Varianza
Anuncio

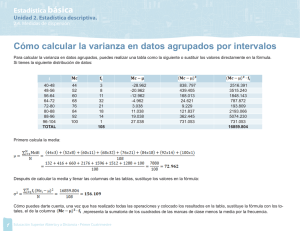
ABC Amber Text Converter Trial version, http://www.thebeatlesforever.com/processtext/ El siguiente material se encuentra en etapa de corrección y no deberá ser considerado una versión final. Alejandro D. Zylberberg <alejandro@probabilidad.com.ar> Versión Actualizada al: 4 de mayo de 2004 Varianza Vimos que la media o esperanza nos da una idea de qué valor podríamos esperar que asuma una determinada variable aleatoria, si se lleva a cabo el experimento al cual está asociada. Es decir, la media es una medida de posición . Asimismo, vimos que la esperanza no nos proporciona información acerca de si los valores que puede tomar la variable aleatoria se encuentran cercanos o espaciados. Por eso utilizaremos otra herramienta matemática denominada varianza. La varianza es una medida de cuánto tienden los valores de una variable aleatoria a alejarse de la media de la misma. La varianza es una medida de dispersión . Dada X una variable aleatoria, si su varianza σX2 existe, vale: ∞ Var ( X ) = σ X = E(( X − E( X )) ) = ∫ ( x − µ X ) 2 f X ( x) dx 2 2 −∞ Vemos que la varianza es la esperanza de los cuadrados de las distancias entre los valores de la variable y el valor medio de la distribución. Si los valores de X están muy dispersos, los E(X)-X tenderán a ser más grandes, y la varianza tiende a ser mayor. Observamos también que como las diferencias están al cuadrado, no importa si son positivas (X a la derecha de la media) o negativas (X a la izquierda de la media). O sea que todas "suman". Operando con la fórmula de arriba se llega a otra fórmula para la varianza, que a menudo resulta más práctica: σ X 2 = E( X 2 ) − E( X ) 2 La varianza también presenta la siguiente propiedad: σ 2 (aX + b) = a 2σ X 2 con a, b ∈ ℜ Mas adelante en esta misma sección se demuestran las fórmulas y propiedades. ABC Amber Text Converter Trial version, http://www.thebeatlesforever.com/processtext/ Comentarios • La varianza es una medida de cuánto tienden los valores de una variable aleatoria a alejarse de la media de la misma. Es decir que si la varianza es chica, la distribución se encuentra concentrada alrededor de la media, y si es grande, se encuentra más esparcida, más dispersa. • Como la varianza se define a partir de la media, puede, al igual que esta, no existir. Ejemplo Volvamos al ejemplo 5 de la media: Tenemos la distribución de X e Y, y calculamos sus medias: 0,2 x=3 x=4 0,3 PX ( x) = 0,3 x=5 x=6 0,2 0 ∀ otro x 0,2 x=2 +∞ x=3 0,3 E ( X ) = ∑ x PX ( x) = 3.0,2 + 4.0,3 + 5.0,3 + 6.0,2 = 4,5 PY ( y ) = 0,3 x=6 −∞ +∞ =7 0 , 2 x = = + + + = 0 ∀ otro x E (Y ) ∑ y PY ( y ) 2.0,2 3.0,3 6.0,3 7.0,2 4,5 −∞ Habíamos observado que las medias de X e Y son iguales, a pesar de que Y está más dispersa que X: Veamos qué sucede con las varianzas: +∞ E ( X 2 ) = ∑ x 2 PX ( x) = 3 2 .0,2 + 4 2 .0,3 + 5 2 .0,3 + 6 2 .0,2 = 21,3 −∞ +∞ E (Y 2 ) = ∑ y 2 PY ( y ) = 2 2 .0,2 + 3 2 .0,3 + 6 2 .0,3 + 7 2 .0,2 = 24,1 −∞ σx 2 = E ( X 2 ) − E ( X ) 2 = 21,3 − 4,5 2 = 1,05 σy 2 = E (Y 2 ) − E (Y ) 2 = 24,1 − 4,5 2 = 3,85 Vemos que la varianza de Y es casi 4 veces mayor que la varianza de X. Esto refleja que las probabilidades de los valores de Y se encuentan más alejados ABC Amber Text Converter Trial version, http://www.thebeatlesforever.com/processtext/ de la media que los de X. Desvío estándar El desvío estándar σX de una variable aleatoria X se define como la raíz cuadrada positiva de su varianza. σx = σx 2 Unidades Si X es la longitud de los tornillos fabricados por una máquina, entonces las unidades de X podrían ser, por ejemplo, cm. A su vez, como la media o esperanza es el valor esperado de X, tiene la misma forma que X (sea un valor posible realmente o no). Entonces las unidades de E(X) deben ser las mismas que las de X, es decir, cm. σ 2 = E( X 2 ) − E( X )2 La varianza se puede obtener, por ejemplo, X , donde se ve 2 claramente que las unidades de la varianza son cm . Y como el desvío estándar se define como la raíz cuadrada de la varianza, entonces sus unidades vuelven a ser las de X, es decir, cm. Demostraciones Comenzaremos por probar que: ∞ σ X = E(( X − E( X )) 2 ) = ∫ ( x − µ X ) 2 f X ( x) dx = E( X 2 ) − E( X ) 2 2 −∞ Partimos de: σ X 2 = E(( X − E( X )) 2 ) Como dada una distribución, su esperanza es una constante, vamos a escribir, por claridad, µ X en vez de E(X). σ X 2 = E(( X − µ X ) 2 ) Notemos que (X - µ X)2 es una función de X. Luego su esperanza vale: ∞ σ X = ∫ ( x − µ X ) 2 f X ( x) dx 2 −∞ Con lo cual llegamos a la segunda fórmula dada. Ahora desarrollemos el cuadrado: ABC Amber Text Converter Trial version, http://www.thebeatlesforever.com/processtext/ ∞ ∫ (x 2 + µ X 2 − 2xµ X ) f X ( x) dx −∞ Abrimos la integral en tres: ∞ ∫x ∞ 2 −∞ ∞ f X ( x) dx + ∫ µ X f X ( x) dx − ∫ 2xµ X f X ( x) dx 2 −∞ −∞ Como 2 y µ X son constantes, salen de las integrales: ∞ ∫x 2 f X ( x) dx + µ X ∞ 2 −∞ ∫ −∞ ∞ f X ( x) dx − 2µ X ∫ x f X ( x) dx −∞ El primer término es, por definición de esperanza de una función, E(X 2). En el segundo término, la integral da uno. La integral del tercer término es por definición la esperanza de X, es decir, µ X. Queda: E( X 2 ) + µ X 2 − 2µ X 2 Con lo cual llegamos a la tercera fórmula dada: σ X 2 = E( X 2 ) − E( X ) 2 Ahora vamos a demostrar la propiedad: σ 2 (aX + b) = a 2σ X 2 Llamaremos Y = a X + b. Luego por definición de varianza: σ Y 2 = E (( Y − E (Y )) 2 ) Reemplazando Y por a X + b obtenemos: 2 σ aX = E (( aX + b − E ( aX + b )) 2 ) = E (( aX + b − aE ( X ) − b ) 2 ) = E (( aX − a µ X ) 2 ) +b Sacando factor común a, y sacándola del cuadrado y de la esperanza, queda: 2 σ aX = E ( a 2 ( X − µ X ) 2 ) = a 2 E (( X − µ X ) 2 ) +b El segundo factor es por definición la varianza de X. Luego, como queríamos demostrar: σ 2 ( aX + b ) = a 2 σ 2 X Puede parecer extraño que la b no aparezca en la varianza de a X + b, pero no lo es. La constante b no tiene ninguna influencia en la varianza porque es una constante que aparece sumando, y que a lo sumo puede correr la distribución hacia la izquierda o hacia la derecha, es decir, cambiar la posición , pero no la dispersión . Además podemos hacer el comentario de que la varianza de una constante es cero, porque la varianza es una medida de dispersión, y como una constante es un punto, no tiene dispersión. Luego su varianza es cero. Problemas típicos ABC Amber Text Converter Trial version, http://www.thebeatlesforever.com/processtext/ 1) Halle varianza y el desvío estándar de X, donde X está distribuida según: 0,4 x = −1 x =1 0,1 PX ( x) = 0,3 x=2 x=3 0,2 0 ∀ otro x Resolución: +∞ E ( X ) = ∑ x PX ( x ) = ( −1). 0,4 + 1.0,1 + 2.0,3 + 3.0,2 = 0,9 −∞ +∞ E ( X 2 ) = ∑ x 2 PX ( x ) = ( −1) 2 .0,4 + 12 .0,1 + 2 2 .0,3 + 3 2 .0,2 = 3,5 −∞ σx = E ( X 2 ) − E ( X ) 2 = 2,69 2 σx = σx 2 =1,64 2) La longitud en cm. de las varillas fabricadas por una máquina es la variable aleatoria X distribuida según: x 2 1 fX ( x ) = 3 0 0 ≤ x ≤ 1 1 ≤ x ≤ 3 ∀ otro x a) ¿Cuál es la varianza de la longitud media de las varillas? b) Si a las varillas se las corta a la mitad y se les agrega una punta de 1 cm., ¿Cuál es la varianza de la longitud de las nuevas varillas? Resolución: E( X ) = +∞ ∫x f −∞ a) E( X ) = 2 +∞ ∫x −∞ 2 X 1 3 1 ( x) dx = ∫ x x 2 dx + ∫ x dx = 1,583 3 0 1 1 3 0 1 fX ( x) dx = ∫ x 2 x 2 dx + ∫ x 2 1 dx = 3,089 3 σx = E ( X ) − E ( X ) = 0,582 2 b) 2 2 1 1 2 σ 2 ( aX + b) = a 2σx 2 => σ 2 x + 1 = σx 2 = 0,145 2 2 3) Si dos máquinas producen piezas cuyas longitudes son variables aleatorias de igual media, pero la varianza de la longitud de las piezas fabricadas por la máquina A es mayor que la varianza de las de B, y es importante que todas las piezas sean lo más parecidas posibles, ¿cuál máquina decidiría comprar? ABC Amber Text Converter Trial version, http://www.thebeatlesforever.com/process Resolución: Como la varianza es una medida de la tendencia de los valores de la variable a alejarse de la media, eligiendo la máquina B las piezas fabricadas tenderán a ser de longitudes más parecidas.