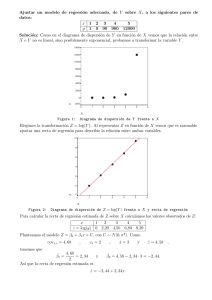
handout - Universidad de Cantabria
Anuncio

Minerı́a de Datos Clasificación multi-clase y el problema del sobreajuste Cristina Tı̂rnăucă Dept. Matesco, Universidad de Cantabria Fac. Ciencias – Ing. Informática – Otoño de 2012 Clasificación multi-clase One-vs-all (1) hθ (x) (2) x2 hθ (x) (3) hθ (x) x1 (i) Para predecir, eliges i tal que hθ (x) = máximo. Sobreajuste o falta de ajuste Regresión lineal Regresión logı́stica hθ (x) = θ0 + θ1 x hθ (x) = g (θ0 + θ1 x1 + θ2 x2 ) hθ (x) = θ0 + θ 1 x + θ2 x 2 hθ (x) = g (θ0 + θ1 x1 + θ2 x2 + θ3 x12 + θ4 x22 + θ5 x1 x2 ) hθ (x) = θ0 +θ1 x + θ2 x 2 + θ3 x 3 + θ4 x 4 hθ (x) = g (θ0 +θ1 x1 +θ2 x12 +θ2 x12 x2 + θ4 x12 x22 + θ5 x12 x3 + θ6 x13 x2 + . . .) Regresión lineal con regularización Función de costo J(θ): m n i=1 j=1 λ X 2 1 X (hθ (x (i) ) − y (i) )2 + θj 2m 2m El gradiente: m ∂ 1 X (i) J(θ) = (hθ (x (i) ) − y (i) ) ∗ x0 ∂θ0 m i=1 m 1 X ∂ (i) J(θ) = [ (hθ (x (i) ) − y (i) ) ∗ xj + λθj ] ∂θj m i=1 (para j = 1, 2 . . . , p ) Regresión logı́stica con regularización Función de costo J(θ): − m n 1 X (i) λ X 2 ( y ∗ log(hθ (x (i) )) + (1 − y (i) ) ∗ log(1 − hθ (x (i) )))+ θj m 2m i=1 j=1 El gradiente: m ∂ 1 X (i) J(θ) = (hθ (x (i) ) − y (i) ) ∗ x0 ∂θ0 m i=1 ∂ 1 J(θ) = [ ∂θj m (para j = 1, 2 . . . , p ) m X i=1 (i) (hθ (x (i) ) − y (i) ) ∗ xj + λθj ]