modelo de regresión lineal para tratar datos dicotómicos. Empezó a usarse en el campo epidemiológico (probabilidad de presencia ausencia de una determinada enfermedad) y hoy se usa en todos los campos especialmente en el relativo a las ciencias sociales. Tal es el caso que nos ocupa ahora: explicar el comportamiento de una variable dependiente (Y) en función de otras variables explicativas (X´s), pero considerando que la variable dependiente es discreta con sólo dos valores posibles que notaremos 0 y 1. Las variables independientes pueden ser cualitativas o cuantitativas, discretas o continuas. Como en regresión lineal, distinguimos entre una variable respuesta o dependiente y una o más variables explicativas (cualitativas o cuantitativas). La influencia de las variables explicativas sobre la dependiente o respuesta viene reflejada por medio de una función lineal que relaciona el denominado predictor lineal con las variables independientes. La media de la variable dependiente (probabilidad de éxito) es una función del predictor lineal (combinación lineal de las variables independientes). El modelo viene caracterizado por la denominada función link y por el modelo de distribución de la respuesta. Dos casos particulares importantes de la clase de modelos GLM, además del modelo de regresión lineal con respuesta normal, son el modelo de regresión logı́stica, con respuesta binaria y el modelo log-lineal con respuesta Poisson. 2 La clase de modelos lineales generalizados, GLM, tiene al modelo de regresión lineal con variable dependiente normal como un caso particular 42CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS En el modelo que nos ocupa aquı́, de regresión logı́stica, tomaremos la función logit y el modelo de distribución de probabilidad binomial. Supongamos, por ejemplo, que se ha clasificado a un grupo de individuos atendiendo a un conjunto de variables explicativas como X1=Edad, X2=nivel estudios, etc., y una variable, Y, considerada dependiente que representa la asistencia a una manifestación (con categorı́as 1=Si y 0=No). Se desea estudiar la probabilidad de que un individuo asista a la manifestación en función de las variables X1, X2, etc. El objetivo es construir un modelo capaz de describir el efecto de los cambios de las variables explicativas sobre la probabilidad de que Y valga 1 (probabilidad de asistir a la manifestación). Sea p=P(Y=1) Modelo de regresión logı́stica simple Expresado en términos de los logits, el modelo presenta la forma: logit = ln p = β0 + β1 X 1−p donde los logits son funciones lineales de las variables explicativas, pero no las probabilidades. Despejando la probabilidad de la ecuación anterior, lo podemos presentar en términos de probabilidad: eβ0 +β1 X p = eβ0 +β1 X ⇒ p = 1−p 1 + eβ0 +β1 X Es frecuente expresar el modelo en términos de Odds (razón de una probabilidad a su valor complementario) Expresado en términos de Odds o Ventajas: Odd(x) = p(x) = eβ0 (eβ1 )x 1 − p(x) Conocidos los coeficientes del modelo de regresión logı́stica se puede determinar el incremento multiplicativo que se produce en la razón de odds 3 para cada incremento de una unidad de x: Odd(x + 1) = p(x + 1) = eβ0 (eβ1 )(x+1) 1 − p(x + 1) De donde la razón de odds, RO, vale: 3 Un estadı́stico muy utilizado y estrechamente ligado a la interpretación de los parámetros de un modelo de regresión logı́stica, es este cociente o razón, denominado razón de odds. 3.7. REGRESIÓN LOGÍSTICA RO(x+1/x) = 43 Odd(x + 1) = eβ1 Odd(x) La razón de Odds permite comparar por cociente las odds de la variable respuesta en dos situaciones caracterizadas por los valores adoptados por las variables independientes. Modelo de regresión logı́stica múltiple Para el caso más general de k variables explicativas, X = (x1 , x2 , ..., xk ), el modelo de regresión logı́stica relaciona la variable dicotómica de valores Y = 1 e Y = 0 con el vector X, mediante: Modelo expresado en probabilidades P eβ0 + βk xk P p= 1 + eβ0 + βk xk también podemos expresar en términos de logit: logit = β0 + X βj xj = β 0 X Proporciona una descripción de la influencia de las variables explicativas asociadas a la variable respuesta, relacionando varios factores o variables explicativas y la probabilidad de la variable dependiente, mediante la función descrita. Estimación A diferencia del modelo de regresión lineal, cuyos coeficientes pueden estimarse resolviendo un sistema de ecuaciones lineales, el procedimiento de estimación de máxima verosimilitud usado, no permite, en general, soluciones dadas mediante expresiones explı́citas, el sistema de ecuaciones no lineales generado en el proceso de estimación de los parámetros, obliga a aplicar procedimientos iterativos de cálculo, como por ejemplo, el algoritmo de Newton-Raphson o el método iterativo de mı́nimos cuadrados ponderados. Modelo con variables cualitativas: variables ficticias para modelos logit De modo similar al uso de variables ficticias en el modelo de regresión lineal, en el modelo de regresión logı́stica, se estimarán los efectos de las 44CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS distintas modalidades de una variable explicativa cualitativa sobre la variable respuesta, a través del diseño de distintas variables, denominadas ficticias (dummy en terminologı́a inglesa). Referencia a celda: La codificación que toma como referencia una modalidad de la variable cualitativa (generalmente la primera o última), permite comparar el comportamiento en la respuesta de los individuos que presentan una modalidad i-ésima, con los de la modalidad referencia o base. Interpretación de los parámetros de un modelo de regresión logı́stica Distinguiremos distintos casos: Una variable explicativa categórica: Dada la variable A de modalidades A1 y A2 , se define el modelo logit = β0 + β1 F A2 Usando la codificación de referencia a celda, F A2 = 1 si A = A2 y F A2 = 0 si A = A1 , la Odd de la variable respuesta entre los elementos de la celda o categorı́a A2 es Odd(A2 ) = P (A2 ) 1 − P (A2 ) Y entre los elementos de la celda o modalidad A1 es Odd(A1 ) = P (A1 ) 1 − P (A1 ) P (A1 ) y P (A2 ) representan las probabilidades de que la variable respuesta, Y, tome el valor 1 (ocurrencia del suceso en estudio) para los individuos de la celda A1 y A2 , respectivamente. El logaritmo neperiano de la razón de odds, RO, que compara la categorı́a A2 frente a la A1 vale: ln(RO) = logit(A = A2 ) − logit(A = A1 ) ln(RO) = logit(F A2 = 1) − logit(F A2 = 0) = β0 + β1 1 − (β0 + β1 0) = β1 3.7. REGRESIÓN LOGÍSTICA 45 Tomando exponenciales se obtiene la razón de odds, RO: ROA2 /A1 = P (A2 ) 1−P (A2 ) P (A1 1−P (A1 ) = P (A2 ) 1 − P (A1 ) = eβ1 P (A1 ) 1 − P (A2 ) Ejemplo: Variable dependiente Y (Acudir a la huelga, dicotómica, de valores SI y NO) Variable independiente X (cualitativa, afilicación a un sindicato, de valores SI y NO) La probabilidad, p, de que se ponga en huelga un trabajador, viene explicada según el modelo: e−1,39+1,1F S 1 + e−1,39+1,1F S Siendo FS la variable ficticia asociada a la cualitativa X pertenencia al sindicato con valores FS=1 si el trabajador pertenece a un sindicato y FS=0, en caso contrario. (Es decir,FS es la ficticia asociada a la modalidad SI pertenece al sindicato y la modalidad base o referencia es: NO pertenece al sindicato) a) Obtenga la Razón de odds que compara a los trabajadores pertenecientes al sindicato con los no afiliados. p= b) Determine la probabilidad de que un trabajador, que no pertenece al sindicato, secunde la huelga. Solución: a) ROSI/N O = eβ1 = e1,1 = 3,004 b) Sustituyendo FS=0 en la ecuación del modelo: p= e−1,39 = 0,199 1 + e−1,39 Una variable explicativa cualitativa con más de dos categorı́as: Sea la variable cualitativa, A, de I modalidades: A1 , A2 , ..., AI . 46CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS Supongamos que usamos la codificación de referencia a celda primera. El modelo constará de I-1 térmninos para expresar los efectos de las I modalidades de la variable cualitativa A. Consideremos las I-1 variables ficticias: F A2 , F A3 , ..., F AI , correspondientes a las modalidades A2 , ..., AI . de A. La modalidad A1 es la base o referencia. logit = β0 + β1 F A2 + ... + βk−1 F Ak + ... + βI−1 F AI Observe que si A = Ak , la ficticia definida para esa modalidad es F Ak , cuyos valores son 1’s y 0’s. Tales que: F Ak = 1 si A = Ak y F Ak = 0, en otro caso. El logaritmo neperiano de la RO que compara Ak con A1 viene dado por: logit(Ak ) − logit(A1 ) = (β0 + β1 0 + ... + βk−1 1 + ... + βI−1 0) − (β0 + β1 0 + ... + βk−1 0 + ... + βI−1 0) = βk−1 βk−1 es el cambio producido en el logit al incrementar una unidad (pasar de 0 a 1) la correspondiente variable ficticia, F Ak . Lo que interpretaremos, de modo equievalente, como el cambio esperado en el logit al pasar de la modalidad A1 a la categorı́a Ak La razón de odds de Ak frente a A1 viene dada por: RO(Ak /A1 ) = exp(βk−1 ) Una variable explicativa medida a escala ordinal o superior Sea X una variable explicativa cuantitativa (discreta o continua) Sea el modelo logit = β0 + β1 X logit(x + 1) − logit(x) = (β0 + β1 (x + 1)) − (β0 + β1 (x)) = β1 β1 es el cambio producido en el logit al incrementar X en una unidad. La Odd de la variable respuesta entre los individuos con valor x es Odd(x) = p(x) 1 − p(x) Y entre los individuos que presentan x+1 es 3.7. REGRESIÓN LOGÍSTICA 47 Odd(x + 1) = p(x + 1) 1 − p(x + 1) El logaritmo de la razón de odds vale ln(RO) = logit(x + 1) − logit(x) = β1 Y la razón de Odds que resulta tras exponenciar es exp(β1 ) 3.7.2. Contrastes de hipótesis Los contrastes de hipótesis más frecuentes en regresión logı́stica son los siguientes: Contrastes univariantes Uno de los más usados es el test de Wald que se efectúa para cada una de las variables que intervienen en el modelo. Para un coeficiente cualquiera, βj , se verifica (para muestras suficientemente grandes) que bajo la hipótesis nula H0 : βj = β0 , el estadı́stico w definido por: w= (bj − βj )2 → χ21 V ar(bj ) sigue un modelo Chi-cuadrado con 1 g.l. En R, con la función summary() se puede visualizar los contrastes z (normal estandarizada) individuales para cada una de los términos incluidos en el modelo. Se presentan los valores estimados de los coeficientes su error estándar y los cocientes z z= bj →Z e.e(bj ) Ası́ como los p-valores asociados. En particular, el cociente entre el valor estimado y su error estándar puede aproximarse de forma aceptable a la distribución normal estándar en aquellos casos en que el tamaño muestral sea suficientemente grande, pudiendo contrastar la hipótesis nula: 48CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS H0 : βj = 0 Frente a la alternativa: H1 : βj 6= 0 Si notamos: √ w= b j e.e(bj ) bajo la hipótesis nula, admitiendo las condiciones necesarias para que siga una normal, z= √ √ w w → N (0, 1) (cuando n tiende a infinito) se decide según las desigualdades siguientes: √ Si P (|z| > w) < α, se rechaza H0 al nivel α, por tanto, la variable independiente, Xj , sirve para predecir la variable respuesta. √ Si P (|z| > w) > α, se acepta H0 al nivel α, por tanto, la variable independiente, Xj , NO ayuda a mejorar el ajuste. Test de razón de verosimilitud para comparar el modelo con k variables independientes, con el modelo más completo, de k+h variables En este caso se dice que los modelos están anidados, todas las variables de uno de ellos están incluidas en el otro. Este contraste permite establecer la significación conjunta de las h variables explicativas excluidas del modelo. A diferencia del contraste de Wald, que sólo necesita estimar el modelo general (no restringido), éste se basa en la estimación de ambos: el restringido (h coeficientes nulos), de k+1 coeficientes, y el no restringido, de k+h+1. Las hipótesis son: H0 : Los coeficientes de las h variables excluidas del modelo son nulos. H1 : Al menos uno de los h coeficientes es distinto de cero. Se define el estadı́stico G como: G=-2[ln(f.verosimil.mod. de sólo k v.exp.)ln(f.versimil.mod. con k+h v.exp.)] Bajo H0 , G sigue un modelo Chi-cuadrado con h=(k+h)-k g.l. 3.7. REGRESIÓN LOGÍSTICA 49 Si P (χ2 > G) < α, se rechaza H0 al nivel α, por tanto, al menos una de las h variables independientes es importante para explicar la variable respuesta. Si P (χ2 > G) ≥ α, se acepta H0 al nivel α, por tanto, ninguna de las h variables independientes añadidas ayuda a mejorar el ajuste y, siguiendo el principio de parsimonia, concluiremos que el mejor modelo contendrá sólo las k variables independientes del modelo más simple. En R, se puede realizar un contraste para decidir la significatividad entre los términos adicionales en modelos anidados. La función que permite realizar el contraste es anova(). Uno de los test usuales para contrastar los términos de uno o varios modelos es el test chi-cuadrado. Por último señalemos que un resumen global de la bondad del ajuste permite contrastes mediante estadı́sticos como Chi-cuadrado de Pearson, la Deviance . Este contraste sólo es aconsejable si los datos se presentan agrupados. Vea los ejemplos realizados (págs. 51, 55). 3.7.3. Implementación con R de un análisis de regresión logı́stica La función de ajuste es glm() glm(formula, family 4 = gaussian, data, weights, subset, offset) Descripción de los argumentos usados: formula: Describe la ecuación del modelo; es decir, la variable dependiente o respuesta seguida del sı́mbolo ~y las variables independientes. La respuesta representa proporciones de éxitos observados pero pueden introducirse de varios modos. Vea la práctica resuelta: Ejemplo simple de regresión logı́stica, para más información. family: Usaremos el modelo binomial con la función link = ”logit” data: Es optativo. Es el data.frame que contiene las variables a usar. subset: Es optativo. Permite realizar el análisis sólo en parte de los datos. Offset. Optativo. Representa un término que se incluye en el predictor lineal y se asume que afecta a la respuesta con valores previamente conocidos que se añaden al predictor lineal con coeficiente igual a 1. Tal como se ha comentado en párrafo anterior, los datos se pueden introducir de varios modos: 4 Se puede usar glm para ajustar un modelo de regresión lineal con la opción de family por defecto (gaussiana), pero es menos eficiente que lm 50CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS Formas en que se pueden introducir los datos Los datos pueden darse de varios modos, según se presente la información relativa a los exitos y fracasos de la variable dependiente. 1. Un vector de valores que representan proporciones de éxitos. Nº de éxitos yi entre el total (ni = exitos+f racasos). En este caso los totales ni deben introducirse como el argumento weights. 2. Un vector de 0’s y 1’s (fracasos y éxitos, respectivamente). En este caso no hay que especificar el argumento weights. 3. Un vector con valores que representan a más de dos niveles o categorı́as. En este caso se trata como en el caso 2), anterior, asumiendo que el nivel más bajo representa el cero o fracaso y los otros el 1(éxito). 4. Una matriz formada por dos columnas que representan los éxitos y fracasos. En este caso se asume que la primera columna contiene los éxitos (yi ) y la segunda los fracasos (ni − yi ). Tampoco es necesario el argumento weights. Resultados del análisis Coefficients, residuals, fitted.values Representan los coeficientes, residuos, valores ajustados, respectivamente Deviance valor que representa, salvo constante, menos dos veces el máximo del logaritmo de la función de verosimilitud. Por tanto sirve como indicador para bondad de ajuste, especialmente para comparar modelos. AIC Criterio de Información de Akaike. Estadı́stico derivado también de la función de verosimilitud. Nota: En ayuda de R puede encontrar otras funciones que permiten extraer información del modelo ajustado 3.7. REGRESIÓN LOGÍSTICA 3.7.4. 51 Ejemplo con respuesta un vector 1’s y 0’s Si el vector es un factor con 2 niveles, por defecto, R toma la primera categorı́a como fracaso y la segunda como éxito. DATOS En la tabla siguiente se han clasificado varios grupos de personas del conjunto nacional según la Tasa de paro en 2005, Tasa de 2011, Sexo y Edad del grupo. Variable dependiente: Tasa de 2011 (éxito=tasa alta 5 ) Variables independientes: Tasa de 2005, Sexo y Edad del grupo (una continua y dos cualitativas) 5 La variable está definida como factor y explı́citamente se declararon los niveles 1 y 2 como baja y alta, respectivamente 52CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS Sexo Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Hombre Mujer Edad TP2005 TP2011 <30 12.05 baja <30 19.48 alta >30 4.90 baja >30 8.44 baja <30 22.37 alta <30 27.32 alta >30 12.26 baja >30 18.72 baja <30 11.93 alta <30 29.02 alta >30 8.24 baja >30 20.30 baja <30 13.51 alta <30 27.13 alta >30 7.12 baja >30 15.66 baja <30 17.47 baja <30 27.77 baja >30 10.02 baja >30 17.18 baja <30 19.00 baja <30 30.41 alta >30 7.37 baja >30 22.26 baja <30 14.52 alta <30 21.37 alta >30 6.87 baja >30 12.80 baja <30 16.54 alta <30 25.20 baja >30 7.21 baja >30 18.16 baja Especificación teórica del modelo Variable dependiente: TP2011 (clasificada como alta o baja) Variables independientes: TP2005, Sexo y Edad (del grupo) logit = β0 + β1 T P 2005 + β2 F SexoM ujer + β3 F Edad>30 3.7. REGRESIÓN LOGÍSTICA 53 p donde p = P (Y = 1) = P (T P 2011 = alta), y logit = ln 1−p Ajuste del modelo > summary(glm( TP2011~.,family=binomial, data=Regm) ) Call: glm(formula = TP2011 ~ ., family = binomial, data = Regm) Deviance Residuals: Min 1Q Median -1.68342 -0.00009 -0.00007 3Q 0.77459 Max 1.08414 Coefficients: (Intercept) SexoMujer Edad>30 TP2005 Estimate Std. Error z value Pr(>|z|) 1.23058 2.66504 0.462 0.644 1.04330 1.96446 0.531 0.595 -20.80811 2661.99418 -0.008 0.994 -0.04502 0.15970 -0.282 0.778 (Dispersion parameter for binomial family taken to be 1) Null deviance: 41.183 Residual deviance: 19.502 AIC: 27.502 on 31 on 28 degrees of freedom degrees of freedom Number of Fisher Scoring iterations: 18 Observe que ninguna de las variables es significativa cuando se introducen conjuntamente. Eliminando, paso a paso, la menos significativa se obtiene el siguiente modelo ajustado: La única variable independiente que resultó significativa fue la tasa de paro de 2005. Por lo que el modelo se reduce al más simple: Call: glm(formula = TP2011 ~ TP2005, family = binomial, data = Regm) Deviance Residuals: Min 1Q Median 3Q Max 54CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS -1.5900 -0.8914 -0.4587 0.8422 1.8680 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -3.42416 1.29258 -2.649 0.00807 ** TP2005 0.15687 0.06601 2.376 0.01748 * --Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 41.183 Residual deviance: 33.900 AIC: 37.9 on 31 on 30 degrees of freedom degrees of freedom Number of Fisher Scoring iterations: 4 Interpretación del coeficiente que acompaña a la variable independiente: Se espera un incremento medio del logit de 0.157 por cada aumento de una unidad en la tasa de paro del 2005. La Razón de Odds para un aumento de una unidad en la tasa de paro de 2005 viene dada por: eβ1 = e0,157 = 1,17 Por lo que se espera un incremento del 17 por ciento en la ventaja u odds de la respuesta (una tasa de paro alta en 2011) en un grupo que aumente una unidad su tasa de paro en 2005. El modelo ajustado, expresado en logit, viene dado por la ecuación: logit = −3,424 + 0,157 T P 2005 La probabilidad esperada de una tasa alta en 2011 para un grupo que en 2005 tiene una tasa de paro de 45 es igual a p= exp(−3,424 + 0,157 × 45) = 1 + exp(−3,424 + 0,157 × 45) 3.7. REGRESIÓN LOGÍSTICA 55 p = 0,974 La probabilidad esperada de una tasa alta en 2011 para un grupo que en 2005 tiene una tasa de paro de 5 es igual a p= exp(−3,424 + 0,157 × 5) = 1 + exp(−3,424 + 0,157 × 5) p = 0,067 La razón de Odds para un aumento de 10 unidades en la tasa de 2005 de un determinado grupo viene dada por RO(10+1)/1 Odd(10 + 1 = = Odd(1) p(10+1) 1−p(10+1) p(1) 1−p(1) O bien para el logaritmo neperiano: lnRO(10+1)/1 = logit(11) − logit(1) = 10 ∗ β1 que equivale a RO10+1/1 = e10×β1 = e10×0,157 = 4,8 Un grupo que en 2005 presente una tasa 10 puntos superior a otro, casi quintuplica (4,8) la ventaja de tener una tasa de paro alta en 2011 6 3.7.5. Ejemplo de regresión logı́stica con R DATOS En la tabla siguiente se tienen clasificados a varios grupos de personas del conjunto nacional en función de Tasa de paro en 2005, Tasa de 2011, 6 Observe que hablamos de ventaja u odds (no probabilidad). Este concepto está próximo al de riesgo, cuando la probabilidad de éxito es muy baja. Por eso es frecuente que se utilize esta terminologı́a cuando se manejan sucesos raros (de probabilidad próxima a cero, tales como enfermedades raras) 56CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS Nacionalidad y Edad del grupo. La tabla muestra los datos ya tabulados o agrupados con las correspondientes frecuencias. Variable dependiente: Tasa de par en 2011 (éxito=tasa alta) Variables independientes: Tasa de 2005, Nacionalidad y Edad del grupo (todas cualitativas) Edad <30 >30 <30 >30 <30 <30 >30 <30 <30 >30 <30 <30 >30 nacional Español Español Extranjero Extranjero Español Extranjero Extranjero Español Extranjero Extranjero Español Extranjero Extranjero X2005 baja baja baja baja alta alta alta baja baja baja alta alta alta X2011 Freq baja 10 baja 19 baja 5 baja 14 baja 3 baja 3 baja 2 alta 1 alta 5 alta 2 alta 5 alta 6 alta 1 La tabla siguiente muestra los mismos datos, pero estableciendo una columna de éxitos y otra de totales (exitos más fracasos que corresponden a las categorı́as alta y baja de la variable tasa de 2011, respectivamente). A partir de las cuales se deriva la columna de proporción de éxitos (tasas altas). Edad <30 >30 <30 >30 <30 <30 >30 nacional Español Español Extranjero Extranjero Español Extranjero Extranjero X2005 baja baja baja baja alta alta alta exitos Total Prop 1 11 0.09 0 19 0.00 5 10 0.50 2 16 0.12 5 8 0.62 6 9 0.67 1 3 0.33 Especificación teórica del modelo Variable dependiente: Tasa de paro en 2011 (clasificada como alta o baja) 3.7. REGRESIÓN LOGÍSTICA 57 Variables independientes: Tasa de 2005, Sexo y Nacionalidad del grupo de personas logit = β0 + β1 F X2005alta + β2 F nacioExtranj + β3 F Edad>30 p donde p = P (Y = 1) = P (X2011 = alta), logit = ln 1−p Ajuste del modelo(Respuesta vector de 0’s y 1’s) El vector de datos no se muestra aquı́, por motivos de espacio. Call: glm(formula = X2011 ~ ., family = binomial, data = Regm) Deviance Residuals: Min 1Q Median -1.7748 -0.5800 -0.2222 3Q 0.6811 Max 2.1736 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -1.6972 0.6233 -2.723 0.00647 ** Edad>30 -1.9922 0.7654 -2.603 0.00925 ** nacionalExtranjero 1.4261 0.6779 2.104 0.03540 * X2005alta 1.6141 0.6594 2.448 0.01438 * --Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 87.603 Residual deviance: 61.623 AIC: 69.623 on 75 on 72 degrees of freedom degrees of freedom Number of Fisher Scoring iterations: 5 Ajuste del modelo( Respuesta vector de proporciones) El vector de proporciones de éxitos y el vector Total como argumento con pesos o ponderaciones dan lugar al ajuste siguiente: 58CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS Call: glm(formula = Prop ~ X2005 + Edad + nacional, family = binomial, data = s, weights = Total) Deviance Residuals: 1 2 -0.62708 -0.96835 3 0.42793 4 0.40356 5 0.82795 7 -0.88071 8 -0.03608 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -1.6973 0.6233 -2.723 0.00647 ** X2005alta 1.6141 0.6594 2.448 0.01438 * Edad>30 -1.9923 0.7654 -2.603 0.00925 ** nacionalExtranjero 1.4262 0.6779 2.104 0.03540 * --Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 29.1211 Residual deviance: 3.1394 AIC: 25.083 on 6 on 3 degrees of freedom degrees of freedom Number of Fisher Scoring iterations: 4 Nota: observe que en este caso, aunque los coeficientes del modelo son los mismos, los g.l. varı́an, ası́ como el estadı́stico AIC (las filas o casos en la tabla de datos representan un número mayor). Por último, proponemos el ajuste a partir de la matriz de exitos y fracasos. Aquı́ no hace falta el argumento weights. Como una matriz m [1,] [2,] [3,] [4,] [5,] [6,] [7,] [,1] [,2] 1 10 0 19 5 5 2 14 5 3 6 3 1 2 3.7. REGRESIÓN LOGÍSTICA 59 Call: glm(formula = m ~ X2005 + Edad + nacional, family = binomial, data = s) Deviance Residuals: 1 2 -0.62704 -0.96841 3 0.42798 4 0.40351 5 0.82797 7 -0.88080 8 -0.03594 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -1.6972 0.6233 -2.723 0.00647 ** X2005alta 1.6141 0.6594 2.448 0.01438 * Edad>30 -1.9922 0.7654 -2.603 0.00925 ** nacionalExtranjero 1.4261 0.6779 2.104 0.03540 * --Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 29.1199 Residual deviance: 3.1396 AIC: 25.083 on 6 on 3 degrees of freedom degrees of freedom Number of Fisher Scoring iterations: 4 Modelo ajustado Al nivel α = 0,05, las variables son todas importantes para explicar la respuesta. El modelo ajustado expresado en términos de logit es logit = −1,697 + 1,614 F X2005alta + −1,992 F Edad>30 + 1,426 F nacioExtranj Interpretación de los coeficientes 1. El coeficiente de F X2005alta , 1,614, es el cambio esperado en el logit cuando se pasa de un grupo con tasa de paro baja en 2005 a otro de tasa de paro alta en 2005, supuestas estables el resto de las variables. Equivalentemente, podemos decir que la razón de odds, que compara un 60CAPÍTULO 3. REGRESIÓN LINEAL MÚLTIPLE Y CON VARIABLES CUALITATIVAS grupo de tasa alta con otro de tasa baja en 2005, es igual a e1,614 = 5,02. La ventaja de la respuesta (tasa alta de paro en 2011) es 5 veces mayor para el colectivo que presenta una tasa alta en 2005 que para el que presenta una tasa baja en 2005. 2. El coeficiente de F Edad>30 , −1,992, es el cambio esperado en el logit cuando se pasa de un grupo de edad de menos de 30 años a otro de más de 30, supuestas estables el resto de las variables. Equivalentemente, podemos decir que la razón de odds, que compara un grupo de más de 30 años con otro de menos de 30, es igual a e−1,992 = 0,14. La ventaja de la respuesta (tasa alta de paro en 2011) es un 86 % inferior para el colectivo mayor de 30 años que para el de menos de 30. En términos comparativos inversos, podemos decir que la razón de Odds del grupo de menos de 30 años respecto al de más de 30 es igual a e1,992 = 7,33. 3. El coeficiente de F nacioExtranj , 1,426, es el cambio esperado en el logit cuando se pasa de un grupo de nacionalidad española a otro de nacionalidad extranjera, supuestas estables el resto de las variables. Equivalentemente, podemos decir que la razón de odds, que compara un grupo extranjero con otro de nacionalidad española, es igual a e1,426 = 4,16. La ventaja de la respuesta (tasa alta de paro en 2011) es más de 4 veces mayor para el colectivo extranjero que para el español. Cálculo de probabilidades con el modelo ajustado La probabilidad de tasa alta en 2011 para un grupo mayor de 30 años, español y con tasa alta en 2005 se obtiene sustituyendo los valores de las variables (ficticias) en la ecuación del modelo ajustado, mediante: logit = −1,697 + 1,614 − 1,992 = −2,075 y la probabilidad es elogit e−2,075 = = 0,112 1 + elogit 1 + e−2,075 La función R predict() permite determinar las probabilidad ajustadas. p= 3.7. REGRESIÓN LOGÍSTICA 61 Podemos obtener los valores ajustados automáticamente con R (en términos de logit o de probabilidades) para un data.frame especificado como nuevos datos o para los utilizados en el ajuste. Los valores de las variables no pueden cambiar sus nombres. Deben ser los mismos que los utilizados en el ajuste. Las probabilidades ajustadas a las distintas combinaciones de niveles de los datos usados son Edad <30 >30 <30 >30 <30 >30 <30 >30 nacional Español Español Extranjero Extranjero Español Español Extranjero Extranjero Funciones R usadas en tema 3 anova, glm, lm, predict, summary. X2005 baja baja baja baja alta alta alta alta prob 0.155 0.024 0.433 0.094 0.479 0.112 0.793 0.343