Supuestos del modelo de regresion lineal
Anuncio

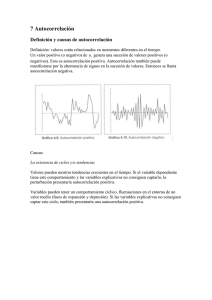
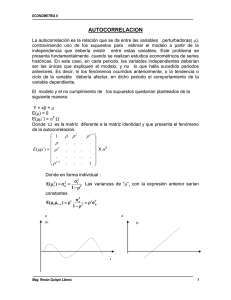
VERIFICACION SUPUESTOS DEL MODELO DE REGRESION LINEAL SIMPLE PRESENTADO POR: MARIA PAZ MUÑOZ GARCIA-2010193301 MATERIA: ECONOMETRIA UNIVERSIDAD SURCOLOMBIANA FACULTAD DE ECONOMIA Y ADMON. PROGRAMA ECONOMIA NEIVA-HUILA 2012 Verificación de los supuestos normalidad La hipótesis de normalidad afirma que los errores del modelo siguen una distribución normal. Esta hipótesis se contrasta a partir de los residuos estandarizados. Causas Existen observaciones heterogéneas: En este caso se debe averiguar la causa que origina estas observaciones: errores en la recogida de datos; el modelo especificado no es correcto porque se han omitido variables regresoras (por ejemplo, no se ha tenido en cuenta una variable de clasificación cuando las observaciones proceden de diferentes poblaciones). - Existe asimetría en la distribución. En este caso suele ser conveniente transformar la variable respuesta. Este problema suele estar relacionado con otros problemas como falta de linealidad o heterocedasticidad, la solución de transformar las observaciones pueden resolverlos conjuntamente. Formula estadística Homocedasticidad en los residuos Autocorrelación -Trabajo con datos de serie temporal: cuando se trabaja con datos de corte longitudinal (p.e.: una variable explicativa cuyas observaciones correspondan a valores obtenidos en instantes temporales sucesivos), resulta bastante frecuente que el término de perturbación en un instante dado siga una tendencia marcada por los términos de perturbación asociados a instantes anteriores. Este hecho da lugar a la aparición de Autocorrelación en el modelo. -Especificación errónea determinista del modelo. en la parte -Omisión de variables relevantes: en tal caso, las variables omitidas pasan a formar parte del término de error y, por tanto, si hay correlación entre distintas observaciones de las variables omitidas, también la habrá entre distintos valores de los términos de perturbación. -Variables independientes que posean un gran recorrido con respecto a su propia media. -Omisión de variables importantes dentro del modelo a estimar. -Cambio de estructura. -Utilizar variables no relativizadas. -Cálculo incorrecto de las varianza y parámetros ineficientes. -Invalidación de los contrastes de significancia. - Especificación incorrecta de la forma funcional del modelo: si usamos un modelo inadecuado para describir las observaciones, notaremos que los residuos muestran comportamientos no aleatorios. -Transformaciones de los datos: determinadas transformaciones del modelo original podrían causar la aparición de Autocorrelación en el término de perturbación del modelo transformado (incluso cuando el modelo original no presentase problemas de Autocorrelación). u~N(0,δ2 IT) Para contrastar la normalidad se analizan los residuos del modelo estimado, clasificandolos en intervalos y comparando la frecuencia de cada intervalo con la que le correspondería bajo el supuesto de normalidad. Métodos de Gráficos medición para normalidad son: observar la -el histograma -estimador núcleo de la densidad de Rosenblatt-Parzen - gráfico p - p - gráfico q - q. -Análisis grafico de los Residuos. -Test de Durbin y Watson: Es la prueba más conocida para detectar correlación serial; permite contrastar si el término de perturbación está autocorrelacionado. -Otros contrastes (LM, Q, ...) La heterocedasticidad se detecta en los gráficos de residuos Contrastes: -contraste kurtosis. de asimetría y -contraste chi-cuadrado. -contraste de Smirnov-Liliefors. Kolmogorov- Métodos de -Introducir variables Dummy. ajuste Especificacion de modelos AR autorregresivos -Cambiar la especificación. -La consecuencia más grave de la Autocorrelación de las perturbaciones es que la estimación MCO deja de ser eficiente y la inferencia estadística también se verá afectada. Las consecuencias dependen del tipo de Autocorrelación (positiva o negativa): -Los estimadores mínimocuadráticos no son eficientes (de mínima varianza). -Cuando se tiene Autocorrelación positiva, la matriz de varianza y covarianza de los residuos esta subestimada, si el tipo de Autocorrelación es negativa, se tiene una sobrestimación de la misma. - Cuando se tiene Autocorrelación positiva, la Efectos en matriz de varianza y covarianza de los -Los intervalos de confianza de el modelo coeficientes (betas) esta subestimada, si el los parámetros del modelo y los contrastes de significación son solamente aproximados y no exactos. tipo de Autocorrelación es negativa, se tiene una sobrestimación de la misma. -Cuando se tiene Autocorrelación positiva, los intervalos de confianza son angostos, si el tipo de Autocorrelación es negativa, se tienen intervalos de confianza más amplios. -Cuando se tiene Autocorrelación positiva, se tiende a cometer error tipo I (rechazar la hipótesis nula cuando es verdadera), si el tipo de Autocorrelación es negativa, se tiende a cometer error tipo II (no rechazar la hipótesis nula cuando es falsa). -Transformar los datos: En muchos casos es suficiente con tomar logaritmos en la variable. Por otra parte, el problema puede estar ligado a otros problemas como falta de normalidad, falta de linealidad que, normalmente, también se resuelven al hacer la transformación. La falta de Homocedasticidad influye en el modelo de regresión lineal, los estimadores mínimocuadráticos siguen siendo centrados pero no son eficientes y las fórmulas de las varianzas de los estimadores de los parámetros no son correctas. Por tanto no pueden aplicarse los contrastes de significación