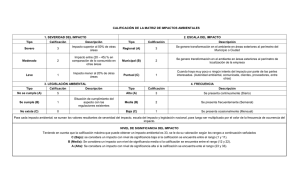
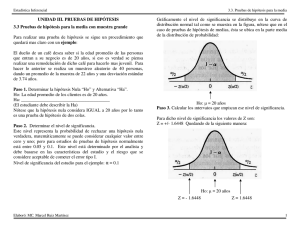
UNIVERSIDAD NACIONAL MAYOR DE SAN MARCOS (Universidad del Perú, Decana De América) CURSO : ESTADÍSTICA INDUSTRIAL TEMA : TRABAJO DE ESTADÍSTICA INDUSTRIAL PROFESOR ALUMNOS : : INGENIERO PEREZ Poma Rosales Jhon Efrain Lara Carhuancho Mireya Gabriela Ramos Poma Lisbeth Urtecho Ponte Rudy Ciudad Universitaria, 09 Julio deL 2016 01 ÍNDICE 1 PRUEBA RELATIVA A la media ......................................................................................................... 3 2 PRUEBA RELATIVA A PROPORCIONES ............................................................................................... 6 3 HIPOTESIS T................................................................................................................................11 4 ANOVA DE UNO Y DOS FACTORES ......................................................................................25 5 MODELO DE REGRESIÓN LINEAL SIMPLE ........................................................................................36 6 MODELO DE REGRESION MULTIPLE ....................................... ¡Error! Marcador no definido. 7 MODELO DE REGRESION CURVILINEO .................................................................................56 8 MÉTODOS NO PARAMÉTRICOS.............................................. ¡Error! Marcador no definido. 02 TRABAJO DE ESTADÍSTICA INDUSTRIAL 1 .- PRUEBA RELATIVA A LA MEDIA Ejercicio: American Theaters sabe que cierta película de éxito se exhibió un promedio de 84 días en cada ciudad y que la desviación estándar correspondiente fue 10 días. El administrador del distrito sureste se interesó en comparar la popularidad de la película en su región con la que tuvo en otros cines de Estados Unidos. Eligió 75 salas al azar en su región y encontró que exhibieron la película un promedio de 81.5 días. a) Establezca las hipótesis adecuadas para probar si hubo una diferencia significativa en la duración de la exhibición entre los teatros del sureste y el resto de Estados Unidos. b) Pruebe estas hipótesis para un nivel de significancia del 1%. ANALISIS ESTADÍSTICO: PASO 1.- DEFINICION DE HIPOTESIS: Ho: U= 84 La media es igual a 84. Ha: U ≠ 84 .la media no es igual a 84 PASO 2: Nivel de significancia α=0.01 PASO 3.- CALCULO DEL ESTADISTICO DE LA PRUEBA: Podemos aproximar los datos a una distribución normal para esta prueba: Tenemos: 03 X=81.5, U=84, σ=10, n=75 𝒁𝒄 = 𝒁𝒄 = 𝑿−𝑼 𝝈 √𝒏 𝟖𝟏. 𝟓 − 𝟖𝟒 𝟏𝟎 √𝟕𝟓 𝒁𝒄 = −𝟐. 𝟏𝟕 En Minitab: 04 Interpretación: Como el valor de p (0.030) es mayor que el valor de alfa (0.01) no se rechaza Ho. Por lo que podemos afirmar a un nivel de significancia de 1% que la media 84,00. Por lo tanto, la duración de la exhibición no es significativamente diferente de las otras regiones. 1.2 Para dos muestras independientes Fry Brothers Heating and Air Conditioning, Inc., emplea a Larry Clark y George Murnen para ofrecer por teléfono servicios de reparación de chimeneas y unidades de aire acondicionado en casas. Al propietario, Tom Fry, le gustaría saber si hay alguna diferencia entre los números medios de llamadas diarias. Suponga que la desviación estándar de la población de Larry Clark es 1.05 llamadas por día, y de 1.23 la de George Murnen. Una muestra aleatoria de 40 días que se realizó el año pasado reveló que Larry Clark hace un promedio de 4.77 llamadas por día. una muestra de 50 días, George Murnen realizó un promedio de 5.02 llamadas por día. Con un nivel de significancia de 0.05, ¿hay alguna diferencia entre los números medios de llamadas por día de los dos empleados? ¿Cuál es el valor p? SOLUCION: Paso 1: Establecer la hipótesis nula y alternativa: H0: µ1 = µ2 H1: µ1 ≠ µ2 Paso 2: Nivel de significancia α=0.05 Paso 3: Se toma la estadística de prueba z ∶ Paso 4: Rechace H0 si Z < -1.96 o Z> 1.96 05 Paso 5: Se toma una decisión y se interpreta el resultado. Como el valor de p es mayor a 0,05 entonces no se rechaza la hipótesis nula. Es decir no hay diferencia entre los números medios de llamadas por día de los dos empleados a un nivel de significancia del 0,05. 2 PRUEBA RELATIVA A PROPORCIONES 2.1 Prueba de proporciones de una muestra. Ejercicio: En la década de los noventa, el índice de mortalidad por cáncer de pulmón era de 80 por cada 100 000 personas. A la vuelta del siglo y el establecimiento de nuevos tratamientos y ajustes en la publicidad de salud pública, una muestra aleatoria de 10 000 personas exhibe sólo seis muertes debidas al cáncer de pulmón. A un nivel de 0.05, pruebe si los datos comprueban una reducción del índice de mortalidad de ese tipo de cáncer. SOLUCION: H0: 𝜋 = 0.0008 H1: 𝜋 < 0.0008 06 Se rechaza H0 si Z < -1.645. Conclusion: Como el valor de p(0,240) es mayor a alfa entonces no se rechaza la hipotesis nula. Es decir la mortalidad sige siendo de 0,0008 a un nivel de significancia de 0,05 Ejercicio: En la empresa EDITORA Y COMERCIALIZADORA CARTOLAN EIRL, se hacen trabajos de artes graficas, en el cual el papel o carton pasan por diferestes procesos para obtener un producto terminado como una caja, una revista, etc. Para alcanzar el tiraje deseado la empresa debe estimar cual sera la proporción de fallidos en todo el proceso, esta proporción es variante en ciertos casos debido al tipo de impresión y acabados que se les da. La empresa realiza mayoritariamente un tipo de trabajo, el cual es hacer cajas para farmaceuticos, para el cual manejan una proporción de fallidos esperada del 20%. En este trabajo probaremos que la proporción es menor de la que usan. Este analisis nos permitiría lograr realizar un ahorro en tiempo y costos de producción. Tomamos una muestra de las ultimas 30 ordenes de producción que cumplan con un tiraje de 5000 y que sean un trabajo de cajas para farmaceurico, y anotamos la cantidad de pliegos errados al final del proceso. DATOS RECOPILADOS: Se muestra una tabla con la cantidad de malogrados por orden de producción revisada. OP: ORDEN De PRODUCCIÓN 07 OP 47899 47899 48564 48843 48816 48744 48768 48469 48770 48941 48939 49144 49145 49155 49264 MALOGRADOS 650 750 755 750 800 775 840 650 615 800 650 750 700 850 725 OP MALOGRADOS 49149 625 49151 800 49049 900 49046 850 49090 750 48771 750 49144 750 49145 700 49155 850 49264 725 49195 900 49151 800 49357 750 49333 713 49430 835 MEDIA DE MALOGRADOS PROPORCION MEDIA DE LA MUESTRA HIPOTETICA 759 0.1518 0.2 PROPORCION Con los datos que tenemos procederemos a realizar los pasos que se siguen a través del análisis estadístico. ANALISIS ESTADÍSTICO: PASO 1.- PLANTEAMIENTO DE HIPOTESIS: Ho: P1= 0.2 La proporción de cajas malogradas es del 20%. Ha: P1<0.2 La proporción de cajas malogradas es menor del 20% Alfa=0.05 PASO 2.- EL VALOR ESTADISTICO: Podemos aproximar los datos a una distribución normal para esta prueba: Tenemos: N=5000, X=759, p1=0.1518, po=0.2 𝒁𝒄 = 𝒁𝒄 = 𝒑𝟏 − 𝒑𝒐 𝝈𝒑 𝟎. 𝟏𝟓𝟏𝟖 − 𝟎. 𝟐 𝟎. 𝟎𝟎𝟓𝟕 08 𝒁𝒄 = −𝟖. 𝟓𝟐 El valor de p para Zc =-8.52 será: p= 0.000 PASO 3.- CONCLUSIONES: Como el valor de p (0.00) es menor que el valor de alfa (0.05) se rechaza Ho. Por lo que podemos afirmar a un nivel de significancia de 5% que la proporción de cajas malogradas es menor del 20%. Por lo tanto, la empresa podría ajustar más la proporción de malogrados actual que manejan, y así obtener ahorros en cantidades de material y también en tiempos, ya que el exceso de trabajos terminados (cajas de laboratorios farmacéuticos) genera pérdidas. 2.2 Prueba de proporciones de dos muestras Ejercicio: Suponga que el fabricante de Advil, analgésico común para el dolor de cabeza, hace poco desarrolló una fórmula nueva del medicamento que afirma ser más eficaz. Para evaluar el nuevo medicamento, se pidió que lo probara una muestra de 200 usuarios. Después de una prueba de un mes, 180 indicaron que el medicamento nuevo era más eficaz. Al mismo tiempo, a una muestra de 300 usuarios de Advil se les da el medicamento actual, pero se les dice que tiene la fórmula nueva. De este grupo, 261 dijo que había mejorado. Con un nivel de significancia de 0.05, ¿se puede concluir que el medicamento nuevo es más eficaz? 09 SOLUCION: Paso 1: Establecer la hipótesis nula y alternativa: H0: 𝜋1 = 𝜋2 H1: 𝜋1 > 𝜋2 Paso 2: Nivel de significancia α=0.05 Paso 3: 180 + 261 𝑃𝑐 = = 0.882 200 + 300 Se toma la estadística de prueba Z ya que se utiliza proporciones ∶ Paso 4: Conclusión Como el valor de p es mayor entonces no se rechaza la hipótesis nula. No es posible concluir que es mayor la proporción de hombres que considera que la división es justa a un nivel de significancia del 0,05. 10 3 HIPOTESIS T 3.1 Para una muestra con desviación poblacional desconocida Ejercicio: El ingreso promedio por persona en Estados Unidos es de $40 000, y la distribución de ingresos sigue una distribución normal. Una muestra aleatoria de 10 residentes de Wilmington, Delaware, presentó una media de $50 000, con una desviación estándar de $10 000. A un nivel de significancia de 0.05, ¿existe suficiente evidencia para concluir que los residentes de Wilmington, Delaware, ganan más que el promedio nacional? SOLUCION: Paso 1: Establecer la hipótesis nula y alternativa: H0: µ = 40000 H1: µ > 40000 Paso 2: Nivel de significancia α=0.05 Paso 3: Se toma la estadística de prueba t ya que se desconoce σp ∶ Paso 4: t crítico con ayuda de la tabla con grado de libertad 10-1=9 y al 95% es 1.833 tomarlo positivo al ser un distribución normal estándar y sesgada a la derecha. La regla de decisión será: “Si el t calculado es >1.833, se rechaza la H0 “. 11 Paso 5: Se toma una decisión y se interpreta el resultado. Como podemos observar la t calculada es 3.16 que es mayor que 1.833 por lo tanto se rechaza la H0. INTERPRETACION: Los residentes de Wilmington, Delaware, pueden aseverar con las evidencias que tienen que ganan más que el promedio que otro estadounidense a nivel nacional. 3.2 T-student – (1poblacion) Ejercicio: En la empresa “Los conejillos de la Fii”, el analista de las ganancias afirma que las ganancias mensuales netas de la empresa posee una media de S/500 000. Sin embargo, un productor de la empresa le da las ganancias netas de los meses de marzo a setiembre de este año. (S/480 000, S/4900 000, S/510 000, S/554 000, S/500 000, S/486 000, S/497 000). Se desea saber si lo dicho por el analista de ganancias es correcto. 1. 1ra Forma (Estadístico) 2. Ho: µ=S/500000.00 Ha: µ≠S/500000.00 3. α=0.05 , g.l =6 4. T-student En el minitab: 12 Datos: t= x= S/502428.60 𝑥− µ s = 0.259 √𝑛 s= S/24764.60 µ=S/500000.00 n=7 Rpta : Tk € R.A , Entonces acepto la Ho y rechazo la Ha. 2. 2ra Forma (Con las medias) X= S/502428.60 - a= µ tx - 𝑠 √𝑛 b= µ tx 𝑠 √𝑛 24764.60 = 500000-0.259x √7 =497575.724 24764.60 = 500000+0.259x √7 ¿ a≤x≤b ? = ¿ 497575.724≤ 502428.60 13 =502430.276 ≤502430.276 ?, Si Rpta : Tk € R.A , Entonces acepto la Ho y rechazo la Ha. 3. 3ra Forma (P) tk=0.259 P/2= ¿0. 499<0.05 ? , No Rpta : Tk € R.A , Entonces acepto la Ho y rechazo la Ha. Interpretación: Se puede afirmar con seguridad de que la media de las ganancias mensuales es S/500000, ósea el analista de ganancias tenía la razón. Ejercicio: La longitud media de una barra de equilibrio es 43 milimetros.El supervisor de producción sospecha que la máquina que produce las barras se ha desajustado, y le pide al departamento de ingeniería que investigue. El departamento de ingeniería toma una muestra aleatoria de 12 barras y mide cada una. Los resultados de las mediciones son: 42,39,42,45,43,40,39,41,40,42,45,42. ¿Es razonable concluir que la longitud media ha cambiado? Nivel de significancia 0.02 1ra Forma (Estadístico): 1)Ho: µ=43 Ha: µ≠43 2) α=0.02 , g.l =11 3) T-student En el minitab: 14 Datos: t= x= 41.5 mm 𝑥− µ s = -2.92 √𝑛 s= 1.78 µ=43 n=12 Rpta : Tk € R.A , Entonces se rechaza la Ho y acepto la Ha. 2. 2da Forma (Medias): X= 41.5 - a= µ tx - 𝑠 √𝑛 b= µ tx 𝑠 √𝑛 1.78 = 43-2.92x √12 =41.5 1.78 = 43+2.92x √12 =44.5 15 ¿ a≤x≤b ? = ¿ 41.5< 41.5 <44.5 ?, No Rpta : Tk € R.A , Entonces rechazo la Ho y acepto la Ha. 3. 3ra Forma (P): tk=2.92 P/2= ¿0. 01<0.05 ? , Si Rpta : Tk € R.A , Entonces rechazo la Ho y acepto la Ha. Interpretación: Se puede afirmar con seguridad de que la longitud media de las barras de acero ha cambiado. 3.3 Tstudent – (2poblaciones) Ejercicio: Lisa Monnin es la directora de presupuestos de Nexos Media, Inc. Ella quiere comparar los gastos diarios en viáticos del personal de ventas con los gastos del personal de auditoría, para lo cual recopiló la información siguiente sobre las muestras. Con un nivel de significancia de 0.10, ¿puede Monnin concluir que los gastos diarios medios son diferentes para el personal de venta que para el personal de auditoría? Solución: Método de método del valor crítico. 1) Definir hipótesis Ho: µ1= µ2 Ha: µ1≠µ2 2) Nivel de significancia α = 0.10 16 3) Definir el estadístico T – Student En el minitab: 4) Definir R.A. y R.C g.l.= n1+n2-2 =6+7-2=11 t(0.05,11)=1.796 17 5) Calcular Ventas 131 (131-142.6)2=134.56 135 146 165 136 142 (135-142.6)2=57.76 (146-142.6)2=11.56 (165-142.6)2=501.76 (136-142.6)2=43.56 (142-142.6)2=0.36 Suma: 855 749.56 Auditoria 130 (130-130.29)2=0.0841 102 129 143 149 120 139 (102-130.29)2=800.32 (129-130.29)2=1.66 (143-130.29)2=161.54 (149-130.29)2=350.06 (120-130.29)2=105.88 (139-130.29)2=75.86 Suma: 912 Para ventas: 855 = 142.6 6 𝑥= σ=√ 749.56 = 12.24 5 Para auditoria: 𝑥= 912 = 130.29 7 1495.40 σ=√ = 15.79 6 𝑆𝑝2 = (6 − 1)12.242 + (7 − 1)15.792 = 204.09 6+7−2 𝑡= 142.6 − 130.29 √204.09 ∗ (1 + 1) 6 7 18 = 1.55 1495.40 tk € a R.A. ⇒ Acepto la Ho y rechazo la Ha . Método del valo r de P: P/2 = 0.07471 ⇒ P= 0.14942 P<α 0.14942> 0.10 . ⇒ Acepto la Ho y rechazo la Ha Interpretación: Se puede decir que los gastos medios diarios de ventas y auditoria son diferentes con un nivel de significancia de 0.10. Ejercicio: La muestra de calificaciones obtenidas en un examen de estadística 201 es: Con un nivel de significancia de 0.01, ¿es mayor la calificación media de las mujeres que la de los hombres? Solución: Método de método del valor crítico. 19 1) Definir hipótesis Ho: µ1≥ µ2 Ha: µ1<µ2 2) Nivel de significancia α = 0.01 3) Definir el estadístico T – Student En el minitab : 4) Definir R.A. y R.C g.l.= n1+n2-2 =9+7-2=14 t(0.01,14)= 2.624 20 5) Calcular: Hombres Mujeres 72 (72-78)2=36 81 (81-79)2=4 69 (69-78)2=81 67 (67-79)2=144 98 (98-78)2=400 90 (90-79)2=121 66 (66-78)2=144 78 (78-79)2=1 85 (85-78)2=49 81 (81-79)2=4 76 (76-78)2=4 80 (80-79)2=1 79 (79-78)2=1 76 (76-79)2=9 80 (80-78)2=4 77 (77-78)2=1 Suma: 702 720 Suma: 553 Para Hombres: 𝑥= 702 = 78 9 720 σ=√ = 9.49 8 Para Mujeres: 𝑥= 553 = 79 7 284 σ=√ = 6.88 6 𝑆𝑝2 = (9 − 1)9.492 + (7 − 1)6.882 = 71.75 9+7−2 21 284 𝑡= 78 − 79 √71.75 ∗ (1 + 1) 9 7 = −0.23 tk € a R.A. ⇒ Acepto la Ho y rechazo la Ha Método del valor de P P= 0.5893 P<α 0.5893> 0.01 . ⇒ Acepto la Ho y rechazo la Ha Interpretación: Podemos decir que la clasificación promedio de las mujeres es menor que las de los hombres, con un nivel de significancia de 0.01. 3.4 Comparación de medias poblacionales con desviaciones estándares desconocidas 3.4.1) Desviaciones estándares poblacionales iguales Ejercicio: El fabricante de un reproductor MP3 desea saber si una reducción de 10% de precio es suficiente para aumentar las ventas de su producto. Para saberlo con certeza, el propietario selecciona al azar ocho tiendas y vende el reproductor MP3 al precio reducido. En siete tiendas seleccionadas al azar, el aparato se vendió al precio normal. A continuación se presenta el número de unidades que se vendieron el mes pasado en las tiendas muestreadas. Con un nivel de 22 significancia de 0.01, ¿puede concluir el fabricante que la reducción de precio generó un aumento de ventas? SOLUCION: Paso 1: Establecer la hipótesis nula y alternativa: H0: µ1 = µ2 H1: µ1 ≠ µ2 Nivel de significancia: 0.001 EN MINITAB: Conclusión: Como el valor de p es menor a 0,05 entonces no se rechaza H0. No hay diferencia entre el número medio vendido al precio regular y el número medio vendido al precio reducido a un nivel de significancia del 0,05. 23 3.4.2 Para dos muestras dependientes (pareadas). Ejercicio: La gerencia de Discount Furniture, cadena de mueblerías de descuento del noreste de Estados Unidos, diseñó un plan de incentivos para sus agentes de ventas. Para evaluar este plan innovador, se seleccionaron a 12 vendedores al azar, y se registraron sus ingresos anteriores y posteriores al plan. ¿Hubo algún aumento significativo en el ingreso semanal de un vendedor debido al innovador plan de incentivos? Utilice el nivel de significancia 0.05. Calcule el valor p e interprételo. SOLUCION: Paso 1: Establecer la hipótesis nula y alternativa: H0: µd = 0 H1: µd > 0 𝑑̅= 25.917 𝑆𝑑 = 40791 Se rechaza la H0 si t > 1.796 24 Conclusión: Como en valor de p es igual a alfa entonces no se rechaza la H0. El plan de incentivos no resulto en un aumento del ingreso diario a un nivel de significancia del 0,05. 4 .- ANOVA DE UNO Y DOS FACTORES 4.1 ANOVA DE UN FACTOR Ejercicio: Una empresa produce variedad de productos alimenticios con variados niveles de proteínas y perfiles nutricionales personalizados, busca mejorar la calidad. Para hacer un control de calidad se mide la estabilidad en el agua, ya que si se desintegra fácilmente entonces no se logra ingerir los nutrientes. En el laboratorio se desarrolló 4 formulas y luego se determinó el tiempo de estabilidad en el agua Datos recopilados: 25 Fuente: tesis (diseño de un modelo de gestión estratégico para el mejoramiento de la productividad y calidad aplicado a una planta procesadora de alimentos balanceados. Guayaquil- Ecuador. 2012) ANALISIS ESTADÍSTICO: Filtros Para emplear anova de debe garantizar los siguiente supuestos a. Las poblaciones sigue una distribución normal b. Las poblaciones tienen desviaciones estándar iguales c. Las poblaciones son independientes PASO1: FORMULACIÓN DE HIPOTESIS Ho: El tiempo de estabilidad en el agua de los diferentes tipos de fórmulas son iguales La tiempo de estabilidad en el agua no depende del tipo de formula Ha: Al menos el tiempo de estabilidad en el agua de un tipo de fórmula es diferente El tiempo de estabilidad en el agua no depende del tipo de formula PASO2: EL VALOR CRITICO Nivel de significancia =0.05 GL numerador = k-1=4-1=3 GL del denominador =n-k=16-4=12 Fcritico = 3.490 Regla de decisión: Se rechazara la Ho si F>3.10 26 PASO3: EL VALOR ESTADÍSTICO CONCLUSIONES: Como el valor F calculado 4,76594229 es mayor que el valor Fcritico de 3.490 entonces se rechaza la Ho, y se concluye que al menos el tiempo de estabilidad en el agua de un tipo de fórmula es diferente. Ejercicio: La siguiente información es muestral. Pruebe la hipótesis de que las medias de tratamiento son iguales. Utilice el nivel de significancia 0.05. Tratamiento 1 9 7 11 9 12 10 a) b) c) d) e) Tratamiento 2 13 20 14 13 Tratamiento 3 10 9 15 14 15 Establezca las hipótesis nula y alternativa. ¿Cuál es la regla de decisión? Calcule SST, SSE y SS total. Elabore una tabla ANOVA. Exprese su decisión acerca de la hipótesis nula. Se seguirá el procedimiento usual de cinco pasos para la prueba de hipótesis. 27 Paso 1: Plantear la hipótesis nula y la hipótesis alternativa 𝐻0 : µ1 = µ2 = µ3 𝐻1 : 𝐿𝑜𝑠 𝑡𝑟𝑎𝑡𝑎𝑚𝑖𝑒𝑛𝑡𝑜𝑠 𝑛𝑜 𝑠𝑜𝑛 𝑡𝑜𝑑𝑜𝑠 𝑖𝑔𝑢𝑎𝑙𝑒𝑠. Paso2: Establecer nivel de significancia. α = 0.05 Paso 3: Determinar el estadístico de prueba. Estamos ante una distribución F, ANOVA. Paso 4: Establecer la regla de decisión. Grados de libertad para el numerador = k – 1 = 3 – 1 = 2 Grados de libertad para el numerador = n - k = 15 – 3 = 12 Intersectando en la tabla, encontramos el valor de 3.89. Así que la regla de decisión es rechazar la 𝐻0 si el valor calculado para F es mayor que 3.89. Paso 5: Seleccionar muestra, realizar los cálculos y tomar una decisión. Tratamient o1 𝑋 𝑋2 9 81 7 49 11 121 9 81 12 144 10 100 𝑇𝑐 𝑛𝑐 𝑋2 Tratamient o2 𝑋 𝑋2 13 169 20 400 14 196 13 169 58 6 Tratamiento 3 𝑋 𝑋2 10 100 9 81 15 225 14 196 15 225 60 4 63 5 576 934 827 Total 181 15 2337 Las entradas para la tabla ANOVA se calculan como sigue. SS total = ∑ 𝑋 2 − 𝑇2 SST = ∑ ( 𝑛𝑐 ) − 𝑐 (∑ 𝑋)2 𝑛 (∑ 𝑋)2 𝑛 = = 2337 − 582 6 + 602 4 + 1812 15 632 5 = 𝟏𝟓𝟐. 𝟗𝟑𝟑 − 1812 15 = 𝟕𝟎. 𝟒 SSE = SS total – SST = 152.933 – 70.4 = 82.533 Al insertar estos valores en una tabla ANOVA y calcular el valor de F se tiene: 28 Tabla ANOVA Fuente de variación Tratamientos Error Total Suma de cuadrados SST = 70.4 SSE = 82.533 SStotal = 152.933 Grados de libertad k-1 = 3-1=2 n-k=153=12 n-1=14 Cuadrado medio SST/(k1)=35.2 SSE/(nk)=6.878 F MST/MSE=5.12 El valor calculado para F es 5.12, que es mayor que el valor crítico 3.89, por tanto se rechaza la hipótesis nula. Se concluye que las medias poblacionales no son iguales. Los tratamientos promedio no son iguales en los tres grupos de evaluación. Por ahora sólo se puede concluir que hay una diferencia entre las medias de tratamiento. ANOVA unidireccional: tratamiento1; tratamiento2; tratamiento3 Método Hipótesis nula Hipótesis alterna Nivel de significancia Todas las medias son iguales Por lo menos una media es diferente α = 0.05 Se presupuso igualdad de varianzas para el análisis. Información del factor Factor Factor Niveles 3 Valores tratamiento1; tratamiento2; tratamiento3 Análisis de Varianza Fuente Factor Error Total GL 2 12 14 SC Ajust. 70.40 82.53 152.93 MC Ajust. 35.200 6.878 Valor F 5.12 Valor p 0.025 Resumen del modelo S 2.62255 R-cuad. 46.03% R-cuad. (ajustado) 37.04% R-cuad. (pred) 12.12% Medias Factor tratamiento1 tratamiento2 tratamiento3 N 6 4 5 Media 9.667 15.00 12.60 Desv.Est. 1.751 3.37 2.88 IC de 95% (7.334; 11.999) (12.14; 17.86) (10.04; 15.16) Desv.Est. agrupada = 2.62255 29 Gráfica de intervalos de tratamiento1; tratamiento2; ... 95% IC para la media 18 16 Datos 14 12 10 8 6 tratamiento1 tratamiento2 tratamiento3 La desviación estándar agrupada se utilizó para calcular los intervalos. Ejercicio: Una compañía de desarrollos inmobiliarios considera la inversión en un centro comercial en las afueras de Atlanta, Georgia. Se evalúan tres terrenos. El ingreso de los pobladores de la zona aledaña al centro comercial es de especial importancia. Se selecciona una muestra aleatoria de cuatro familias que viven cerca de cada terreno. A continuación se presentan los resultados muestrales. Al nivel de significancia de 0.05, ¿ puede concluir la compañía que hay diferencia en los ingresos promedio? Utilice el procedimiento usual de cinco pasos para prueba de hipótesis. Southwyck (miles US$) 64 68 70 60 Parque Franklin (miles US$) 74 71 69 70 Old Orchard (miles US$) 75 80 76 78 Se seguirá el procedimiento usual de cinco pasos para la prueba de hipótesis. Paso 1: Plantear la hipótesis nula y la hipótesis alternativa 𝐻0 : µ1 = µ2 = µ3 𝐻1 : 𝐿𝑜𝑠 𝑖𝑛𝑔𝑟𝑒𝑠𝑜𝑠 𝑝𝑟𝑜𝑚𝑒𝑑𝑖𝑜 𝑛𝑜 𝑠𝑜𝑛 𝑡𝑜𝑑𝑜𝑠 𝑖𝑔𝑢𝑎𝑙𝑒𝑠. 30 Paso 2: Establecer nivel de significancia. α = 0.05 Paso 3: Determinar el estadístico de prueba. Estamos ante una distribución F, ANOVA. Paso 4: Establecer la regla de decisión. Grados de libertad para el numerador = k – 1 = 3 – 1 = 2 Grados de libertad para el numerador = n - k = 12 – 3 = 9 Intersectando en la tabla, encontramos el valor de 4.26. Así que la regla de decisión es rechazar la 𝐻0 si el valor calculado para F es mayor que 4.26. Paso 5: Seleccionar muestra, realizar los cálculos y tomar una decisión. Southwyck (miles US$) 𝑋2 4096 4624 4900 3600 𝑋 64 68 70 60 𝑇𝑐 𝑛𝑐 𝑋2 262 4 Parque Franklin (miles US$) 𝑋 𝑋2 74 5476 71 5041 69 4761 70 4900 Old Orchard (miles US$) 𝑋 𝑋2 75 5625 80 6400 76 5776 78 6084 Total 284 4 309 4 855 12 61283 1722 0 2017 8 2388 5 Las entradas para la tabla ANOVA se calculan como sigue. SS total = ∑ 𝑋 2 − 𝑇2 SST = ∑ ( 𝑛𝑐 ) − 𝑐 (∑ 𝑋)2 𝑛 (∑ 𝑋)2 𝑛 = = 61283 − 2622 4 + 2842 4 8552 12 + = 𝟑𝟔𝟒. 𝟐𝟓 3092 4 − 8552 12 = 𝟐𝟕𝟔. 𝟓 SSE = SS total – SST = 364.25 – 276.5 = 87.75 Al insertar estos valores en una tabla ANOVA y calcular el valor de F se tiene: 31 Tabla ANOVA Fuente de variación Tratamientos Error Total Suma de cuadrados SST = 276.5 SSE = 87.75 SStotal = 364.25 Grados de libertad k-1 = 3-1=2 n-k=12-3=9 n-1=121=11 Cuadrado medio SST/(k1)=138.25 SSE/(nk)=9.75 F MST/MSE=14.18 El valor calculado para F es 14.18, que es mayor que el valor crítico 4.26, por tanto se rechaza la hipótesis nula. Se concluye que las medias poblacionales no son iguales. Los ingresos promedio no son iguales en los tres grupos de evaluación. Por ahora sólo se puede concluir que hay una diferencia entre las medias de tratamiento. ANOVA unidireccional: tratamiento1; tratamiento2; tratamiento3 Método Hipótesis nula Hipótesis alterna Nivel de significancia Todas las medias son iguales Por lo menos una media es diferente α = 0.05 Se presupuso igualdad de varianzas para el análisis. Información del factor Factor Factor Niveles 3 Valores tratamiento1; tratamiento2; tratamiento3 Análisis de Varianza Fuente Factor Error Total GL 2 12 14 SC Ajust. 70.40 82.53 152.93 MC Ajust. 35.200 6.878 Valor F 4.26 Valor p 0.025 Resumen del modelo S 2.62255 R-cuad. 46.03% R-cuad. (ajustado) 37.04% R-cuad. (pred) 12.12% Medias Factor tratamiento1 tratamiento2 tratamiento3 N 6 4 5 Media 9.667 15.00 12.60 Desv.Est. 1.751 3.37 2.88 IC de 95% (7.334; 11.999) (12.14; 17.86) (10.04; 15.16) Desv.Est. agrupada = 2.62255 32 ANOVA unidireccional: SouthWyck; Parque Flanklin; Old Orchard Método Hipótesis nula Hipótesis alterna Nivel de significancia Todas las medias son iguales Por lo menos una media es diferente α = 0.05 Se presupuso igualdad de varianzas para el análisis. Información del factor Factor Factor Niveles 3 Valores SouthWyck; Parque Flanklin; Old Orchard Análisis de Varianza Fuente Factor Error Total GL 2 9 11 SC Ajust. 276.50 87.75 364.25 MC Ajust. 138.250 9.750 Valor F 14.18 Valor p 0.002 Resumen del modelo S 3.12250 R-cuad. 75.91% R-cuad. (ajustado) 70.56% R-cuad. (pred) 57.17% Medias Factor SouthWyck Parque Flanklin Old Orchard N 4 4 4 Media 65.50 71.00 77.25 Desv.Est. 4.43 2.16 2.22 IC de 95% (61.97; 69.03) (67.47; 74.53) (73.72; 80.78) Desv.Est. agrupada = 3.12250 33 Gráfica de intervalos de SouthWyck; Parque Flank; ... 95% IC para la media 80 Datos 75 70 65 60 SouthWyck Parque Flanklin Old Orchard La desviación estándar agrupada se utilizó para calcular los intervalos. 4.2 Anova de dos factores Ejercicio: En los últimos años el consumo de maíz se ha incrementado incluso más que su producción. Por tanto se busca encontrar el mejor tipo de abono y como varía según el tipo de suelo que ayude a mejorar el rendimiento neto de maíz, cubriendo así su demanda y favoreciendo el desarrollo de los países que lo producen. Datos obtenidos 34 Fuente: tesis (diseño estadístico experimental para el estudio de la respuesta del maíz a la aplicación edáfica complementaria de tres tipos de abono sintético a dos dosis en la comunidad de peñas, canton tiwintza, provincia de morona Santiago. Riobamba- Ecuador. 2012) ANALISIS ESTADÍSTICO PASO1: Formulación de las hipótesis 1) Respecto al primer tratamiento: Ha: el tipo de abono influye en el rendimiento neto del maíz Ho: el tipo de abono no influye en el rendimiento del maíz 2) Respecto al segundo tratamiento: Ha: El tipo de parcela influye en el rendimiento neto del maíz Ho: El tipo de parcela no influyen en el rendimiento neto del maíz PASO2: CRITERIO DE CONTRASTTE A 9 b 4 n 36 glT1 glT2 glTotal gl SCE a-1 b-1 n-1 8 3 35 24 glT1 gl SCE F 8 24 = 2.36 glT2 gl SCE F 3 24 = 3.01 35 PASO3: CALCULO DEL VALOR ESTADÍSTICO PASO4: CONCLUSIONES: 1) Respecto al primer tratamiento Como el valor F calculado 7,18319716 es mayor que el Fcritico 2,36 entonces se rechaza la Ho. Por lo que hay evidencia suficiente, con un nivel de significancia de 0.05, para afirmar que con respecto al tipo de abono existe diferencia en los rendimientos netos del maíz 2) Respecto al primer tratamiento Como el valor F calculado 3,9411112 es mayor que el Fcritico 3,01 entonces se rechaza la Ho. Por lo que hay evidencia suficiente, con un nivel de significancia de 0.05, para afirmar que con respecto a la parcela existe diferencia en los rendimientos netos del maíz. Ejercicio: Cada una de las tres cadenas de supermercados en la región de Denver indica que ofrece los precios más bajos. Como parte de un estudio de investigación sobre publicidad de supermercados, el diario Denver Daily News realizó un estudio. Primero selecciono una muestra aleatoria de nueve artículos comestibles. Después se revisó el precio de cada uno de estos productos en cada una de las tres cadenas, el mismo día. Al nivel de significancia 0.05, ¿hay alguna diferencia en los precios medios de los supermercados y de los artículos? Articulo 1 2 3 4 5 6 7 8 9 Ralph’s $ 1.02 1.10 1.97 2.09 2.10 4.32 4.95 4.13 5.46 Super$ $ 1.12 1.14 1.72 2.22 2.40 4.04 5.05 4.68 5.52 36 Lowblaws $ 1.07 1.21 2.08 2.32 2.30 4.15 5.05 4.67 5.86 Solución: Se seguirá el procedimiento usual de cinco pasos para la prueba de hipótesis. Paso 1: Plantear la hipótesis nula y la hipótesis alternativa Los dos conjuntos de hipótesis son: 1. 𝐻0 : µ1 = µ2 = µ3 𝐻1 : 𝑁𝑜 𝑡𝑜𝑑𝑎𝑠 𝑙𝑎𝑠 𝑚𝑒𝑑𝑖𝑎𝑠 𝑑𝑒 𝑡𝑟𝑎𝑡𝑎𝑚𝑖𝑒𝑛𝑡𝑜 𝑠𝑜𝑛 𝑖𝑔𝑢𝑎𝑙𝑒𝑠 2. 𝐻0 : µ1 = µ2 = µ3 𝐻1 : 𝑁𝑜 𝑡𝑜𝑑𝑎𝑠 𝑙𝑎𝑠 𝑚𝑒𝑑𝑖𝑎𝑠 𝑑𝑒 𝑏𝑙𝑜𝑞𝑢𝑒 𝑠𝑜𝑛 𝑖𝑔𝑢𝑎𝑙𝑒𝑠 Paso 2: Establecer nivel de significancia. α = 0.05 Paso 3: Determinar el estadístico de prueba. Estamos ante un ANOVA de dos direcciones. Paso 4: Establecer la regla de decisión. a) Primero se probara la hipótesis relativa a las medidas de tratamiento: Grados de libertad para el numerador = k – 1 = 3 – 1 = 2 Grados de libertad para el numerador = (b-1)*(k-1) = (3-1)*(9-1)= 16 Intersectando en la tabla, encontramos el valor de 3.63. Así que la regla de decisión es rechazar la 𝐻0 si el valor calculado para F es mayor que 3.63 (Fcrit>3.63). b) Luego se realizará la prueba de hipótesis a las medidas de bloques: Grados de libertad para el numerador = b – 1 = 9 – 1 = 8 Grados de libertad para el numerador = (b-1)*(k-1) = (3-1)*(9-1)= 16 Intersectando en la tabla, encontramos el valor de 2.59. Así que la regla de decisión es rechazar la 𝐻0 si el valor calculado para F es mayor que 2.59 (Fcrit>2.59) . 37 Paso 5: Seleccionar muestra, realizar los cálculos y tomar una decisión. Articulo 1 2 3 4 5 6 7 8 9 Total columna Suma de cuadrad os Super $ X $ 1.12 1.14 1.72 2.22 2.40 4.04 5.05 4.68 5.52 27.89 Ralph’ s X 𝑋2 1.2544 1.2996 2.9584 4.9284 5.76 16.3216 25.5025 21.9024 30.4704 110.397 7 $ 1.02 1.10 1.97 2.09 2.10 4.32 4.95 4.13 5.46 27.14 𝑋2 1.0404 1.21 3.8809 4.3681 4.41 18.6624 24.5025 17.0569 29.8116 Lowbla ws X $ 1.07 1.21 2.08 2.32 2.30 4.15 5.05 4.67 5.86 28.71 104.942 8 𝑋2 1.1449 1.4641 4.3264 5.3824 5.29 17.2225 25.5025 21.8089 34.3396 Suma reglone s Bt 3.21 3.45 5.77 6.63 6.8 12.51 15.05 13.48 16.84 83.74 116.481 331.821 3 8 (∑ 𝑋)2 𝑆𝑆𝑇𝑜𝑡𝑎𝑙 = ∑ 𝑋 − 𝑛 2 𝑆𝑆𝑇𝑜𝑡𝑎𝑙 = 331.8218 − 83.742 = 72.1037 27 ∑ 𝑋2 𝑇𝑐 2 𝑆𝑆𝑇 = ∑( ) − 𝑛𝑐 𝑛 27.892 27.142 28.712 83.742 𝑆𝑆𝑇 = + + − = 0.1370 9 9 9 27 𝑆𝑆𝐵 = ∑( ∑ 𝑋2 𝐵𝑡 2 )− 𝑘 𝑛 3.212 3.452 5.772 6.632 6.82 12.512 15.052 13.482 𝑆𝑆𝐵 = + + + + + + + 3 3 3 3 3 3 3 3 16.842 83.742 + − = 71.6136 3 27 38 𝑆𝑆𝐸 = 𝑆𝑆𝑇𝑜𝑡𝑎𝑙 − 𝑆𝑆𝑇 − 𝑆𝑆𝐵 𝑆𝑆𝐸 = 72.1037 − 0.1370 − 71.6136 = 0.3531 𝑀𝑆𝑇 = 𝑆𝑆𝑇/(𝑘 − 1) 𝑀𝑆𝑇 = 0.1370 = 0.0685 2 𝑀𝑆𝐵 = 𝑆𝑆𝐵/(𝑏 − 1) 71.6136 = 8.9517 8 𝑀𝑆𝐵 = 𝑀𝑆𝐸 = 𝑆𝑆𝐸/(𝑘 − 1)(𝑏 − 1) 𝑀𝑆𝐸 = Fuente de Suma variación Cuadrados Tratamientos 0.1370 Bloques 71.6136 Error 0.3531 Total 72.1037 0.3531 = 0.0221 16 de Grados Libertad 2 8 16 𝐹𝑐𝑟𝑖𝑡 = de Cuadrado medio 0.0685 8.9517 0.0221 𝑀𝑆𝑇 0.0685 = = 3.0995 𝑀𝑆𝐸 0.0221 No se rechaza la hipótesis nula de medias de tratamiento ya que del F hallado en menor que 3.63. Se concluye que los precios no difieren en todas las tiendas 𝐹𝑐𝑟𝑖𝑡 = 𝑀𝑆𝐵 8.9517 = = 405,0543 𝑀𝑆𝐸 0.0221 Se rechaza la hipótesis nula de medias de bloques ya que el F hallado es mayor que 2.59. Se concluye que hay diferencia entre los artículos observados. ANOVA bidireccional: Super$; Ralph s; Lowblaws 39 Método Hipótesis nula Hipótesis alterna Nivel de significancia Todas las medias son iguales Por lo menos una media es diferente α = 0.05 Se presupuso igualdad de varianzas para el análisis. Información del factor Factor Factor Niveles 3 Valores Super$; Ralph s; Lowblaws Análisis de Varianza Fuente Factor Error Total GL 2 8 16 SC Ajust. 0.1370 71.9667 72.1037 MC Ajust. 0.06851 2.99861 Valor F Valor p 3.0995 0.002 405.0543 Resumen del modelo S 1.73165 R-cuad. 0.19% R-cuad. (ajustado) 0.00% R-cuad. (pred) 0.00% Medias Factor Super$ Ralph s Lowblaws N 9 9 9 Media 3.099 3.016 3.190 Desv.Est. 1.731 1.699 1.764 IC de 95% (1.908; 4.290) (1.824; 4.207) (1.999; 4.381) 5 MODELO DE REGRESIÓN LINEAL SIMPLE Ejercicio: Una empresa comercial tiene establecimientos en varias zonas metropolitanas. La gerente general de ventas planea lanzar al aire un anuncio por televisión en algunas estaciones locales, al menos dos veces antes de realizar una venta gigante que ha de empezar el sábado y terminar el domingo. Planea traer las cifras de las ventas de videocámara del sábado y domingo en las diversas tiendas y agruparlas en pares con el número de veces que apareció el comercial en la televisión. El objetivo fundamental de la determinación es determinar si existe alguna relación entre el número de veces que se transmitió el anuncio y las ventas de cámara de video. Los pares de datos son: 40 Localización de la televisora Buffalo Albany Erler Syracuse Rochester Numero de anuncios transmitidos 4 2 5 6 3 Ventas en sábado y domingo (miles de dólares) 15 8 21 24 17 a) Hallar el coeficiente de correlación b) Hallar el coeficiente de determinación y no determinación c) Hallar la ecuación de regresión d) Hallar el error estándar de estimación e) Hallar el intervalo de predicción y de confianza para x= 5 y el intervalo de confianza al 95% f) Diagrama de dispersion 1 2 3 4 5 total x 4 2 5 6 3 20 𝑥2 y 15 8 21 24 17 85 16 4 25 36 9 90 𝑦2 225 64 441 576 289 1595 Xy 60 16 105 144 51 376 a) 𝛾= 𝛾= 𝑛 ∑ 𝑥𝑦 − ∑ 𝑥 ∑ 𝑦 √[𝑛 ∑ 𝑥 2 − (∑ 𝑥)2 ][𝑛 ∑ 𝑦 2 − (∑ 𝑦)2 ] 5(376) − (20)(85) √[5(90) − (400)][5(1595) − (7225) 𝛾 = 0.9295 Existe una correlacion positiva entre el numero de anuncios y las ganancias de 0.9295 b) 𝛾 2 = 0.8639 …. Coef. De determinacion La variacion total en y que puede ser expulsado para la variacion de x es 0.8639 1 − 𝛾 2 = 0.1361 … Coef. De no determinacion 41 c) Por la técnica de los mínimos cuadrados: 𝑏= 𝑏= 𝑛 ∑ 𝑥𝑦−∑ 𝑥 ∑ 𝑦 𝑛 ∑ 𝑥 2 −(∑ 𝑥) 5(376)−(20)(85) 5(90)−400 𝑎= 𝑎= 2 =3.6 ∑𝑦 −𝑏∑𝑥 𝑛 85 − 3.6(20) = 2.6 5 Entonces la ecuación de regresión será : 𝑦 = 2.6𝑥 + 3.6 Por cada anuncio que se haga, la venta se incrementara en 3.6 d) 𝑆𝑦𝑥 = √ ∑ 𝑦 2 −𝑎 ∑ 𝑦−𝑏 ∑ 𝑥 𝑛−2 1595 − 2.6(85) − 3.6(20) 𝑆𝑦𝑥 = √ = 20.83 3 e) Intervalo de confianza para x=5 1 𝐼. 𝐶 = [𝑦 ± 𝑡(𝛼,𝑛−2) 𝑆𝑦𝑥√ + 𝑛 (𝑋 − 𝑥)2 (∑ 𝑥)2 ∑ 𝑥2 − 𝑛 Y=2.6(5)+3.6=16.6 1 (5 − 4)2 𝐼. 𝐶 = [16.6 ± 3.182(20.83)√ + 5 90 − 400 5 𝐼. 𝐶 = [16.6 ± 34.43] = [−17.83,51.03] Intervalo de prediccion para x=5 1 𝐼. 𝐶 = [𝑦 ± 𝑡(𝛼,𝑛−2) 𝑆𝑦𝑥√ + 𝑛 42 (𝑋 − 𝑥)2 +1 (∑ 𝑥)2 ∑ 𝑥2 − 𝑛 1 (5 − 4)2 𝐼. 𝐶 = [16.6 ± 3.182(20.83)√ + +1 5 90 − 400 5 𝐼. 𝐶 = [−59.57,91.57] f) 6 MODELO DE REGRESIÓN LINEAL MULTIPLE Ejercicio: Una familia desea estimar los gastos en alimentación (Y) en base a la información que proporcionan las variables regresoras x1=” ingresos mensuales” y x2=” número de miembros de la familia”. Para ellos se recoge una muestra aleatoria simple de 20 familias cuyos resultados son los de la tabla adjunta. (El gasto e ingreso esta dado en cientos de miles de pesetas). 43 44 El modelo esta expresado como: GASTO = -17.067 + 1.40333 INGRESO + 8.93792 TAMAÑO Observamos que los valores calculados de los coeficientes de la regresión son de 𝑏0 = −17.067 𝑏1 = 1.403333 𝑏2 = 8.93792 Podemos interpretar que al aumento o decremento de una unidad de ingreso abra un incremento o decremento de 1.40333 en el gasto lo mismo para el tamaño. COEFICIENTE DE DETERMINACION MULTIPLE Este coeficiente representa la porción de la variación en Y que se puede explicar mediante el conjunto de variables elegidas. En el ejemplo seria: 𝑟2 = 𝑆𝑆𝑅 𝑆𝑆𝑇 De MINITAB obtenemos que: R-cuad. = 83.5% Esto nos quiere decir que el 83.5% de la muestra, puede ser explicada por las variables ingreso y tamaño. Pero los investigadores sugieren que se calcule el coeficiente r^2 ajustado que refleje tanto el número de variables explicatorias del modelo como el tamaño de la muestra. De MINITAB obtenemos el R-cuad(ajustado) = 81.6% ANALISIS RESIDUAL EN REGRESION MULTIPLE 1. RESIDUOS ESTANDARIZADOS CONTRA “Y” En esta grafica examinamos el patrón de residuos estandarizados parecen variar para los distintos valores del valor que vamos a predecir. 45 Como en el grafico podemos observar que no hay patrones entonces podemos concluir que para el modelo de recesión múltiple es apropiado para predecir el gasto de la familia. 2. RESIDUOS ESTANDARIZADOS CONTRA X1 46 3. RESIDUOS ESTANDARIZADOS CONTRA X2 PRUEBA DE IMPORTANCIA DE LA RELACION ENTRE LA VARIABLE DEPENDIENTE Y LAS VARIABLES EXPLICATIVAS PRUEBA DE PORCIONES DEL MODELO DE REGRESION MULTIPLE El objetivo consiste en emplear solamente aquellas variables que son de utilidad en la predicción del valor de una variable dependiente. Emplearemos el estadístico de prueba F parcial. Explica la determinación de la contribución a la suma de cuadrados de regresión hecha por cada variable independiente después de que todas ellas han sido incluidas en el modelo. Antes de ver si las variables influyen o no, recordaremos toda la información brindada por el Minitab. Análisis de regresión: GASTO vs. INGRESO; TAMAÑO Análisis de Varianza Fuente Regresión INGRESO TAMAÑO GL 2 1 1 SC Ajust. 13540 13537 1451 47 MC Ajust. 6769.8 13536.8 1450.9 Valor F 43.14 86.27 9.25 Valor p 0.000 0.000 0.007 Error Total 17 19 2668 16207 156.9 CONTRIBUCION DE LA VARIABLE X1 SABIENDO QUE X2 ESTA INCLUIDA SSR(X1/X2) = SSR (X1YX2)-SSR(X2) Análisis de regresión: GASTO vs. INGRESO Análisis de Varianza Fuente Regresión INGRESO Error Total GL 1 1 18 19 SC Ajust. 12089 12089 4118 16207 MC Ajust. 12088.8 12088.8 228.8 Valor F 52.84 52.84 Valor p 0.000 0.000 Resumen del modelo S 15.1262 R-cuad. 74.59% R-cuad. (ajustado) 73.18% R-cuad. (pred) 69.00% Coeficientes Término Constante INGRESO Coef 20.43 1.247 EE del coef. 6.32 0.172 Valor T 3.23 7.27 Valor p 0.005 0.000 VIF 1.00 Ecuación de regresión GASTO = 20.43 + 1.247 INGRESO Ajustes y diagnósticos para observaciones poco comunes Obs 9 15 GASTO 129.00 78.00 Ajuste 131.38 37.88 Resid -2.38 40.12 Resid est. -0.22 2.78 X R Residuo grande R X poco común X A la variable ingreso le asignamos X2. SSR(X2)= 12089 y por consiguiente de la ecuación tenemos: SSR(X1/X2) =SSR (X1YX2)-SSR(X2) SSR(X1/X2) = 13540-12089 SSR(X1/X2) = 1451 48 FUENTE G.L SUMA DE CUADRADO F CUADRADOS MEDIO(VARIANZA) REGRESION 2 13540 6769.8 X1 1 12089 12089 X1/X2 1 1451 1451 ERROR 17 2668 156.94 TOTAL 19 16208 9.2455 La hipótesis nula y la alternativa para probar la contribución de X1 al modelo serian. Ho: la variable x1 no mejora significativamente el modelo ya que se ha incluido la variable x2. H1: la variable x1 mejora signicativamente el modelo ya que se ha incluido la variable x2. 𝑥1 𝑆𝑆𝑅( ) 𝑥2 𝐹= 𝑀𝑆𝐸 𝐹= 1451 = 9.4255 156.94 Puesto que se tienen respectivamente uno y 17 grados de libertad, si se seleccionan con un nivel de significancia de 0.05 podemos observar que el valor critico de 4.35 Como el valor de F calculado es mayor que este valor de F crítico (9.4255 mayor que 4.35), muestra decisión sería rechazar H0. Concluimos que la variable x1 (tamaño) mejora signicativamente el modelo de regresión que ya tiene incluida la variable x2(ingreso). CONTRIBUCION DE LA VARIABLE X2 SABIENDO QUE X1 ESTA INCLUIDA Ahora analizaremos la contribución de x2 y x1 SSR(x2/x1)=SSR(x1yx2)-SSR(x1 49 Análisis de regresión: GASTO vs. TAMAÑO Análisis de Varianza Fuente Regresión TAMAÑO Error Falta de ajuste Error puro Total GL 1 1 18 3 15 19 SC Ajust. 2,8 2,8 16204,4 1526,4 14678,0 16207,2 MC Ajust. 2,811 2,811 900,244 508,796 978,533 Valor F 0,00 0,00 Valor p 0,956 0,956 0,52 0,675 Resumen del modelo S 30,0041 R-cuad. (ajustado) 0,00% R-cuad. 0,02% R-cuad. (pred) 0,00% Coeficientes Término Constante TAMAÑO Coef 60,5 -0,37 EE del coef. 25,1 6,62 Valor T 2,41 -0,06 Valor p 0,027 0,956 FIV 1,00 Ecuación de regresión GASTO = 60,5 - 0,37 TAMAÑO Ajustes y diagnósticos para observaciones poco comunes Obs 5 7 9 GASTO 125,0 52,0 129,0 Ajuste 59,1 58,3 59,4 Resid 65,9 -6,3 69,6 Resid est. 2,26 -0,26 2,40 R X R Residuo grande R X poco común X SSR(X2/X1)= 13540-2.8=13537.2 FUENTE G.L SUMA DE CUADRADO F CUADRADOS MEDIO(VARIANZA) REGRESION 2 13540 6769.8 X1 1 2.8 2.8 X1/X2 1 13537.2 13537.2 ERROR 17 2668 156.94 TOTAL 19 16208 50 86.257 La hipótesis nula y la alternativa para probar la contribución de X1 al modelo serian. Ho: la variable x2 no mejora significativamente el modelo ya que se ha incluido la variable x1. H1: la variable x2 mejora signicativamente el modelo ya que se ha incluido la variable x1. 𝐹= 𝑥2 𝑆𝑆𝑅(𝑥1) 𝑀𝑆𝐸 1353.2 𝐹 = 156.94 = 86.257 Puesto que se tienen respectivamente uno y 17 grados de libertad, si se seleccionan con un nivel de significancia de 0.05 podemos observar que el valor critico de 4.35 Como el valor de F calculado es mayor que este valor de F crítico (86.257 mayor que 4.35), muestra decisión sería rechazar H0. Concluimos que la variable x2 (ingreso) mejora signicativamente el modelo de regresión que ya tiene incluida la variable x1(tamaño). Ejercicio: Con los siguientes datos: 51 Se obtiene la siguiente información: a) Hallar el error estándar múltiple b) Hallar el coeficiente de correlación múltiple, el coeficiente de determinación múltiple y el coeficiente de no determinación. c) Hallar el intervalo de confianza d) Realizar la prueba global a un nivel de significancia de 0.05 e) Realizar la prueba individual a un nivel de significancia de 0.05 Resolución: 25.74 S=√ 2.071 % = A) INTERPRETACIÓN: El 2.071% de la dispersión estará alrededor del plano. 52 B) COEFCIENTE DE DETERMINACIÓN: 𝑅2 = SSR 1577.15 = = 0.98 SSTOTAL 1602.89 INTERPRETACIÓN: El 98% de la variación de la venta puede ser explicado por la variación en las variables tienda, ingreso y automóviles. COEFCIENTE DE CORRELACIÓN 𝑅 =√0.98 = 0.99 COEFCIENTE DE NO DETERMINACIÓN: 1 − 𝑅2 = 0.02 INTERPRETACIÓN: El 2% de la variación de la venta no puede ser explicado por la variación en las variables tienda, ingreso y automóviles. C) Para cada variable 𝑏1 ± 𝑏2 ± 𝑏3 ± 𝑏𝑘 ± 𝑡𝑛−𝑝−1x 𝑆𝑏𝑘 (005;6x 𝑆𝑏1; < -0.008;0006> (005;6x (005;6x 𝑆𝑏2; <0.154;3.041> 𝑆𝑏3; <0.278;0.542> 53 D) PRUEBA GLOBAL: Ho=𝛽1=𝛽2=𝛽3= 0 Ha = No todos los betas son iguales a 0 𝛼 = 0.05 𝐹 G.Ln = 3; G.Ld = 6 R.A = <-∞; 4.737] R.C= <4.737; ∞+> 𝐹𝑘 = 122.54 (𝑇𝐴𝐵𝐿𝐴 𝐷𝐸 𝐴𝑁𝑂𝑉𝐴) Entonces 𝐹𝑘 ∈ 𝑅. 𝐶, por lo tanto acepto Ha y rechazo Ho. F) PRUEBA INDIVIDUAL: Ho =𝛽1 = 0; 𝛽2= 0; 𝛽3= 0 Ha =𝛽1 ≠ 0; 𝛽2 ≠ 0; 𝛽3 ≠ 0 𝛼 = 0.05 t ; G.L =6 54 R.A = [-2.447; 2.447] R.C = <-∞; −2.447 > U <2.447; ∞+> 𝑡𝑖 = 𝑏𝑖 − 𝛽𝑖 𝑆𝑏𝑖 Entonces las variables de AUTOMOVILES E INGRESOS deben ser tomadas en cuenta para poder hallar la ecuación que se ajuste a los datos. Reemplazando en la fórmula: 𝑡1 = 𝑡2 = 𝑡3 = 𝑏1 −𝛽1 𝑆𝑏1 𝑏2 −𝛽2 𝑆𝑏2 𝑏3 −𝛽3 𝑆𝑏3 = −0.001 0.003 = 1.598 0.59 = 2.71 𝑡2 ∈ 𝑅. ; 𝑡2 ≠ 0 = 0.41 0.054 = 7.59 𝑡3 ∈ 𝑅. ; 𝑡3 ≠ 0 = −0.33 𝑡1 ∈ 𝑅. ; 𝑡1 = 0 55 7 MODELO DE REGRESION CURVILINEO Ejercicio: A partir de los siguientes datos referentes a horas trabajadas en un taller (X), y a unidades producidas (Y), determinar la recta de regresión de Y sobre X, el coeficiente de correlación lineal e interpretarlo. Solución En primer lugar digitamos los datos en minitab como se muestra: 56 Mostrándonos el siguiente reporte: Análisis de regresión: PRODUCCION vs. HORAS; HORAS*HORAS Análisis de Varianza Fuente p Regresión 0,000 HORAS 0,291 HORAS*HORAS 0,160 Error Falta de ajuste 0,284 Error puro Total GL SC Ajust. MC Ajust. Valor F 2 9258,03 4629,02 58,63 1 99,35 99,35 1,26 1 185,50 185,50 2,35 9 6 710,63 576,13 78,96 96,02 2,14 3 11 134,50 9968,67 44,83 Resumen del modelo S 8,88590 R-cuad. 92,87% R-cuad. (ajustado) 91,29% R-cuad. (pred) 87,18% Coeficientes Término Constante HORAS HORAS*HORAS Coef 490 -9,50 0,0901 EE del coef. 300 8,47 0,0588 Valor T 1,63 -1,12 1,53 Valor p 0,137 0,291 0,160 FIV 683,80 683,80 Ecuación de regresión PRODUCCION = 490 - 9,50 HORAS + 0,0901 HORAS*HORAS 57 Valor Ejercicio: La firma terry es un centro especializado es pruebas mediacas ubicado es denver ,colorado .Una de sus fuentes principales de ingreso es un equipo utilizado para medir cantidades elevadas de plomo en la sangre .Las personas que trabajan en talleres automecanicos , las que trabajan en en la industria delown , y los pintores de casas comerciles estan expuestos a cantidades elevadas de plomo , por lo que deben ser sometidos en forma aleatoria a esta prueba .Estas pruebas tienen un costo elevado, por lo que los equipos se entregan a diversos sitios , en toda la regin de denver , conforme los requeridos . Se tiene los datos del costo , preparacion y entrega de 20 entregas realizadas realizar con un nivel de significancia de 0.05 : 1. Prueba de significancia del modelo curvilíneo 2. Prueba de hipótesis para probar el efecto curvilíneo 3. Prueba de hipótesis para probar el efecto lineal Resolución: 58 Prueba de significancia del modelo curvilíneo 1. 𝐻0: 1 = 2 = 0 𝐻1: 1 ≠ 𝛽2 ≠ 0 2. nivel de significancia es 0.05. 3. estadístico a utilizar es F. 4. Se tiene: 𝛼 = 0.05 𝑘=2 𝑛 = 20 59 El valor de (0.05,2,20−2−1) = 3.592 5.Cálculo de 𝐹𝑘 y toma de decisión. Fv Gl Ss Ms F Regresión 2 236.410 118.205 12.46 Error 17 161.313 9.489 total 19 Fk = 118.205 9.489 = 12.46 ∈ a la región crítica entonces se rechaza la hipótesis nula y se acepta la hipótesis alternativa. Se concluye que no existe relación entre las variables. Prueba de hipótesis para probar el efecto lineal 𝐻0: 𝛽1 = 0 (𝑙𝑎 𝑖𝑛𝑐𝑙𝑢𝑠𝑖𝑜𝑛 𝑑𝑒𝑙 𝑒𝑓𝑒𝑐𝑡𝑜 𝑙𝑖𝑛𝑒𝑎𝑙 𝑛𝑜 𝑚𝑒𝑗𝑜𝑟𝑎 𝑑𝑒 𝑓𝑜𝑟𝑚𝑎 𝑠𝑖𝑔𝑛𝑖𝑓𝑖𝑐𝑎𝑡𝑖𝑣o𝑒𝑙 𝑚𝑜𝑑𝑒𝑙𝑜) 𝐻 1: 𝛽1 ≠ 0 (𝑙𝑎 𝑖𝑛𝑐𝑙𝑢𝑠𝑖𝑜𝑛 𝑑𝑒𝑙 𝑒𝑓𝑒𝑐𝑡𝑜 𝑙𝑖𝑛𝑒𝑎𝑙 𝑚𝑒𝑗𝑜𝑟𝑎 𝑑𝑒 𝑓𝑜𝑟𝑚𝑎 𝑠𝑖𝑔𝑛𝑖𝑓𝑖𝑐𝑎𝑡𝑖𝑣𝑎 𝑒𝑙 𝑚𝑜𝑑𝑒𝑙𝑜) 2. nivel de significancia es 0.05. 60 3. estadístico a utilizar es t. 4. Cálculo del valor crítico. Se tiene: 𝛼 = 0.05 𝑘=2 𝑛 = 20 El valor de (0.05,20−2−1) = 2.110 5. Calculo de 𝒕𝒌 y toma de decisión. 𝒕𝒌 = 𝒃𝟏 − β𝟏 −0.295 − 0 = = −1.01 Sb𝟏 0 .293 𝑡𝑘 ∈ a la región de aceptación entonces se acepta la hipótesis nula y se rechaza la hipótesis alternativa, es decir que la inclusión del efecto lineal mejora de forma significativa el modelo curvilíneo. 61 8 PRUEBA CHI CUADRADO Ejercicio: En una empresa 200 hombres de diversos niveles gerenciales, seleccionados al azar, fueron entrevistados con respecto a su interés o preocupación acerca de asuntos ambientales. La respuesta de cada persona se registró en una de tres categorías: interés nulo, algo de interés y gran preocupación. Los resultados fueron: Utilice el nivel de significancia 0.01 para determinar si existe relación entre el nivel directivo o gerencial y el interés en asuntos ambientales. Sin interes Nivel 1 Nivel 2 Nivel 3 Nivel 4 total 15 20 7 28 70 Algo interes 13 19 7 21 60 de Bastante preocupacion 12 21 6 31 70 total 40 60 20 80 200 Planteamos nuestra hipótesis nula y alternativa Ho: las muestras no son dependientes. H1: las muestras son dependientes. Utilizando el software tendremos el cuadro de las frecuencias esperadas y observadas, porque hacerlo manualmente nos demoraría un poco de tiempo, pero como nosotros sabemos manejar el software entonces podemos hacer uso de tal. 62 Como el valor de p está en la zona de aceptación, aceptamos la hipótesis nula y decimos que las muestras no son dependientes. 8.1 Bondad de ajuste Ejercicio: Para comprobar si los operarios encontraban dificultades con una prensa manual de imprimir, se hizo una prueba a cuatro operarios anotando el número de atascos sufridos al introducir el mismo número de hojas, dando lugar a la siguiente tabla: 63 64 En Minitab: 65 8.2 .1 Bondad de ajuste a una poisson con parámetro 66 67 En minitab: 68 8.3 Prueba de Homogeneidad Contraste de homogeneidad Otro caso en que usamos una tabla de contingencia es aquél en que se dispone de una población X clasificada en r subpoblaciones x1, x2,...,xr. En cada una de estas poblaciones se toma una muestra, y los individuos de la misma se clasifican según una variable Y que puede tomar m valores posibles y1, y2.....ym. Sea pij la proporción de individuos que, en la población xi tiene como valor de Y=yj. Un contraste de homogeneidad es cuando se desean contrastar las dos hipótesis siguientes: H0:p1j = p2j = ...... = pmj para todo j; dicho de otro modo, todas las subpoblaciones tienen idéntica distribución para la variable Y. H1: algunas de estas proporciones son diferentes. Dicho de otro modo, la distribución de la variable Y en alguna de estas subpoblaciones es diferente El principal objetivo de realizar este contraste es comprobar que las distribuciones de todas las subpoblaciones son iguales o si hay alguna que difiere. Esto nos resulta práctico para poder combinar los resultados de todas las subpoblaciones, pues es necesario asegurarse de que los datos de las distintas muestras que se pretende agrupar son homogéneos. Ejercicio: . Grupo sanguíneo. Se desea saber si la distribución de los grupos sanguíneos es similar en los individuos de dos poblaciones. Para ello se elige una muestra aleatoria de cada una de ellas, obteniéndose los siguientes datos ¿Qué decisión se debe tomar? Muestra 1 Muestra 2 Total A 90 200 290 B 80 180 260 AB 110 240 350 0 20 30 50 Total 300 650 950 Calculamos las frecuencias esperadas: Tabla 3.5. Frecuencias esperadas A B AB 0 Muestra 1 91.5789 82.105 110.53 15.789 Muestra 2 198.421 177.89 239.47 34.211 Posteriormente calculamos: 2 exp i j ( f ij eij ) 2 = 1,76 eij Los grados de libertad son: (n-1) x (m-1) = 1 x 3 = 3 Mirando en la tabla Chi-cuadrado obtenemos que la probabilidad de obtener un valor 7,81 o mayor con 3 grado de libertad es p = 0,184. Por tanto el valor es no estadísticamente significativo, pues es mayor que 0,01. Aceptamos la hipótesis de homogeneidad de grupos sanguíneos en las dos muestras. 3.1. Interpretación y cálculo del p valor El p-valor se puede interpretar de dos maneras diferentes: La probabilidad de rechazar la hipótesis nula cuando en verdad es cierta. 69 La probabilidad de obtener un valor del estadístico igual o mayor al dado, cuando la hipótesis nula es cierta. Esto significa en el caso de un contraste de independencia: Un valor cercano a p=0, indicaría un valor muy improbable de Chi-cuadrado si la hipótesis nula es cierta; por tanto llevaría a rechazar la hipótesis de independencia Un valor cercano a p=1, indicaría un valor muy probable de Chi-cuadrado si la hipótesis nula es cierta; por tanto no rechazaríamos la hipótesis de independencia Cálculo del p valor: Primero: los grados de libertad, gl= (filas-1) x (columnas-1). Segundo: te sitúas en esos grados de libertad en la tabla (fila). Tercero: buscas el valor de Chi- cuadrado de tu caso en la fila del segundo paso. Cuarto: cuando lo sitúes, el valor de p será el que se indica en la parte superior de esa columna. Por ejemplo, en el caso de grados de libertad = 1 y el valor del test sea 7,88, p=0,005. Nota: Cuanto más alto es el valor de Chi cuadrado, más bajo es p-valor Condiciones de aplicación de Chi- cuadrado Observa que al estudiar el valor de Chi-cuadrado en la tabla de la distribución, obtenemos siempre un valor positivo. Es decir, siempre hacemos un contraste unilateral. Si las frecuencias esperadas en las celdas son muy pequeñas, puesto que en la fórmula ( f ij eij ) 2 2 aparecen dividiendo, se obtendría un valor alto de Chi-cuadrado, aunque las exp eij i j diferencias entre frecuencias observadas y esperadas fuese grande. Por eso, se recomienda que se use una muestra de suficiente tamaño. Estas son dos recomendaciones importantes - Como máximo el 20% de las frecuencias esperadas pueden ser menores que el valor 5. - No debe usarse si hay frecuencias esperadas inferiores a 1. En Minitab: 70 8.3 Prueba de Independencia Contraste de independencia En el ejemplo hemos llevado a cabo un contraste de independencia Chi-cuadrado, que nos permite determinar si existe una relación entre dos variables categóricas. Recordarás que un contraste de hipótesis es un procedimiento estadístico, con una serie de pasos que lleva a la aceptación o rechazo de una hipótesis estadística. Los pasos a realizar en un contraste de hipótesis son los siguientes: 1. Fijar las hipótesis que se quieren contrastar: La hipótesis nula H0 y la hipótesis alternativa H1. Estas hipótesis son complementarias una de otra. 2. Fijar el nivel de significación, o probabilidad máxima de rechazar la hipótesis nula H 0, en caso de que sea cierta. Recordemos que el nivel de significación α es la probabilidad de Error Tipo I (probabilidad de rechazar la hipótesis nula, cuando de hecho es cierta). 3. Elegir un estadístico de contraste, que tenga alguna relación con la hipótesis. Formación a partir del estadístico de una regla de decisión, dividiendo los posibles valores del estadístico en dos regiones: (a) Si el estadístico cae en la región crítica (o de rechazo), se rechaza la hipótesis nula; (b) si el estadístico cae en la región de aceptación, no se puede rechazar la hipótesis nula. 4. Se comprueba el valor del estadístico y se toma la decisión de rechazar o no la hipótesis. En el contraste de independencia, se desea decidir si las dos variables en una tabla de contingencia están o no asociadas. Siguiendo los pasos anteriores, se tendría 1. Fijar las hipótesis que se quieren contrastar. Estas hipótesis son las siguientes: H0: Las variables en filas y columnas de la tabla son independientes H1: Hay asociación entre las filas y columnas de la tabla 2. Fijamos el nivel de significación; lo más usual es elegir un valor α=0,05. Esto quiere decir que la probabilidad máxima que fijamos para el error tipo I (rechazar la hipótesis de independencia cuando sea falsa) es 0,05. 3. Elegir un estadístico de contraste, que tenga alguna relación con la hipótesis. En este caso, elegimos el estadístico Chi cuadrado, 4. 2 exp i j ( f ij eij ) 2 eij (2n1)( m1) , que tiene relación con la hipótesis nula, pues se basa en la comparación de frecuencias observadas y frecuencias esperadas en caso de independencia. Si la hipótesis nula H0 es cierta (hay independencia entre filas y columnas) es de esperar un valor del Chi cuadrado será pequeño y si, por el contrario es falsa, será grande. Formaremos una regla decisión, dividiendo los posibles valores de Chi- cuadrado en dos regiones: 2 Si el valor calculado exp tiene una probabilidad menor que (nivel de significación) rechazamos la hipótesis nula H0 (hay independencia entre filas y columnas), pues el valor obtenido es improbable para una tabla con filas y columnas independientes. En este caso, suponemos que las variables están asociadas. 2 Si el valor calculado exp tiene una probabilidad igual o mayor que (nivel de significación) no podemos rechazar la hipótesis nula H0. En este caso no tomamos ninguna decisión. 71 Nota: Observamos que el rechazo de la hipótesis nula tiene más fuerza que su aceptación, pues nos basamos en una situación muy poco probable: De ser cierta la independencia de las variables es muy poco probable obtener un alto valor de Chi- cuadrado. Por tanto, si obtenemos un alto valor de Chi-cuadrado, rechazamos que la hipótesis sea cierta. Pero un valor pequeño de Chi cuadrado puede ser debido a varias causas: Puede ser que las variables sean independientes; puede ser que estén asociadas, pero la asociación sea muy pequeña; o puede ser que el tamaño de la muestra de datos sea pequeño y no permita ver la asociación. En este caso (cuando no podemos rechazar la hipótesis nula) tendríamos que estudiar mejor los datos para ver por qué se obtiene este valor pequeño de Chi- cuadrado. Ejercicio: . Deporte y bienestar Un investigador quiere estudiar si hay asociación entre la práctica deportiva y la sensación de bienestar. Extrae una muestra aleatoria de 100 sujetos. Los datos aparecen a continuación. Sensación de Bienestar Sí No Total Práctica deportiva Sí no 20 25 10 45 30 70 Total 45 55 100 Contraste la hipótesis de independencia entre bienestar y práctica de deporte (alfa = 0,01). Primero calculamos las frecuencias esperadas en caso de independencia: eij fi . f . j n Tabla 3.4. Frecuencias esperadas Sensación de Práctica deportiva Bienestar Sí No Sí 13,5 31,5 No 16,5 38,5 Posteriormente calculamos el estadístico Chi-cuadrado: 2 exp i j ( f ij eij ) 2 = 3,1296 + 2,5606 + 1,3413 + 1,0974 = 8,13 eij Los grados de libertad son: (n-1) x (m-1) = 1 x 1 = 1; Mirando en la tabla Chi-cuadrado obtenemos que la probabilidad de obtener un valor 8,13 o mayor con 1 grado de libertad es p = 0,004. Por tanto el valor es estadísticamente significativo, pues es menor que 0,01. La decisión que se debe tomar es rechazar la hipótesis de independencia entre bienestar y práctica deportiva. 72 En minitab: 9 Metodos No Parametricos 9.1Prueba del signo Caso muestra pequeña(n<20) Ejercicio: Un banco ofrece préstamos bajos y préstamos grandes. Sus clientes solo podrán adquirir uno de los servicios por día. El banco asegura que pueden escoger cualquier servicio, y aun así obtener más del financiamiento que necesitan durante el primer mes. Se realiza una encuesta para verificar esta afirmación antes de iniciar el mes y al final del mes. La experiencia de los clientes de una muestra aleatoria de 12 clientes es: Nombre Flavio Xiomara Frank Milena Brandon Celia Hermes Amoroso Gregorio Francisco Justin Préstamo Bajo Bajo Grande Bajo Bajo Bajo Bajo Grande Bajo Bajo Bajo 73 Solución: 1. Se ingresan los datos al programa 2. Se hallan las probabilidades binomiales Clic en Calculadora/ distribución de probabilidades/binomial. Aparece la siguiente ventana, en la cual debemos completar los datos del problema: 74 3. Clic en aceptar. Luego, se tiene: 4. Se copia en una siguiente columna las tres primeras probabilidades con tal de que la suma sea menor que 0.025 (pues alfa es 0.05 y la prueba es bilateral). Esto se hace para sumarlas. Clic en Calculadora /suma(c3) /aceptar. 75 5. Se calcula p: Se multiplica la suma por el número de colas (bilateral=2colas). 76 Notamos que: 0.0385724< 0.05 6. Ahora se abre una nueva hoja para colocar los datos. Datos 77 7. Clic en Estadísticas /no paramétrico/prueba de signo para 1 muestra. Y aparece la siguiente ventana: 78 Hacer clic en la variable Datos. Intervalo de confianza: 1-alfa(0.05)=0.95 Mediana 0 No es igual (por ser prueba bilateral) Ejercicio: Una gran cadena de tiendas departa La dirección de una empresa recomendó realizar una capacitación de computación en planta para los gerentes, con el objeto de mejorar su conocimiento, en contabilidad, mantenimiento, producción y otras operaciones. Se eligió al azar una muestra de 15 gerentes. El nivel general de capacidad de cada uno en cuánto a la técnica computacional lo determino un grupo de expertos 79 antes de que principiara el programa. Su capacidad y comprensión se evaluaron como sobresalientes, excelentes, buenas, aceptables o deficientes. Después del programa de entrenamiento de tres meses, el mismo grupo de expertos en computación evaluó de nuevo a cada gerente. Las dos evaluaciones antes y después se indican junto con el signo de la diferencia. El signo + indica mejoría, y el signo - señala que la capacidad computacional declinó después del programa de entrenamiento. NOMBRE José Omar Modesto Miguel Wilson Edwin Pedro Luis Josué Bruno David Washington Steve Rolando Santiago ANTES Bueno Aceptable Excelente Deficiente Excelente Bueno Deficiente Excelente Bueno Deficiente Bueno Aceptable Bueno Bueno Deficiente DESPUES Sobresaliente Excelente Bueno Bueno Excelente Sobresaliente Aceptable Sobresaliente Deficiente Bueno Sobresaliente Excelente Aceptable Sobresaliente Bueno DIFERENCIA + + + 0 + + + + + + + - Se tiene interés en determinar si dicho programa de entrenamiento en planta fue efectivo para mejorar la capacidad de los gerentes en materia de computación. Con un nivel de significancia de 0.10 ¿Tales funcionarios son más aptos después de tomar el programa de capacitación, que antes? Solución: 1) H0 : p = 0.5 (no hay cambio en la capacidad como resultado de la capacitación) 80 Ha: p > 0.5 (se incrementó la capacidad como resultado de la capacitación) 2) α= 0.1 3) prueba binomial NUMERO DE EXITOS 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 PROBABILIDAD DE EXITO 0.000 0.001 0.006 0.022 0.061 0.122 0.183 0.209 0.183 0.122 0.061 0.022 0.006 0.001 0.000 PROBABILIDAD ACUMULADA 1.000 0.999 0.998 0.992 0.970 0.909 0.787 0.604 0.395 0.212 0.090 0.029 0.007 0.001 0.000 4) RA: < 2 – 10 > RC: [10 – 12] 5) Cantidad de signos “+” = 10 Como 10 pertenece a la RC → Rechazo la HO y acepto la Ha. Interpretación: Se incrementó la capacidad como resultado de la capacitación. Prueba de signos : Programa de capacitación Prueba del signo de la mediana = Dif01 N 15 Debajo 4 Igual 1 Arriba 10 0.50000 vs. > 0.50000 P 0.090 81 Ejercicio: Cornwall & Hudson, desea vender solo una marca de reproductor de discos compactos de alta calidad. La lista de equipos reproductores de CD’s se ha reducido a dos marcas: Sony y Pioneer. Para ayudar en la toma de decisión, se reunió a un grupo de 16 expertos en audio. Se hizo la reproducción de un pasaje musical usando componentes Sony (marcados A). Después se reprodujo el mismo pasaje utilizando componentes Pioneer (marcados B). Un signo “+” en la tabla siguiente indica la preferencia de una persona por los componentes Sony, y un signo “-“ señala predilección por Pioneer, y un 0 significa que no hay preferencia. 1 + 2 - 3 + 4 - 5 + 6 + 7 - Experto 8 9 0 - 10 + 11 - 12 + 13 + 14 - 15 + 16 - Realice una prueba de hipótesis al nivel de significancia 0.10 para determinar si hay diferencia en la preferencia entre las dos marcas. Solución: Si p indica la proporción de la población de expertos en audio que favorecen a Sony, se trata de probar los siguientes supuestos: 𝐻0 : 𝑝 = 0.50 𝐻1 : 𝑝 ≠ 0.50 Si no se puede rechazar Ho no tendremos pruebas que indiquen que hay preferencia hacia una marca. Sin embargo, si se puede rechazar Ho, podremos concluir que las preferencias de los expertos en audio son distintas hacia las dos marcas. En este caso, la marca que seleccione la mayor cantidad de expertos en audio será la más preferida. Como podemos observar el experto en audio 8 no expreso su preferencia por lo tanto eliminamos su observación reduciéndose el número de muestra a 15. Con un tamaño de muestra n = 15, las probabilidades de la binomial con p = 0.50 son las que aparecen en la siguiente tabla: 82 Experto 0 1 2 3 4 5 6 7 8 Probabilidad 0.000031 0.000458 0.003204 0.013885 0.041656 0.091644 0.152740 0.196381 0.196381 9 10 11 12 13 14 15 0.152740 0.091644 0.041656 0.013885 0.003204 0.000458 0.000031 𝛼= 0.10, tendríamos una región de rechazo cuya área aproximada fuera 0.05 en cada extremo de la distribución. Si iniciamos en el extremo inferior de la distribución, vemos que la probabilidad de obtener cero, uno, dos o tres signos positivos es 0.000031 + 0.000458 + 0.003204 + 0.013885 = 0.017578, que es menor que 0.05. En consecuencia, adoptaremos la siguiente regla de rechazo: Rechazar H0 si el número de signos positivos es menor que 4 o mayor que 11. Como se han observado 8 signos positivos, no se rechaza la hipótesis nula. No hay preferencia con respecto a las dos marcas de componentes. Test and CI for One Proportion: datos Test of p = 0.5 vs. p not = 0.5 Event = 1 Variable X N Sample p 90% CI Z-Value P-Value datos 8 15 0.533333 (0.321456, 0.745211) 0.26 0.796 Using the normal approximation. 83 Usando el Minitab el valor de p es 0.796 el cual es mayor al nivel de significancia 𝛼 = 0.10 por lo tanto no se rechaza la hipótesis nula. No hay preferencia con respecto a las dos marcas de components 9.2 Pruebas de rangos con signos de Wilcoxon Durante el primer mes del primer semestre del 2016 un docente de la Universidad Nacional Mayor de San Marcos tomó una práctica calificada a sus alumnos y decidió posteriormente cambiar de metodología de enseñanza para hacer sus clases más dinámicas, después en 2 meses tomó otra práctica calificada. Se escogieron aleatoriamente 11 alumnos para determinar si su nueva metodología ayudó a los alumnos a entender más las clases y conseguir mejores notas. Las notas de las prácticas calificadas que rindieron los alumnos antes y después de la práctica fueron las siguientes: Alumno A B C D E F G H I J K Producción antes 10.2 9.6 9.2 10.6 9.9 10.2 10.6 10.0 11.2 10.7 10.6 84 Producción después 9.5 9.8 8.8 10.1 10.3 9.3 10.5 10.0 10.6 10.2 9.8 Solución: 1. Ingresar los datos 2. Hallar las diferencias con la calculadora: 85 3. Clic en estadísticas/no paramétrico/wilcoxon 86 Donde se debe colocar: Variable: dif Mediana: 0 No es igual que 87 4. Clic en aceptar y obtenemos: dif 0.1 -0.2 -0.4 0.4 0.5 0.5 0.6 0.7 0.8 0.9 |Dif| 0.1 0.2 0.4 0.4 0.5 0.5 0.6 0.7 0.8 0.9 suma rangos 1 2 3.5 3.5 5.5 5.5 7 8 9 10 55 10 ∗ 11 ∗ 21 𝜎𝑇 = √ = 19.62 6 𝑧= 55 = 2.8 19.62 Conclusión: Se rechaza Ho si Z>1.96, y como 2.8 >1.96 se rechaza la hipótesis nula. Y se concluye que las poblaciones no son idénticas y que las metodologías usadas inciden diferente en las notas de los alumnos. 9.2 SERIES DE TIEMPO MODELO DE TENDECIA LINEAL Ejercicio: 88 A continuación, se presentan los datos del ingreso bruto (en millones de dólares) de las aerolíneas T regionales en YT T*YT T² un periodo de 10 años. Año Ingreso Año Ingreso 1 2428 6 4264 2 2951 7 4738 3 3533 8 4460 4 3618 9 5318 5 3616 10 6915 a. Para esta serie de tiempo, obtenga una ecuación de tendencia lineal. Haga un comentario sobre lo que revela esta ecuación acerca del ingreso bruto de las aerolíneas en los últimos 10 años. b. Pronostique los ingresos brutos en los años 11 y 12. 89 𝑡= 55 = 5.5 10 1 2 3 4 5 6 7 8 9 10 55 2428 2951 3533 3618 3616 4264 4738 4450 5318 6915 41841 𝑌̅ = 𝑏1 = 2428 5902 10599 14472 18080 25584 33166 35680 47862 69150 262923 1 4 9 16 25 36 49 64 81 100 385 41841 = 4184.1 10 262923 − (55)(41841)/10 = 397.5 385 − (55)²/10 𝑏1 = 4184.1 − 397.5(5.5) = 1998 Por tanto: ̅ Yt = 1998 + 397.5t - Es la expresión del componente de tendencia lineal en la serie de tiempo de los ingresos brutos de las aerolíneas regionales. Interpretación: - Como la pendiente es 397.5, esto indica que en los pasados 10 años se tuvo un crecimiento promedio en ingresos brutos de 397.5 millones de dólares por año. Si se supone que la tendencia en ingresos brutos de los últimos 10 años es un buen indicador del futuro, entonces se emplea la ecuación 90 𝑌̅t = 1998 + 397.5t Para proyectar el componente de tendencia de la serie de tiempo. Conclusión: - Por tanto, si emplea únicamente el componente de tendencia se pronostica que, el año próximo, con t=11 los ingresos serán de 6370.60 millones de dólares. - Si t=12 los ingresos serán de 6768.15 millones de dólares. CÁLCULOS EN MINITAB 91 Ejercicio: Las cantidades de dinero gastadas al usar maquinas vendedoras en Estados Unidos, en miles de millones de dólares para los años de 2013 a 2017, se dan a continuación. Determine la ecuación de tendencia lineal para estimar las ventas para el año 2019. Año Código Venta de máquinas vendedoras 2013 1 17.5 2014 2 19.0 2015 3 21.0 2016 4 22.7 2017 5 24.5 92 Resolución Año 2013 2014 2015 2016 2017 Sumatoria Código 1 2 3 4 5 15 Venta de máquinas vendedoras 17.5 19.0 21.0 22.7 24.5 104.7 T*y 17.5 38 63 90.8 122.5 331.8 𝒚𝒊 = 𝒂 + 𝒃 ∗ 𝒕𝒊 𝒂= 𝒃= 𝚺𝐲 𝚺𝐭 −𝒃 𝒏 𝒏 𝐧𝚺𝐭 ∗ 𝐲 − 𝚺𝐲 ∗ 𝚺𝐭 𝒏𝚺𝐭𝟐 − (𝚺𝐭)² Determinación de “a” y ”b” por mínimos cuadrados b= 5(331.8) − (15 ∗ 104.7) = 𝟏. 𝟕𝟕 5 ∗ (55) − (15)² a= 104.7 15 − 1.77 = 𝟏𝟓. 𝟔𝟑 5 5 Obtenemos la ecuación: 𝐲𝐢 = 𝟏𝟓. 𝟔𝟑 + 𝟏. 𝟕𝟕 ∗ 𝐭𝐢 Estimamos las ventas para el año 2019: 𝐲𝐢 = 𝟏𝟓. 𝟔𝟑 + 𝟏. 𝟕𝟕 ∗ 𝟕 = 𝟐𝟖. 𝟎𝟐 93 t² 1 4 9 16 25 55 CÁLCULOS EN MINITAB 94 MODELO DE TENDENCIA EXPONENCIAL Ejercicio: A continuación, se tiene las cantidades de dinero gastadas en publicidad (en miles de millones de dólares) de 2007 a 2017.halle la ecuación: Año Monto 2007 88.1 2008 94.7 2009 102.1 2010 109.8 2011 118.1 2012 125.6 2013 132.6 2014 141.9 2015 150.9 2016 157.9 2017 162.6 Resolución Año 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 2017 Suma total monto 88.1 94.7 102.1 109.8 118.1 125.6 132.6 141.9 150.9 157.9 162.6 1384.3 T 1 2 3 4 5 6 7 8 9 10 11 66 95 Log(y) t² 1,94498 1 1,97635 4 2,00903 9 2,0406 16 2,07225 25 2,09899 36 2,12254 49 2,15198 64 2,17869 81 2,19838 100 2,21112 121 23,0049 506 T*Log(y) 1,945 3,9527 6,0271 8,1624 10,3612 12,5939 14,8578 17,2159 19,6082 21,9838 24,3223 141,03 Determinación de “a” y “b” por mínimos cuadrados b=1.065 a=84.91 Tenemos la ecuación de esta manera: 𝐲𝐢 = 𝟖𝟒. 𝟗𝟏 ∗ (𝟏. 𝟎𝟔𝟓)𝐭𝐢 96 CÁLCULOS EN MINITAB 97 Ejercicio: En el sur de California, los especialistas en el control de la contaminación atmosférica cada hora monitorean las cantidades de ozono, dióxido de carbono y dióxido de nitrógeno en el aire. En los datos de esta serie de tiempo horaria se observa estacionalidad, los niveles de contaminación muestran ciertos patrones según la hora del día. Los niveles de dióxido de nitrógeno en el centro, para las 12 horas, de las 6:00 de la mañana a las 6:00 de la tarde, DEL día 15 de julio fueron los siguientes. Se desea saber a cuanto ascenderán el nivel de dióxido de nitrógeno en el centro para 7:00 de la tarde y a la vez interpretar la ecuación exponencial hallada. 30 de Julio 25 28 35 50 60 60 40 35 30 25 25 20 Resolución CÓDIGO( T) 6:00-7:00 am 1 7:00-8:00 am 2 8:00-9:00 am 3 9:00-10:00 am 4 10:00-11:00 5 am 11:00-12:00 6 am 12:00-1:00 pm 7 1:00-2:00 pm 8 2:00-3:00 pm 9 3:00-4:00 pm 10 4:00-5:00 pm 11 5:00-6:00 pm 12 SUMA TOTAL 78 HORA NIVEL DE DIÓXIDO DE NITRÓGENO 25 28 35 50 LOG(NIV DEL NITRÓGENO) 1.4 1.45 1.54 1.7 1 4 9 16 1.4 2.9 4.62 6.8 60 1.78 25 8.9 60 1.78 36 10.68 40 35 30 25 25 20 443 1.6 1.54 1.48 1.4 1.4 1.3 18.37 49 64 81 100 121 144 650 11.2 12.32 13.32 14 15.4 15.6 117.14 T(LOGY) Ahora hallamos la ecuación a través del método de mínimos cuadrados 98 𝐋𝐎𝐆(𝐘) = 𝟏. 𝟔𝟑 − 𝟎. 𝟎𝟏𝟔𝐓 Para la hora 13 sería: 𝐋𝐎𝐆(𝐘) = 𝟏. 𝟔𝟑 − 𝟎. 𝟎𝟏𝟔 ∗ 𝟏𝟑 = 𝟏. 𝟒𝟐𝟐 Y = 26.42 El nivel de dióxido de nitrógeno para el día 15 de julio de 6:00 -7:00 pm es de 26.42 CÁLCULOS EN MINITAB 99 PROMEDIO MÓVIL Ejercicio: Los datos siguientes corresponden a la utilización de la capacidad de producción (en porcentajes) en los últimos 15 meses. Para esta serie de tiempo calcule promedios móviles de tres semanas. 100 Resolución UTILIZACIÓN (%) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 PROMEDIO MÓVIL PARA 3 MESES 82.5 81.3 81.3 79 76.6 78 78.4 78 78.8 78.7 78.4 80 80.7 80.7 80.8 81.7 80.83 78.96 77.86 77.67 78.13 78.4 78.5 78.63 79.03 79.7 80.47 80.7 101 EjeEjercicio: A continuación, se presentan los gastos mensuales, a lo largo de tres años, en un edificio de seis departamentos en el sur de Florida. Determine los índices estacionales mensuales. Use 6 meses como promedio móvil. Resolución 𝐅(𝐭+𝟏) = 𝛂(𝐘𝐭 ) + (𝟏 − 𝛂)𝐅𝐭 102 AÑO 1 2 3 MESES 1 2 3 4 5 6 1 2 3 4 5 6 1 2 3 4 5 6 GASTOS 170 180 205 230 240 315 180 205 215 245 265 330 195 210 230 280 290 390 PROMEDIO MÓVIL Reemplazando valores en la fórmula: 𝑃1 = 170 + 180 + 205 + 230 + 240 + 315 = 335 6 𝑃2 = 180 + 205 + 230 + 240 + 315 + 180 = 337.5 6 𝑃3 = 205 + 230 + 240 + 315 + 180 + 205 = 343.75 6 103 335 337.5 343.75 346.25 350 356.25 360 363.75 365 368.75 377.5 383.95 398.75 𝑃4 = 230 + 240 + 315 + 180 + 205 + 215 = 346.25 6 𝑃5 = 240 + 315 + 180 + 205 + 215 + 245 = 350 6 𝑃6 = 315 + 180 + 205 + 215 + 245 + 265 = 356.25 6 𝑃7 = 180 + 205 + 215 + 245 + 265 + 330 = 360 6 𝑃8 = 205 + 215 + 245 + 265 + 330 + 195 = 363.75 6 𝑃9 = 215 + 245 + 265 + 330 + 195 + 210 = 365 6 𝑃10 = 245 + 265 + 330 + 195 + 210 + 230 = 368.75 6 𝑃11 = 265 + 330 + 195 + 210 + 230 + 280 = 377.5 6 𝑃12 = 330 + 195 + 210 + 230 + 280 + 290 = 383.95 6 𝑃13 = 195 + 210 + 230 + 280 + 290 + 390 = 398.75 6 104 MODELO DE SUAVIZACIÓN EXPONENCIAL Ejercicio: Considere la siguiente tabla de tiempo. Use para calcular los valores de suavización exponencial de esta serie de tiempo. ¿Cuál es el pronóstico para la semana 7? SEMANA VALOR 1 8 2 12 3 15 4 17 5 16 6 9 Resolución 𝐅(𝐭+𝟏) = 𝛂(𝐘𝐭 ) + (𝟏 − 𝛂)𝐅𝐭 𝐅𝟏 = Y1 = 8 𝐅𝟐 = α(Y1 ) + (1 − α)F1 = 0.2(8) + (1 − 0.2)8 = 8 𝐅𝟑 = α(Y2 ) + (1 − α)F2 = 0.2(12) + (1 − 0.2)8 = 8.8 𝐅𝟒 = α(Y3 ) + (1 − α)F3 = 0.2(15) + (1 − 0.2)8.8 = 10.04 105 𝐅𝟓 = α(Y4 ) + (1 − α)F4 = 0.2(17) + (1 − 0.2)10.04 = 11.43 𝐅𝟔 = α(Y5 ) + (1 − α)F5 = 0.2(16) + (1 − 0.2)11.43 = 12.34 𝐅𝟕 = α(Y6 ) + (1 − α)F6 = 0.2(9) + (1 − 0.2)12.34 = 11.67 Entonces: SEMANA VALOR Ft 1 8 8 2 12 8 3 15 8.8 4 17 10.04 5 16 11.43 6 9 12.34 7 11.67 11.67 106 Ejercicio: El grupo Garden Avenue Seven vende discos compactos de sus presentaciones. En la tabla siguiente se presentan las ventas (en unidades) en los últimos 18 meses. El administrador del grupo desea contar con un método exacto para pronosticar las ventas. a. Emplee el suavizamiento exponencial con α =0.3 y 0.4. ¿Con cuál de estos valores de α obtiene mejores pronósticos? b. Haga un pronóstico mediante la proyección de tendencia. Dé el valor del CME. Resolución Aplicando el modelo de suavizamiento exponencial 𝐅(𝐭+𝟏) = 𝛂(𝐘𝐭 ) + (𝟏 − 𝛂)𝐅𝐭 Con =0.3 107 Cuadrado Valores en la Pronóstico Error de del error serie de con Mes(t) pronóstico del tiempo suavizamiento (Yt-Ft) pronóstico (Yt) (Ft) (Yt-Ft)2 1 293 2 283 293 -10 100 3 322 290 32 1024 4 355 299.6 55.4 3069.16 5 346 316.22 29.78 886.85 6 379 325.15 53.85 2899.82 7 381 341.31 39.69 1575.3 8 431 353.22 77.78 6049.73 9 424 376.55 47.45 2251.5 10 433 390.79 42.21 1781.68 11 470 403.45 66.55 4428.9 12 481 423.42 57.58 3315.46 13 549 440.69 108.31 11731.06 14 544 473.18 70.82 5015.47 15 601 494.43 106.57 11357.16 16 587 526.4 60.6 3672.36 17 644 544.58 99.42 9884.34 18 660 574.41 85.59 7325.65 Total 76368.44 𝐂𝐌𝐄 = 𝟕𝟔𝟑𝟔𝟖. 𝟒𝟒 = 𝟒𝟒𝟗𝟐. 𝟐𝟔 𝟏𝟕 Con 108 Cuadrado Valores en la Pronóstico Error de del error serie de con Mes(t) pronóstico del tiempo suavizamiento (Yt-Ft) pronóstico (Yt) (Ft) (Yt-Ft)2 1 293 2 283 293 -10 100 3 322 290 33 1089 4 355 299.6 52.8 2787.84 5 346 316.22 22.68 514.38 6 379 325.15 46.61 2172.49 7 381 341.31 29.97 898.2 8 431 353.22 67.98 4621.28 9 424 376.55 33.79 1141.76 10 433 390.79 29.27 856.73 11 470 403.45 54.56 2976.79 12 481 423.42 43.74 1913.19 13 549 440.69 94.24 8881.18 14 544 473.18 51.54 2656.37 15 601 494.43 87.92 7729.93 16 587 526.4 38.75 1501.56 17 644 544.58 80.25 6440.06 18 660 574.41 64.15 4115.22 Total 50395.98 𝐂𝐌𝐄 = - 𝟓𝟎𝟑𝟗𝟓. 𝟗𝟖 = 𝟐𝟗𝟔𝟒. 𝟒𝟕 𝟏𝟕 En la primera tabla se muestran los resultados del suavizamiento exponencial con α = 0.3. Como el CME = 4492.26, en este conjunto de datos, al emplear como constante de suavizamiento α=0.3 se 109 obtiene menos exactitud en los pronósticos que si se empleara la constante de suavizamiento α =0.4. Por tanto, se preferirá la constante de suavizamiento α =0.4. Al probar con otros valores de α se puede hallar un “buen” valor para la constante de suavizamiento. Este valor puede emplearse en el modelo de suavizamiento exponencial para obtener pronósticos para el futuro. Un pronóstico para el siguiente mes sería: 𝐅(𝐭+𝟏) = 𝛂(𝐘𝐭 ) + (𝟏 − 𝛂)𝐅𝐭 𝐅𝟏𝟗 = 𝟎. 𝟒(𝟔𝟔𝟎) + (𝟏 − 𝟎. 𝟒)𝟓𝟗𝟓. 𝟖𝟓 = 𝟔𝟐𝟓. 𝟓𝟏 Un valor en ventas de 621.51≈622 unidades El valor del CME sería: 𝐂𝐌𝐄 = 𝟓𝟐𝟐𝟑𝟖. 𝟗𝟔 = 𝟐𝟗𝟎𝟐 𝟏𝟖 Ejercicio: El campeonato de los jugadores de la PGA tuvo lugar, del 23 al 26 de marzo de 2006, en el campo de golf TPC Sawgrass en Ponte Vedra Beach, Florida. A continuación se presentan las puntuaciones obtenidas, en la primera y segunda rondas, por 11 golfistas de una muestra. Use α=0.05 y determine si existe una diferencia significativa entre las puntuaciones obtenidas por los golfistas en la primera y en la segunda rondas. ¿Cuál es su conclusión? 110 Golfista Primera ronda-Segunda ronda Primera ronda- Segunda ronda Fred Couples 69 73 Jhon Daly 70 73 Ernie Els 72 70 Jim Furyk 65 71 Phil Mickeson 70 73 Rocco Mediate 69 74 Nick Price 72 71 Vijay Singh 68 70 Sergio Garcia 70 68 Mike Weir 71 71 Tiger Woods 72 69 Resolución Paso 1: Ho: No existe una diferencia significativa entre las puntuaciones obtenidas por los golfistas en la primera y en la segunda ronda. Ha: Existe una diferencia significativa entre las puntuaciones obtenidas por los golfistas en la primera y en la segunda ronda. Paso 2: Paso 3: 111 Distribución muestral de t para poblaciones idénticas – distribución normal. Paso 4: Definir la región de rechazo y la región de aceptación. Intervalos: R.A = < -1.960; 1.960] R.C = <-∞; -1.960] U <1.960; +∞ > 112 Primera rondaSegunda ronda Primera ronda- Segunda Diferencia Absoluto ronda 69 70 72 65 70 69 72 68 70 71 72 73 73 70 71 73 74 71 70 68 71 69 -4 -3 2 -6 -3 -5 1 -2 4 0 5 4 3 2 6 3 5 1 2 4 0 5 Lugar Rango con signo 6.5 4.5 2.5 10 4.5 8.5 1 2.5 6.5 ___ 8.5 -6.5 -4.5 2.5 -10 -4.5 -8.5 1 -2.5 6.5 ___ 8.5 -18 Cálculos estadísticos: N=11-1=10 𝝁𝑻 = 𝟎 𝒏(𝒏 + 𝟏)(𝟐𝒏 + 𝟏) 𝟏𝟎 ∗ 𝟏𝟏 ∗ 𝟐𝟏 𝝈𝒓𝒔 = √ =√ = 𝟏𝟗. 𝟔𝟐 𝟔 𝟔 𝒁= 𝒕 − 𝝁𝑻 −𝟏𝟖 − 𝟎 = = −𝟎. 𝟗𝟐 𝝈𝑻 𝟏𝟗. 𝟔𝟐 Decisión: - Zk ϵ R.A → Aceptamos la hipótesis nula y rechazamos la hipótesis alternativa. Paso 5:Conclusiones: - Existe una diferencia significativa entre las puntuaciones obtenidas por los golfistas en la primera y en la segunda ronda. 113 Ejercicio: Con objeto de determinar su efecto en el rendimiento de la gasolina en millas por galón en los automóviles de pasajeros, se prueban dos aditivos para gasolina. A continuación, aparecen los resultados de esta prueba en 12 automóviles; en cada automóvil se probaron los dos aditivos. Use α = 0.05 y la prueba de los rangos con signo de Wilcoxon para determinar si existe una diferencia significativa entre estos dos aditivos. Aditivo Aditivo Automóvil 1 2 Automóvil 1 2 1 20.1 18.1 7 16.2 17.2 2 23.6 21.8 8 18.6 15 3 22 22.6 9 21.9 20 4 19.2 17.1 10 24.2 21.2 5 21.2 21.2 11 23.2 22.8 6 24.8 23.8 12 25 23.7 Resolución Paso 1: Ho: El efecto de los aditivos en el rendimiento de la gasolina por galón es el mismo. 114 Ha: El efecto de los aditivos en el rendimiento de la gasolina por galón no es el mismo. Paso 2: Paso 3: Distribución muestral de T– distribución normal. Paso 4: Definir la región de rechazo y la región de aceptación. Intervalos: R.A = < -1.960; 1.960] R.C = <-∞; -1.960] U <1.960; +∞ > 115 Aditivo Automóvil 1 2 Diferencia V.A Lugar Rango con signo 1 20.1 18.1 2.07 2.07 9 9 2 23.6 21.8 1.79 1.79 7 7 3 22 22.6 -0.54 0.54 3 -3 4 19.2 17.1 2.09 2.09 10 10 5 21.2 21.2 0.01 0.01 1 1 6 24.8 23.8 0.97 0.97 4 4 7 16.2 17.2 -1.04 1.04 5 -5 8 18.6 15 3.57 3.57 12 12 9 21.9 20 1.84 1.84 8 8 10 24.2 21.2 3.08 3.08 11 11 11 23.2 22.8 0.43 0.43 2 2 12 25 23.7 1.32 1.32 6 6 T 62 N>10 Cálculos: 𝝁𝑻 = 𝟎 𝒏(𝒏 + 𝟏)(𝟐𝒏 + 𝟏) 𝟏𝟐 ∗ 𝟏𝟑 ∗ 𝟐𝟓 𝝈𝒓𝒔 = √ =√ = 𝟐𝟓. 𝟓 𝟔 𝟔 𝒁= 𝒕 − 𝝁𝑻 𝟔𝟐 − 𝟎 = = 𝟐. 𝟒𝟑 𝝈𝑻 𝟐𝟓. 𝟓 116 Decisión: - Zk ϵ R.C → Rechazamos la hipótesis nula y aceptamos la hipótesis alternativa. Paso 5: Conclusiones: - Entonces el efecto de los aditivos en el rendimiento de la gasolina por galón no es el mismo. PRUEBA DE MANN-WHITNEY- WILCOXON - MUESTRA PEQUEÑA (N<=10) - Ejercicio: A continuación, se presentan los datos muestrales de los salarios iniciales de contadores públicos y planificadores financieros. Los salarios anuales están dados en miles de dólares. Contador Público Planificador financiero Contador Público Planificador financiero 45.2 44 50 48.6 53.8 44.2 45.9 44.7 51.3 48.1 54.5 48.9 53.2 50.9 52 46.8 49.2 46.9 46.9 43.9 117 Use 0.05 como nivel de significancia y pruebe la hipótesis de que no hay diferencia entre los salarios anuales iniciales de los contadores públicos y de los planificadores financieros. Resolución Paso 1: Ho: No hay diferencia entre los salarios anuales iniciales de los contadores públicos y de los planificadores financieros. Ha: Hay diferencia entre los salarios anuales iniciales de los contadores públicos y de los planificadores. Paso 2: Paso 3: TL= (0.05; n1; n2) Paso 4: Cálculos del estadístico: 𝑻𝒖 = 𝒏𝟏 (𝒏𝟏 + 𝒏𝟐 + 𝟏) − 𝑻𝑳 Reemplazando: 𝑻𝑳 = (𝟎. 𝟎𝟓; 𝟏𝟎; 𝟏𝟎) = 𝟕𝟗 𝑻𝒖 = 𝟏𝟎(𝟏𝟎 + 𝟏𝟎 + 𝟏) − 𝟕𝟗 = 𝟏𝟑𝟏 Intervalos: R.A = [79; 131] R.C = <-∞; 79> U <131; +∞ > 118 Contador público Planificador financiero Salario Lugar Salario Lugar 45.2 5 44 2 53.8 19 44.2 3 51.3 16 48.1 10 53.2 18 50.9 15 49.2 13 46.9 8.5 50 14 48.6 11 45.9 6 44.7 4 54.5 20 48.9 12 52 17 46.8 7 46.9 8.5 43.9 1 136.5 ∑𝑹 ∑𝑹 73.5 Decisión: - Como 136.5 ∈ R.C → Rechazo la hipótesis nula y acepto la hipótesis alternativa. Conclusión: - Hay diferencia entre los salarios anuales iniciales de los contadores públicos y de los planificadores financieros. Ejercicio: 119 Dos aditivos de combustible son evaluados para determinar su efecto en el millaje de la gasolina. Se aplicaron sendas pruebas a siete vehículos con el aditivo 1 y a nueve vehículos con el aditivo 2. Los datos siguientes muestran las millas por galón obtenidas con los aditivos entre el rendimiento de la gasolina con los aditivos. Utilice un nivel de significancia de 0.05. ADITIVO 1 17.3 18.4 19.1 16.7 18.2 18.6 17.5 ADITIVO 2 18.7 17.8 21.3 21 22.1 18.7 19.8 20.7 20.2 Resolución Paso 1: Planteamos nuestra hipótesis 𝐻0 : 𝜇1 − 𝜇1 = 0 𝐻1 : 𝜇1 − 𝜇1 ≠ 0 Paso 2: Paso 3: Hallamos nuestro estadístico Prueba MWW Paso 4: Cálculos del estadístico: 120 Prueba de Mann-Whitney e IC: ADITIVO 1, ADITIVO 2 N Mediana ADITIVO 1 7 18.200 ADITIVO 2 9 20.200 La estimación del punto para ETA1-ETA2 es -2.100 95.6 El porcentaje IC para ETA1-ETA2 es (-3.500,-0.499) W = 34.0 Prueba de ETA1 = ETA2 vs. ETA1 no es = ETA2 es significativa en 0.0081 La prueba es significativa en 0.0081 (ajustado por empates) Conclusión: - Como 0.0081 es menor que 0.05 se rechaza la H0 y podemos concluir que los aditivos difieren significativamente con el rendimiento de la gasolina. 121 - MUESTRA GRANDE (N>10) Ejercicio: Business Week publica estadísticas anuales sobre las 1 000 empresas más grandes. El cociente P/E (cociente de rendimiento por acción) de una empresa es el precio actual de las acciones de la empresa dividido entre la ganancia por acción en los últimos 12 meses. En la tabla se presenta el cociente P/E de 10 empresas japonesas y 12 empresas estadounidenses de una muestra. ¿Es significativa la diferencia entre los dos países? Use la prueba de MWW y α =0.01 para dar sus conclusiones. Resolución Paso 1: Planteamos nuestra hipótesis Ho: Las dos poblaciones son idénticas. Ha: Las dos poblaciones no son idénticas. Paso 2: 122 Paso 3: Hallamos nuestro estadístico Prueba MWW Paso 4: Definir la región de rechazo y la región de aceptación. Paso 5: Asignando el rango correspondiente a cada elemento: 123 Calculando la media y la desviación estándar: Considerando la muestra de Japón como 1. 1 1 µT = n1(n1 + n2 + 1) = (10)(10 + 12 + 1) = 115 2 2 σT = √ 1 1 n1n2(n1 + n2 + 1) = √ (10)(12)(10 + 12 + 1) = 15.17 12 12 Calculando el estadístico: 𝐳= T − µT 157 − 115 = = 𝟐. 𝟕𝟕 σT 15.17 Conclusión: - Como el valor de z calculado (2.77) es mayor que el valor critico 1.96, se rechaza la hipótesis nula. Se concluye que si hay diferencia 124 significativa entre los cocientes de rendimiento por acción de las empresas japonesas y norteamericanas. - Ejercicio: Cada año, en diciembre, NRF/BIG Research realiza un estudio sobres el gasto que hacen las personas en las vacaciones de invierno. A continuación, se presentan los datos muestrales sobre el gasto en las vacaciones de invierno en 2004 y 2005 (USA Today, 20 de diciembre de 2005). 2004 2005 623 687 748 638 713 645 726 700 794 662 814 674 752 582 781 805 723 728 674 766 908 737 796 724 Use α = 0.05 y realice una prueba para determinar si en 2005 hubo un incremento en comparación con 2004. ¿Cuál es su conclusión? Resolución Paso 1: Planteamos nuestra hipótesis Ho: El gasto de las personas en las vacaciones de invierno se mantuvo constante entre los años 2004 y 2005 se mantuvo constante. 125 Ha: El gasto de las personas en las vacaciones de invierno tuvo un aumento en el año 2005 con respecto al año 2004. Paso 2: Nivel de significancia: Paso 3: Hallamos nuestro estadístico Distribución normal: Z, T. Paso 4: Definir la región de rechazo y la región de aceptación. Intervalos: R.A = < -∞; -1.645] R.C = <-1.645; +∞ > 126 Paso 5: Cálculos del estadístico. 2004 2005 623 – 2 687 – 8 748 – 16 638 – 3 713 – 10 645 – 4 726 – 13 700 – 9 794 – 20 662 – 5 814 – 23 674 – 6.5 752 – 17 582 – 1 781 – 19 805 – 22 723 – 11 728 – 14 674 – 6.5 766 – 18 908 – 24 737 – 15 796 – 21 724 – 12 ∑ = 119.5 ∑ = 180.5 µ𝑻 = 𝟏 ∗ 𝒏𝟏 (𝒏𝟏 + 𝒏𝟐 + 𝟏) 𝟐 µ𝑇 = 1 ∗ 12(12 + 12 + 1) 2 µ𝑻 = 𝟏𝟓𝟎 𝟏 𝟐 𝑻 = √ ∗ 𝒏𝟏 ∗ 𝒏𝟐 (𝒏𝟏 + 𝒏𝟐 + 𝟏) 1 2 𝑇 = √ ∗ 12 ∗ 12(12 + 12 + 1) 𝑻 = 𝟒𝟐. 𝟒𝟑 127 𝒁= 𝑍= 𝑻 − µ𝑻 𝑻 119.5 − 150 42.43 𝒁 = −𝟎. 𝟕𝟏𝟗 Decisión: - 𝑍𝑘 pertenece a la región crítica, por lo tanto, rechazo la 𝐻𝑜 y acepto la 𝐻𝑎 . Conclusión: - El gasto de las personas en las vacaciones de invierno tuvo un aumento en el año 2005 con respecto al año 2004. PRUEBA DE KRUSKAL WALLS Ejercicio: Los siguientes datos muestrales se obtuvieron de tres poblaciones que no eran necesariamente normales. MUESTRA 1 50 54 59 59 65 MUESTRA 2 48 49 49 52 56 57 MUESTRA 3 39 41 44 47 51 ¿Cuál es su decisión acerca de los datos? Utilice un nivel de riesgo de 0.05. 128 Resolución Paso 1: Ho: Son iguales las distribuciones de las tres muestras. Ha: Todas las distribuciones de las tres muestras no son iguales. Paso 2: Paso 3: Kruskal Walls, X2 Paso 4: Determinamos la zona de aceptación y la de rechazo. 129 Intervalos: R.A = <0;5.991] R.C = <5.991; +∞ > MUESTRA 1 MUESTRA 2 MUESTRA 3 50 8 48 5 39 1 54 11 49 6.5 41 2 59 14.5 49 6.5 44 3 59 14.5 52 10 47 4 65 16 56 12 51 9 57 13 ∑ 𝒓𝟏 64 ∑ 𝒓𝟐 53 ∑ 𝒓𝟑 19 ∑ 𝐫𝟏 𝟐 ∑ 𝐫𝟐 𝟐 ∑ 𝐫𝟑 𝟐 𝟏𝟐 𝐡= + + [ ] − 𝟑(𝐧 + 𝟏) 𝐧(𝐧 + 𝟏) 𝐧𝟏 𝐧𝟐 𝐧𝟑 12 642 532 192 h= [ + + ] − 3(16 + 1) 16(16 + 1) 5 6 5 𝐡 = 𝟖. 𝟗𝟖 Decisión: - H ϵ R.C → Rechazo la hipótesis nula y acepto la hipótesis alternativa. Paso 5: Conclusión: - Las distribuciones de las tres muestras no son iguales. 130 Ejercicio: Para bajar de peso basta con practicar una de las siguientes actividades tres veces por semana durante cuarenta minutos. En la tabla siguiente se muestra la cantidad de calorías que se quema con 40 minutos de cada una de estas actividades. ¿Estos datos indican que exista diferencia en la cantidad de calorías quemadas con cada una de estas actividades? Dé su conclusión. Natación Tenis Andar en bicicleta 408 415 385 380 485 250 425 450 295 400 420 402 427 530 268 Resolución Paso 1: Ho: ρ ≤ 0.5 Ha: ρ > 0.5 Paso 2: Paso 3: Kruskal Walls: H 131 Chi- cuadrado: x2 Paso 4: Definir la región de rechazo y la región de aceptación. Intervalos: R.A = <0;5.991] R.C = <5.991; +∞ > 132 Natación Tenis Andar en bicicleta 408 8 415 9 385 5 380 4 485 14 250 1 425 12 450 13 295 3 400 6 420 10 402 7 427 11 530 15 268 2 41 ∑ 𝒓𝟏 61 ∑ 𝒓𝟐 ∑ 𝒓𝟑 18 ∑ 𝐫𝟏 𝟐 ∑ 𝐫𝟐 𝟐 ∑ 𝐫𝟑 𝟐 𝟏𝟐 𝐡= + + [ ] − 𝟑(𝐧 + 𝟏) 𝐧(𝐧 + 𝟏) 𝐧𝟏 𝐧𝟐 𝐧𝟑 12 412 612 182 h= + + [ ] − 3(15 + 1 15(15 + 1) 5 5 5 𝐡 = 𝟗. 𝟐𝟔 Decisión: - h = 9.26 ϵ a R.C → se rechaza la hipótesis nula y acepta la hipótesis alternativa. Paso 5: Conclusión: - Quiere decir que hay deferencia en la cantidad de calorías quemadas con cada una de las actividades. 133