metnum1212
Anuncio

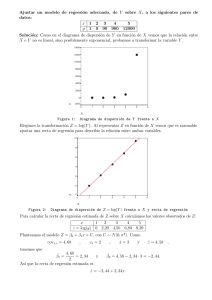
Métodos Numéricos: Ajuste por mı́nimos cuadrados Eduardo P. Serrano Versión previa abr 2012 1. El promedio. Dados los valores (yk ), k = 1, 2, . . ., n, su promedio: 1X yk n n m= k=1 es la constante que mejor los ajusta. Esto significa que los errores (m − yk ) suman cero; n X (m − yk ) = 0 k=1 y su norma cuadrática E(m) = n X (m − yk )2 k=1 es mı́nima, comparada con cualquier otra constante de ajuste. En efecto, si se plantea hallar la constante c que minimiza la expresión cuadrática E(c) = n X (c − yk )2 k=1 derivando e igualando a cero: E 0 (c) = 2 n X (c − yk ) = 0 k=1 de donde se deduce que c = m es la única solución óptima. Ej:- Si y = 4.5, 3.3, 5.1, 5.3, 3.8 su promedio es: m= 1 1 (4.5 + 3.3 + 5.1 + 5.3 + 3.8) = (22) = 4.4 5 5 Los errores son: (4.5 − 4.4), (3.3 − 4.4), (5.1 − 4.4), (5.3 − 4.4), (3.8 − 4.4) = 0.1, −1.1, 0.7, 0.9, −0.6 suman cero y el error cuadrático es E = 2.88, mı́nimo. 2. Recta de Regresión. Extendiendo el concepto, dados los datos (xk , yk ), k = 1, 2, . . ., n, se prtende ajustar por una recta: y(x) = ax + b de modo que los errores sumen cero; n X (y(xk ) − yk ) = k=1 n X ((axk + b) − yk ) = 0 k=1 y el error cuadrático n X 2 (y(xk ) − yk ) = k=1 n X ((axk + b) − yk )2 k=1 sea mı́nimo. Para hallar los coeficientes óptimos pueden calcularse las respectivas derivadas parciales e igualarlas a cero: Pn 2 ∂ k=1 ((axk + b) − yk ) = 0 ∂a Pn 2 ∂ k=1 ((axk + b) − yk ) = 0 ∂b Desarrollando se obtienen las ecuaciones normales: ! ! n n X X 2 xk a + xk b = k=1 k=1 n X xk ! a+n b = k=1 n X xk yk k=1 n X yk k=1 que permiten calcular los coeficientes a y b. Ej: - Datos (xk , yk ): 4.5, 3.3, 5.1, 5.3, 3.8 5, 12, 15, 25, 24 Calculamos: Sxx = 5 X x2k = 55 k=1 Sx Sxy Sy = 5 X xk = 15 = k=1 n X xk yk = 290 = k=1 n X yk = 80 k=1 n = 5 Entonces, las ecuaciones normales son: ( 55a + 15b = 290 15a + 5b = 80 de donde: ( a b = 5.1 = 0.9 por tanto la recta de ajuste es: y(x) = 5.1x + 0.9 3. Ajuste mediante una exponencial. El ajuste exponencial suele aplicarse cuando los datos yk son positivos y decrecientes. Responde a la fórmula no lineal: y(x) = αeβx Tomando logaritmos se transforma en un problema de ajuste lineal: log y(x) = log(α) + βx Llamando ỹ = log(y) a=β b = log(α) se procede a hallar los coeficientes de la regresión: ỹ(x) = ax + b y luego, se obtiene: ( -Ej: - Se desa ajustar los datos (xk , yk ): 0.1 0.2 91 80 α = eb β=a 0.3 0.4 75 70 0.5 60 mediante una exponencial. Transformamos los datos en la forma: (xk , yk ) → (xk , log(yk )) : 0.1 0.2 0.3 0.4 0.5 4.51 4.38 4.32 4.25 4.1 Las ecuaciones normales resultan: de donde, resolviendo: ( .55a + 1.5b = 6.37 1.5a + 5b = 21.56 ( a = −0.95 b = 4.60 por tanto ( β = −0.95 α = 99.5 y la aproximación exponencial es: 4. y(x) = 99.5 e−0.95x Regresión lineal. En genral, dados los datos (xk , yk ), k = 1, 2, . . ., n, la técnica general de aproximación por mı́nimos cuadrados o regresión lineal, consiste en ajustar mediante una función modelo, que pueda expresarse como suma algebraica funciones elementales conocidas: y(x) = a1ϕ1 (x) + a2 ϕ2(x) + · · · + am ϕm (x) Se determinan los coeficientes de modo que el error cuadrático sea mı́nimo: E= n X (y(xk ) − yk )2 k=1 Las ecuaciones lineales corresondientes para obtener los coeficientes se denominan ecuaciones normales y pueden obtenerse derivando, como en el caso de la recta o por otros métodos geométricos. Ej: - En el caso de la recta de regresión tomamos ϕ2 (x) = x y ϕ1 ≡ 1. - Si ϕ3(x) = x2 y ϕ2(x) = x y ϕ1 ≡ 1 el ajuste se reliza mediante una parábola: y(x) = a3 x2 + a2x + a1 - Puede ajustarse mediante otras funciones, por ejemplo, trigonométricas: y(x) = a3 cos(x) + a2 sin(x) + a1 5. Planteo geométrico del problema. Dados los datos (xk , yk ), k = 1, 2, . . ., n y las fucniones ϕ1 (x), . . . , ϕm (x) formamos la matriz de dimensión n × m: ϕ1 (x1) . . . ϕm (x1 ) .. F = . ϕ1 (xn) y el vector de datos: ... ϕm (xn ) y1 Y = ... yn Por otra parte denotamos el vector de coeficientes, incógnitas: a1 .. a= . am El vector de error se expresa como (F a − Y ) el error cuadrático es su norma euclı́dea: E = (F a − Y )t (F a − Y ) Es una función escalar de a. Puede probarse que el error es mı́nimo si se verifica la relación de ortogonalidad: F t(F a − Y ) = 0 es decir: F t F a = F tY son las ecuaciones normales a resolver. Suponiendo que el sistema normal es compatible determinado: a = (F t F )−1F tY La matriz (F tF )−1F t se denomina la pseudo-inversa de F