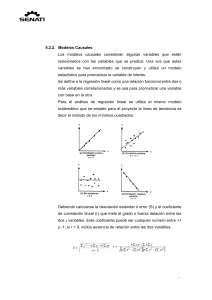
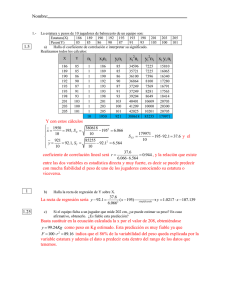
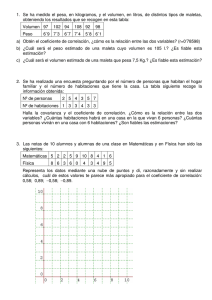
Probabilidad Y Estadística Unidad 5: INVESTIGACIÓN ISMA-2 Alumnos: Johan Jared Chay Chin Docente: Ing. Guillermina Velazco Viveros “Regresión y Correlación” 5.1 REGRESIÓN Y CORRELACIÓN 5.1.1 Diagrama de dispersión. Tipo de diagrama que utiliza las coordenadas cartesianas para mostrar los valores de dos variables para un conjunto de datos. Se le llama así pues los datos se muestran como un conjunto de puntos, cada uno con el valor de una variable que determina la posición en el eje horizontal y el valor de la otra variable determinado por la posición en el eje vertical, teniendo una línea de ajuste (línea de tendencia) con el fin de estudiar la correlación entre las variables. Son muy útiles a la hora de expresar los resultados numéricos de un experimento. Aunque los gráficos de líneas son parecidos, los puntos de datos en un diagrama de dispersión no están conectados directamente. En su lugar, sirven para mostrar la tendencia general representada por los datos. 5.1.2Regresión lineal simple. Diagrama que tiene como objeto estudiar cómo los cambios en una variable, no aleatoria, afectan a una variable aleatoria, en el caso de existir una relación funcional entre ambas variables que puede ser establecida por una expresión lineal, es decir, su representación gráfica es una línea recta. La manera de obtener la regresión lineal es mediante la ecuación del “menor ajuste” 𝒚 = 𝒂 + 𝒃𝒙 Dónde: Y representa los valores de la coordenada a lo largo del eje vertical en el gráfico (ordenada); en tanto que “x” indica la magnitud de la coordenada sobre el eje horizontal (abscisa). El valor de “a” (que puede ser negativo, positivo o igual a cero) es llamado el intercepto; en tanto que el valor de “b” (el cual puede ser negativo o positivo) se denomina la pendiente o coeficiente de regresión. 5.1.3 Correlación. Se encuentra con el análisis de regresión y ambos pueden ser considerados como dos aspectos de un mismo problema. La correlación entre dos variables es - otra vez puesto en los términos más simples el grado de asociación entre las mismas. Este es expresado por un único valor llamado coeficiente de correlación (r), el cual puede tener valores que oscilan entre -1 y +1. Cuando “r” es negativo, ello significa que una variable (ya sea “x” o “y”) tiende a decrecer cuando la otra aumenta (se trata entonces de una “correlación negativa”, correspondiente a un valor negativo de “b” en el análisis de regresión). Cuando “r” es positivo, en cambio, esto significa que una variable se incrementa al hacerse mayor la otra (lo cual corresponde a un valor positivo de “b” en el análisis de regresión). Pudiendo ser de 3 formas: Positiva (aumento) Negativa (descenso) Nula (cuando las variables no están correlacionadas) Correlación Positiva Correlación Negativa Correlación Nula Otra clasificación de la correlación es el grado que indica que tanta proximidad hay entre los puntos Correlación fuerte: cuando los puntos estén cerca de la recta Débil: cuando los puntos están más separados de las rectas 5.1.4 Determinación y análisis de los coeficientes de correlación y determinación. El coeficiente de determinación denominado R² y pronunciado R cuadrado, es un estadístico usado en el contexto de un modelo estadístico cuyo principal propósito es predecir futuros resultados o testear una hipótesis determinando la calidad del modelo para replicar los resultados, y la proporción de variación de los resultados que puede explicarse por el modelo. “R² es el cuadrado del coeficiente de correlación de Pearson” El coeficiente de correlación (r) requiere variables medidas en escala de intervalos o de proporciones (Variando entre -1 y 1.) Valores de -1 o 1 indican correlación perfecta. (Valor igual a 0 indica ausencia de correlación) Valores negativos indican una relación lineal inversa y valores positivos indican una relación lineal directa. 5.1.5 Distribución normal bidimensional Es un caso particular de la distribución normal n-dimensional para n=2. Una distribución normal es bidimensional si su función de densidad conjunta definida en R2 es de la forma: Donde μX y μY son las medias de X e Y respectivamente, σX y σY sus desviaciones típicas y p el coeficiente de correlación lineal entre las dos variables. Coeficiente de correlación La razón de la variación explicada a la variación total se llama coeficiente de determinación. Si la variación explicada es cero, es decir, la variación total es toda no explicada, esta razón es cero. Si la variación no explicada es cero, es decir, la variación total es toda explicada, la razón es uno. En los demás casos la razón se encuentra entre cero y uno. Puesto que la razón es siempre no negativa, se denota por r2 . La cantidad r se llama coeficiente de correlación y esta dado por: Y varía entre -1 y +1, los signos ± se utilizan para la correlación lineal positiva y la correlación lineal negativa, respectivamente. Nótese que r es una cantidad sin dimensiones, es decir, no depende de las unidades empleadas. De esta manera un valor de r igual a +1 implica una relación lineal perfecta con una pendiente positiva, mientras que un valor de r igual a -1 resulta de una relación lineal perfecta con pendiente negativa. Se puede decir entonces que las estimaciones muéstrales de r cercanas a la unidad en magnitud implican una buena correlación o una asociación lineal entre X y Y, mientras que valores cercanos a cero indican poca o ninguna correlación. Otra forma de medir el coeficiente de correlación muestral es: 5.1.6 Intervalos de confianza y pruebas para el coeficiente de correlación. Para el cálculo válido de un intervalo de confianza del coeficiente de correlación de r ambas variables deben tener una distribución normal. Si los datos no tienen una distribución normal, una o ambas variables se pueden transformar (transformación logarítmica) o si no se calcularía un coeficiente de correlación no paramétrico (coeficiente de correlación de Pearson) que tiene el mismo significado que el coeficiente de correlación de Pearson y se calcula utilizando el rango de las observaciones. La distribución del coeficiente de correlación de Pearson NO ES NORMAL pero no se puede transformar r para conseguir un valor z (transformación de Fisher) y calcular a partir del valor z el intervalo de confianza. Donde Ln representa el logaritmo neperiano que en la base es: N= tamaño muestral. Para hallar el intervalo de confianza de Z se hace lo siguiente: Tras calcular los intervalos de confianza con el valor z debemos volver a realizar el proceso inverso para calcular los intervalos del coeficiente r Puede calcularse en cualquier grupo de datos, sin embargo, la validez del test de hipótesis sobre la correlación entre las variables requiere en sentido estricto: que las dos variables procedan de una muestra aleatoria de individuos. que al menos una de las variables tenga una distribución normal en la población de la cual la muestra procede. 5.1.7 Errores de medición. Toda medición siempre irá acompañada de una incertidumbre. El resultado de una medición, es el conjunto de dos valores: el valor obtenido en la medición y la incertidumbre. Siempre que realizamos una medición cometeremos un error en la determinación de la magnitud medida. Este error puede ser despreciable en función de la precisión requerida. Definiremos como error a la diferencia entre la dimensión determinada en la medida y la dimensión real. Se puede producir error de medición por causas que determinan su ocurrencia en forma aleatoria (error aleatorio) o bien ser efecto de un error que ocurre en forma sistemática (sesgo). Error grave: se debe principalmente a fallas humanas en la lectura o utilización de los instrumentos, así como en el registro y cálculo de los resultados de las mediciones. Error sistemático: se puede presentar como consecuencia de un efecto reconocido de una magnitud de influencia en el resultado de una medición o por defectos en el instrumento de medida. Error instrumental: son inherentes a los instrumentos de medición a causa de su estructura mecánica. Se pueden presentar por no ajustar el cero antes de realizar mediciones, por una calibración inadecuada del instrumento, etc. Error ambiental: se deben a las condiciones externas que afectan la operación del dispositivo de medición como los efectos por cambios de: temperatura, humedad, presión barométrica o de campos magnéticos y electrostáticos. Error estático: se originan por las limitaciones de los dispositivos de medición o las leyes físicas que dominan su comportamiento. Error dinámico: se ocasiona cuando el instrumento no responde con la suficiente rapidez a los cambios de la variable de medida Error aleatorio: se presenta por variaciones impredecibles o estocásticas, temporales y espaciales de las magnitudes de influencia. Se puede reducir aumentando el número de observaciones.