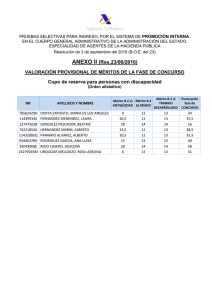
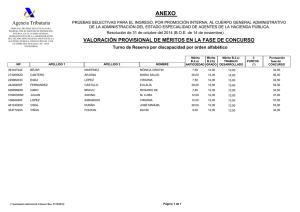
Funciones de mérito
Anuncio

Funciones de mérito
José Francisco Tudón Maldonado
Mario Roberto Urbina Núñez
9 de abril de 2011
1.
Introducción
Las funciones de mérito surgen para determinar en un algoritmo que
resuelve un problema de optimización si el siguiente iterando es mejor o peor
que la iteración anterior en el sentido de acercarse más a la solución, en el
caso de ecuaciones no lineales. En optimización no lineal con restricciones se
busca balancear entre violar las restricciones y acercarse más a la solución.
La función de mérito es una función de x donde se obtiene un escalar que
determina cuál es la mejor iteración.
Funciones de Mérito en Ecuaciones No Lineales
En ecuaciones no lineales las funciones de mérito más utilizadas son las
siguientes:
n
1
1X 2
f (x) =
kr(x)k2 =
r (x)
2
2 i=1 i
f (x) = kr(x)k1 =
n
X
|ri (x)|
i=1
Funciones de Mérito en Optimización con Restricciones
En optimización sin restricciones la función de mérito es la función objetivo. Incluso en optimización con restricciones la función de mérito es la función
objetivo si la solución inicial y todos los iterandos siguientes satisfacen las
restricciones.
En el caso donde se violan las condiciones, una función de mérito popular
es la siguiente:
1
φ1 (x; µ) = f (x) + µ
X
|ci (x)| + µ
i∈E
X
|ci (x)|−
i∈I
Donde [z] = max {0, −z} .
El escalar positivo µ es el parámetro de penalización que nos indica la
importancia de satisfacer la restricción relativa a la minimización.
Otra elección es el Lagrangeano aumentado de Fletcher que es el siguiente:
−
1 X
φF (x; µ) = f (x) − λ(x)T c(x) + µ c2i (x),
2 i∈I
−1
conλ = A(x)A(x)T
A(x)∇f (x), µ > 0
y donde A(x) es el Jacobiano de c(x).
Existen algoritmos basados en funciones de mérito que convergen rápidamente saltando pasos que progresan muy bien a la solución. Esto se conoce como
el efecto Maratos.
Efecto Máratos
El efecto Maratos sucede si en algunos algoritmos basados en las funciones
de mérito y ltros pueden fallar de converger rápidamente, porque rechazan
pasos que hacen buenos progresos hacia la solución. En el siguiente ejemplo
los pasos pk , donde se obtendría convergencia cuadrática si se aceptara,
este rechazo causa incremento de la función objetivo y en la violación de la
restricción.
La Figura 1 es la gráca de la siguiente función: mı́n f (x1 , x2 ) = 2(x21 +
2
x2 − 1) − x1 . s.a. x21 + x22 − 1 = 0. La solución es x∗ = (1, 0)T , el multiplicador
de Lagrange es λ∗ = 1.5 y el Hessiano es la identidad. En la gráca se muestra
que debido a la función de mérito, la gráca no converge al óptimo y viola
las restricciones en el paso xk+1 = xk + pk .
Funciones de Mérito en Programación Cuadrática Sucesiva
En SQP se utilizan para aceptar o rechazar el paso de prueba.
Para la evaluación de la función de mérito las restricciones de desigualdad
c(x) ≥ 0 se convierten en la siguiente manera:
_
c(x, s) = c(x) − s = 0, con s ≥ 0 vector de holgura.
Entonces la función de mérito es la siguiente:
2
Figura 1: Efecto Máratos
3
φ1 (x; µ) = f (x) + µ kc(x)k1 .
En los métodos de búsqueda lineal, el paso αk pk se aceptará si la siguiente
condición suciente de decrecimiento se cumple:
φ1 (xk + αk pk ; µk ) ≤ φ1 (xk ; µk ) + ηαk D (φ1 (xk ; µ); pk ) , η ∈ (0, 1)
D (φ1 (xk ; µk ); pk ) es la derivada direccional en dirección en pk y pk es
dirección de descenso si D (φ1 (xk ; µ); pk ) < 0.
Esto se sostiene para µ sucientemente grande. Se verá en el siguiente
teorema.
2.
El Teorema
Teorema 1 (Teorema 18.2 de Nocedal-Wright).
por la
k -ésima
pk
dirección de
Sean
pk
y
λk+1
generadas
iteración SQP. Entonces la derivada direccional de
φ1
en la
satisface:
D(φ1 (xk ; µ); pk ) = ∇fkT pk − µ||ck ||1 .
Además, se cumple que
D(φ1 (xk ; µ); pk ) ≤ −pTk ∇2xx Lk pk − (µ − ||λk+1 ||∞ )||ck ||1 .
Para que el lector recuerde:
Denición 2 (Derivada direccional). Sean x, u ∈ Rn y f : Rn → R, entonces
la derivada direccional de f en la dirección de u, con ||u|| = 1 es:
∇u f (x) = limh→0
f (x + hu) − f (x)
.
h
Si f es diferenciable en x,
∇u f (x) = ∇f (x)T u.
Demostración del Teorema 18.2
Primero, le aplicamos el teorema de Taylor a f y a ci para encontrar una
cota superior a φ1 (xk + αp; µ) − φ1 (xk ; µ). Sabemos que, para t ∈ (0, 1):
α2 pT ∇2 f (xk + tαp)p
2
T
2
2
≤ α∇fk p + γ1 α ||p|| ,
f (xk + αp) − fk = α∇fkT p +
4
para alguna constante γ1 .
Similarmente, para cada i = 1, ..., m:
α2 pT Hi (xk + tαp)p
2
2
≤ ci,k + αAi,k p + γi,2 α ||p||2 ,
ci (xk + αp) = ci,k + αAi,k p +
donde γi,2 es otra constante. Nótese que:
||c(xk + αp)||1 ≤ ||ck + αAk p + γ2 α2 ||p||2 ||1
≤ ||ck + αAk p||1 + ||γ2 α2 ||p||2 ||1 .
Denimos ahora γ20 = ||γ2 ||1 .
Por lo tanto,
φ1 (xk + αp; µ) − φ1 (xk ; µ) = f (xk + αp) − fk
+ µ|c(xk + αp)| − µ|ck |
≤ α∇Tk p + µ|ck + αAk p|
− µ|ck | + γα2 ||p||2 ,
donde γ = γ1 + γ20 .
Si consideramos que p = pk , donde pk es tal que Ak pk = −ck , entonces,
para α ≤ 1:
φ1 (xk + αp; µ) − φ1 (xk ; µ) ≤ α ∇fkT pk − µ|ck | + α2 γ||pk ||2 .
Del mismo modo, también podemos construir una cota inferior, concluyendo que:
α ∇fkT pk − µ|ck | − α2 γ||pk ||2 ≤ φ1 (xk + αp; µ) − φ1 (xk ; µ)
≤ α ∇fkT pk − µ|ck | + α2 γ||pk ||2 .
Dividiendo entre α y sacando el límite → 0, se obtiene el resultado:
limα→0
φ1 (xk + αp; µ) − φ1 (xk ; µ)
= ∇fkT pk − µ|ck |.
α
Como la p = pk , es la misma que en:
∇2xx Lk −ATk
Ak
0
pk
λk+1
podemos substituir:
5
=
−∇fk
−ck
,
D(φ1 (xk ; µ); pk ) = ∇fkT pk − µ|ck |
= −pTk ∇2xx Lk pk + pTk ATk λk+1 − µ|ck |
= −pTk ∇2xx Lk pk − cTk λk+1 − µ|ck |
≤ −pTk ∇2xx Lk pk − |ck ||λk+1 |∞ − µ|ck |
3.
Consecuencias del Teorema
Como D (φ1 (xk ; µ); pk ) ≤ −pTk ∇2xx Lx − (µ − kλk+1 k∞ ) kck k1 , entonces pk
es una dirección de descenso si
µ > kλk+1 k∞ .
Una manera de obtener µ de φ1 (xk ; µk ) para cada iterando es la siguiente:
D (φ1 (xk ; µ); pk ) = ∇fkT pk − µ kck k1 ≤ −ρµ kck k1 ,
para alguna ρ ∈ (0, 1).
La desigualdad se sostiene si
µ≥
∇fkT pk
.
(1 − ρ) kck k1
Alternativamente...
Una estrategia más efectiva para seleccionar a µ, que sirve para búsqueda
lineal y región de conanza, considera el efecto del paso en un modelo de la
función de mérito. Se dene un modelo cuadrático de φ1 como:
qµ (p) ≡ fk + ∇fkT p +
σ T 2
p ∇xx Lk p + µm(p),
2
donde
m(p) ≡ |ck + Ak p|,
y σ está por denirse.
Después de computar pk , se escoge el parámetro µ tan grande como para
hacer que
qµ (0) − qµ (pk ) ≥ ρµ [m(0) − m(p)] ,
6
para algún ρ ∈ (0, 1). Se sigue que
µ≥
∇fkT pk + σ2 pTk ∇2xx Lk pk
.
(1 − ρ)|ck |
Por lo tanto, si el valor de µ de iteración anterior satisface la desigualdad, no se cambia. De otro modo, µ se incrementa a discreción para que la
satisfaga.
La constante σ sirve para manejar los casos en donde ∇2xx Lk no es positiva
denida. Si denimos
σ≡
1 si pTk ∇2xx Lk pk > 0
0 e.o.c.
se verica que si µ satisface la desigualdad, σ asegura que pk sea una dirección
de descenso para φ1 .
Sin embargo, no siempre se cumple si σ = 1 y pTk ∇2xx Lk pk < 0.
Cuando σ > 0, la ésta estrategia escoge una mayor µ, poniendo más peso
en la reducción de las restricciones. Ésta propiedad es ventajosa si el paso
decrece las restricciones pero incrementa el objetivo, ya que en éste caso, el
paso tendría más probabilidad de ser aceptado por la función de mérito.
7